3 Beginner-Friendly Techniques to Extract Features from Image Data using Python
Have you worked with image data before? Perhaps you’ve wanted to build your own object detection model, or simply want to count the number of people walking into a building. The possibilities of working with images using computer vision techniques are endless. There’s a strong belief that when it comes to working with unstructured data, especially image data, deep learning models are the way forward. Deep learning techniques undoubtedly perform extremely well, but is that the only way to work with images? Not all of us have unlimited resources like the big technology behemoths such as Google and Facebook. So how do we do image feature extractionpython? What is the feature extraction in image processing? and image feature extraction python.
We can leverage the power of machine learning! That’s right – we can use simple machine learning models like decision trees or Support Vector Machines (SVM). If we provide the right data and features, these machine learning models can perform adequately and can even be used as a benchmark solution.
So in this beginner-friendly article, we will understand the different ways in which we can generate features from images. You can then use these methods in your favorite machine learning algorithms!
Table of contents
How do Machines Store Images?
Let’s start with the basics. It’s important to understand how we can read and store images on our machines before we look at anything else. Consider this the ‘pd.read_‘ function, but for images.
Example of Machine Stored Images
Let’s understand this with a simple example. Look at the image below:

We have an image of the number 8. Look really closely at the image – you’ll notice that it is made up of small square boxes. These are called pixels.
There is a caveat, however. We see the images as they are – in their visual form. We can easily differentiate the edges and colors to identify what is in the picture. Machines, on the other hand, struggle to do this. They store images in the form of numbers. Have a look at the image below:

Machines store images in the form of a matrix of numbers. The size of this matrix depends on the number of pixels we have in any given image.
Let’s say the dimensions of an image are 180 x 200 or n x m. These dimensions are basically the number of pixels in the image (height x width).
These numbers, or the pixel values, denote the intensity or brightness of the pixel. Smaller numbers (closer to zero) represent black, and larger numbers (closer to 255) denote white. You’ll understand whatever we have learned so far by analyzing the below image.
The dimensions of the below image are 22 x 16, which you can verify by counting the number of pixels:

Source: Applied Machine Learning Course
Example of Machine Stored Colored Images
The example we just discussed is that of a black and white image. What about colored images (which are far more prevalent in the real world)? Do you think colored images also stored in the form of a 2D matrix as well?
A colored image is typically composed of multiple colors and almost all colors can be generated from three primary colors – red, green and blue.
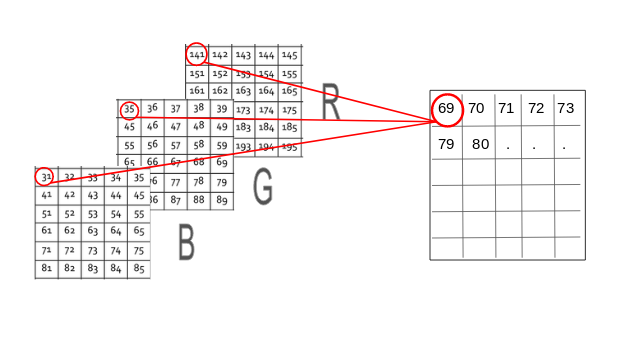
Hence, in the case of a colored image, there are three Matrices (or channels) – Red, Green, and Blue. Each matrix has values between 0-255 representing the intensity of the color for that pixel. Consider the below image to understand this concept:

