Introduction to Online Machine Learning: Simplified
Data is being generated in huge quantities everywhere. Twitter generates 12 + TB of data every day, Facebook generates 25 + TB of data everyday and Google generates much more than these quantities everyday. Given that such data is being produced everyday, we need to build tools to handle data with high
1. Volume : High volume of data are stored today for any industry. Conventional models on such huge data are infeasible.
2. Velocity : Data come at high speed and demand quicker learning algorithms.
3. Variety : Different sources of data have different structures. All these data contribute to prediction. A good algorithm can take in such variety of data.
A simple predictive algorithm like Random Forest on about 50 thousand data points and 100 dimensions take 10 minutes to execute on a 12 GB RAM machine. Problems with hundreds of millions of observation is simply impossible to solve using such machines. Hence, we are left with only two options : Use a stronger machine or change the way a predictive algorithm works. First option is not always feasible. In this article we will learn about On-line Learning algorithms which are meant to handle data with such high Volume and Velocity with limited performance machines.
How does On-line learning differ from batch learning algorithms?
If you are a starter in the analytics industry, all you would have probably heard of will fall under batch learning category. Let’s try to visualize how the working of the two differ from each other.
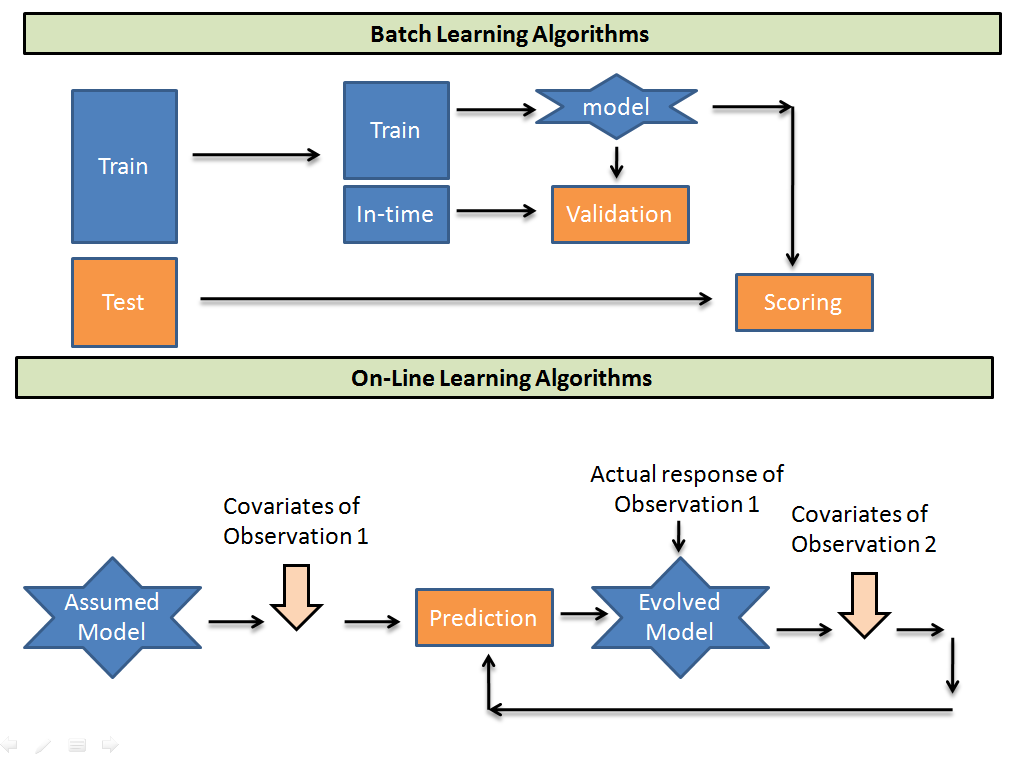
Batch learning algorithms take batches of training data to train a model. Then predicts the test sample using the found relationship. Whereas, On-line learning algorithms take an initial guess model and then picks up one-one observation from the training population and recalibrates the weights on each input parameter. Here are a few trade-offs in using the two algorithms.
- Computationally much faster and more space efficient. In the online model, you are allowed to make exactly one pass on your data, so these algorithms are typically much faster than their batch learning equivalents, since most batch learning algorithms are multi-pass. Also, since you can’t reconsider your previous examples, you typically do not store them for access later in the learning procedure, meaning that you tend to use a smaller memory footprint.
- Usually easier to implement. Since the online model makes one pass over the data, we end up processing one example at a time, sequentially, as they come in from the stream. This usually simplifies the algorithm, if you’re doing so from scratch.
- More difficult to maintain in production. Deploying online algorithms in production typically requires that you have something constantly passing datapoints to your algorithm. If your data changes and your feature selectors are no longer producing useful output, or if there is major network latency between the servers of your feature selectors, or one of those servers goes down, or really, any number of other things, your learner tanks and your output is garbage. Making sure all of this is running ok can be a trial.
- More difficult to evaluate online. In online learning, we can’t hold out a “test” set for evaluation because we’re making no distributional assumptions — if we picked a set to evaluate, we would be assuming that the test set is representative of the data we’re operating on, and that is a distributional assumption. Since, in the most general case, there’s no way to get a representative set that characterizes your data, your only option (again, in the most general case) is to simply look at how well the algorithm has been doing recently.
- Usually more difficult to get “right”. As we saw in the last point, online evaluation of the learner is hard. For similar reasons, it can be very hard to get the algorithm to behave “correctly” on an automatic basis. It can be hard to diagnose whether your algorithm or your infrastructure is misbehaving.
In cases where we deal with huge data, we are left with no choice but to use online learning algorithms. The only other option is to do a batch learning on a smaller sample.
Example Case to understand the concept
We want to predict the probability that it will rain today. We have a panel of 11 people who predict the class : Rain and non-rain on different parameters. We need to design an algorithm to predict the probability. Let us first initialize a few denotions.
i are individual predictors
w(i) is the weight given to the i th predictor
Initial w(i) for i in [1,11] are all 1
We will predict that it will rain today if,
Sum(w(i) for all rain prediction) > Sum(w(i) for all non rain prediction)
Once, we have the actual response of the target variable, we now send a feedback on the weights of all the parameters. In this case we will take a very simple feedback mechanism. For every right prediction, we will keep the weight of the predictor same. While for every wrong prediction, we divide the weight of the predictor by 1.2 (learning rate). With time we expect the model to converge with a right set of parameters.We created a simulation with 1000 predictions done by each of the 11 predictors. Here is how our accuracy curve came out,
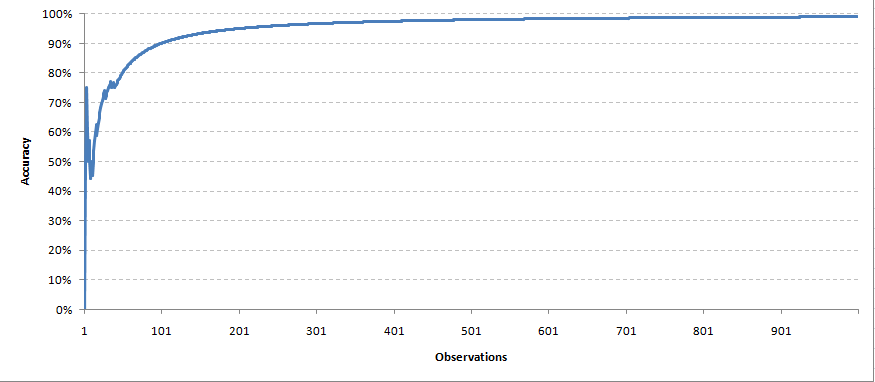
Each observation was taken at a time to re adjust the weights. Same way we will make predictions for the future data points.
End Notes
Online learning algorithms are widely used by E-commerce and social networking industry. It is not only fast but also has the capability to capture any new trend visible in with time. A variety of feedback systems and converging algorithms are presently available which should be selected as per the requirements. In some of the following articles, we will also take up a few practical examples of Online learning algorithm applications.
Did you find the article useful? Have you used online learning algorithms before ? Share with us any such experiences. Do let us know your thoughts about this article in the box below.
If you like what you just read & want to continue your analytics learning, subscribe to our emails, follow us on twitter or like our facebook page.
Tavish Srivastava, co-founder and Chief Strategy Officer of Analytics Vidhya, is an IIT Madras graduate and a passionate data-science professional with 8+ years of diverse experience in markets including the US, India and Singapore, domains including Digital Acquisitions, Customer Servicing and Customer Management, and industry including Retail Banking, Credit Cards and Insurance. He is fascinated by the idea of artificial intelligence inspired by human intelligence and enjoys every discussion, theory or even movie related to this idea.








Hi, I saw your post of planning-late-career-shift-to-analytics and I would like to ask about your opinion about my husband's situation, if possible. My husband is 42 and has a PhD in Mathematics from a very good university in France. He has an academic job in our home country doing research, and prior to that has been doing research in a top university in Germany in Mathematics. His research field is not statistics but during the last two years he has been teaching Master level courses on Statistics and Statistical Analysis and now on Machin Learning. He has some exprience with matlab and R. He is very much talented and intelligent (one can show this in his CV I think) and a very quick learner and able to understand the most complicated level mathematics. We are moving to Calgary-Canada and are trying to find out if he will have any possibilities to work there in Data science field (which we find the most likely field for him). He speaks English and French. I thought maybe you can help me out by telling us if you think in the data science job market in Canada how much chance he will have to get a job. Actually he is kind of person who looks for a 'good' job, which kind of means a job in which he uses his capabilities. I would greatly appreciate if you let me know what you think. Best regards, Sara
Sara, This question is not related to this article specificallt. Can you please post this on our forum to get opinion. Tavish
Interesting article. Any pointers to further reading on online machine learning? (papers, sites, books...)
Hi, This article was very well explained. I have been reading most of your articles and found them to be the best and most comprehensive. I would like to know more about the online algorithms that are used industry wide. A few more real life examples used in the industry would be useful. How well do these algorithms adapt to any change in the environment or external changes. Great job done!!! Keep it going. Thanks & Regards, Partho
This article is good. But can you explain it with some source code?.. Because explaining theory and real life code are different. I made a snippet using basics: clf = linear_model.SGDClassifier() x1 = some_new_data y1 = the_labels clf.partial_fit(x1,y1) x2 = some_newer_data y2 = the_labels clf.partial_fit(x2,y2)