Source: Applied Machine Learning Course
We have a colored image on the left (as we humans would see it). On the right, we have three matrices for the three color channels – Red, Green, and Blue. The three channels are superimposed to form a colored image.
Note that these are not the original pixel values for the given image as the original matrix would be very large and difficult to visualize. Also, there are various other formats in which the images are stored. RGB is the most popular one and hence I have addressed it here. You can read more about the other popular formats here.
Also Read: 90+ Python Interview Questions to Ace Your Next Job Interview in 2024
Reading Image Data in Python
Let’s put our theoretical knowledge into practice. We’ll fire up Python and load an image to see what the matrix looks like:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from skimage.io import imread, imshow
image = imread('image_8_original.png', as_gray=True)
imshow(image)
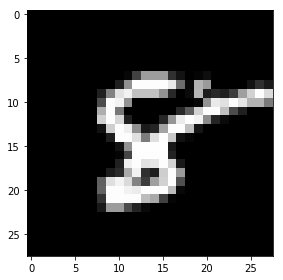
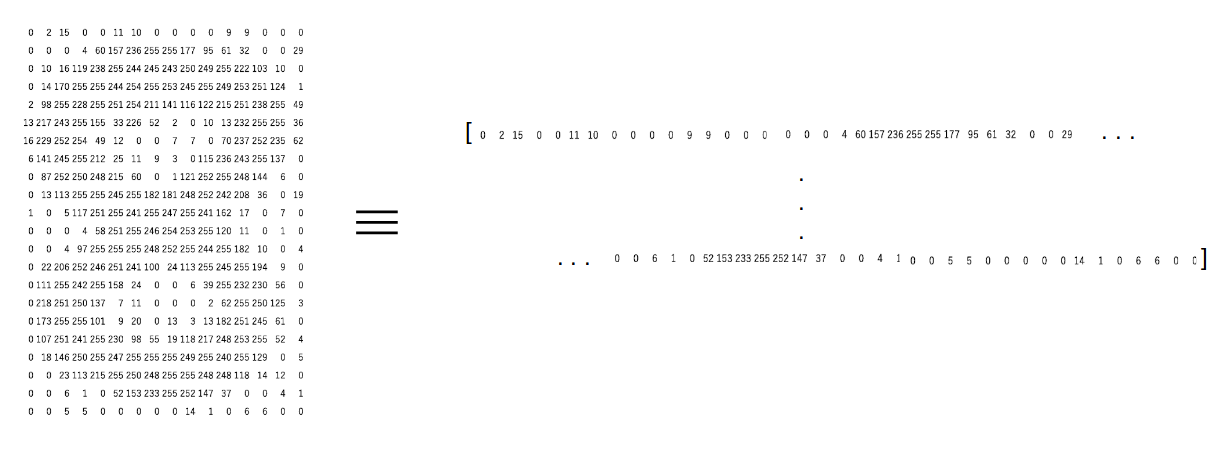
#checking image shape
image.shape, image
(28,28)

The matrix has 784 values and this is a very small part of the complete matrix. Here’s a LIVE coding window for you to run all the above code and see the result without leaving this article! Go ahead and play around with it:
Top 3 Techniques to Extract Features from Image
Let’s now dive into the core idea behind this article and explore various methods of using pixel values as features.
Method #1: Grayscale Pixel Values as Features
The simplest way to create features from an image is to use these raw pixel values as separate features.
Consider the same example for our image above (the number ‘8’) – the dimension of the image is 28 x 28.
Can you guess the number of features for this image? The number of features will be the same as the number of pixels! Hence, that number will be 784.
Now here’s another curious question – how do we arrange these 784 pixels as features? Well, we can simply append every pixel value one after the other to generate a feature vector. This is illustrated in the image below:
Let us take an image in Python and create these features for that image:
image = imread('puppy.jpeg', as_gray=True)
image.shape, imshow(image)
(650, 450

The image shape here is 650 x 450. Hence, the number of features should be 297,000. We can generate this using the reshape function from NumPy where we specify the dimension of the image:
#pixel features
features = np.reshape(image, (660*450))
features.shape, features
(297000,)
array([0.96470588, 0.96470588, 0.96470588, ..., 0.96862745, 0.96470588,
0.96470588])
Here, we have our feature – which is a 1D array of length 297,000. Easy, right? Try your hand at this feature extraction method in the below live coding window:
But here, we only had a single channel or a grayscale image. Can we do the same for a colored image? Let’s find out!
Method #2: Mean Pixel Value of Channels
While reading the image in the previous section, we had set the parameter ‘as_gray = True’. So we only had one channel in the image and we could easily append the pixel values. Let us remove the parameter and load the image again:
image = imread('puppy.jpeg')
image.shape
(660, 450, 3)
This time, the image has a dimension (660, 450, 3), where 3 is the number of channels. We can go ahead and create the features as we did previously. The number of features, in this case, will be 660*450*3 = 891,000.
Alternatively, here is another approach we can use:
Instead of using the pixel values from the three channels separately, we can generate a new matrix that has the mean value of pixels from all three channels.
The image below will give you even more clarity around this idea:
By doing so, the number of features remains the same and we also take into account the pixel values from all three channels of the image. Let us code this out in Python. We will create a new matrix with the same size 660 x 450, where all values are initialized to 0. This matrix will store the mean pixel values for the three channels:
image = imread('puppy.jpeg')
feature_matrix = np.zeros((660,450))
feature_matrix.shape
(660, 450)
We have a 3D matrix of dimension (660 x 450 x 3) where 660 is the height, 450 is the width and 3 is the number of channels. To get the average pixel values, we will use a for loop:
for i in range(0,iimage.shape[0]):
for j in range(0,image.shape[1]):
feature_matrix[i][j] = ((int(image[i,j,0]) + int(image[i,j,1]) + int(image[i,j,2]))/3)
The new matrix will have the same height and width but only 1 channel. Now we can follow the same steps that we did in the previous section. We append the pixel values one after the other to get a 1D array:
(297000,)
Method #3: Extracting Edge Features
Consider that we are given the below image and we need to identify the objects present in it:

You must have recognized the objects in an instant – a dog, a car and a cat. What are the features that you considered while differentiating each of these images? The shape could be one important factor, followed by color, or size. What if the machine could also identify the shape as we do?
A similar idea is to extract edges as features and use that as the input for the model. I want you to think about this for a moment – how can we identify edges in an image? Edge is basically where there is a sharp change in color. Look at the below image:
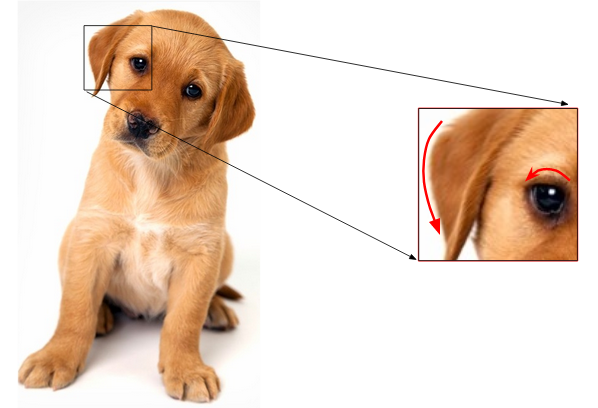
I have highlighted two edges here. We could identify the edge because there was a change in color from white to brown (in the right image) and brown to black (in the left). And as we know, an image is represented in the form of numbers. So, we will look for pixels around which there is a drastic change in the pixel values.
Let’s say we have the following matrix for the image:
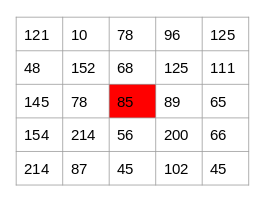
Source: Applied Machine Learning Course
To identify if a pixel is an edge or not, we will simply subtract the values on either side of the pixel. For this example, we have the highlighted value of 85. We will find the difference between the values 89 and 78. Since this difference is not very large, we can say that there is no edge around this pixel.
Now consider the pixel 125 highlighted in the below image:
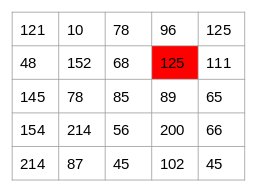
Source: Applied Machine Learning Course
Since the difference between the values on either side of this pixel is large, we can conclude that there is a significant transition at this pixel and hence it is an edge. Now the question is, do we have to do this step manually?
No! There are various kernels that can be used to highlight the edges in an image. The method we just discussed can also be achieved using the Prewitt kernel (in the x-direction). Given below is the Prewitt kernel:

We take the values surrounding the selected pixel and multiply it with the selected kernel (Prewitt kernel). We can then add the resulting values to get a final value. Since we already have -1 in one column and 1 in the other column, adding the values is equivalent to taking the difference.

There are various other kernels and I have mentioned four most popularly used ones below:
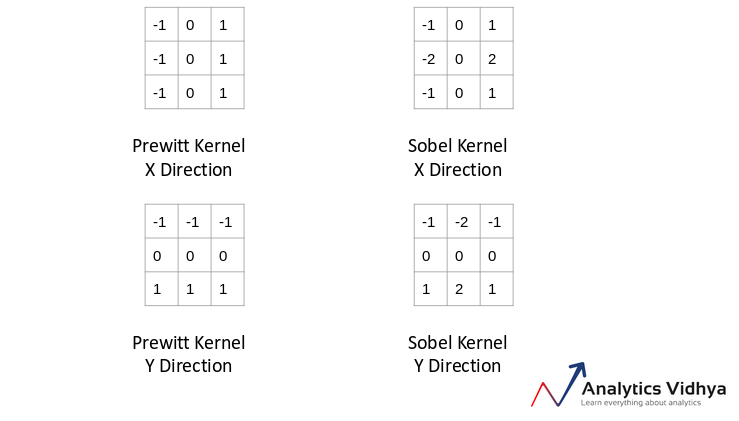
Source: Applied Machine Learning Course
Let’s now go back to the notebook and generate edge features for the same image:
#importing the required libraries
import numpy as np
from skimage.io import imread, imshow
from skimage.filters import prewitt_h,prewitt_v
import matplotlib.pyplot as plt
%matplotlib inline
#reading the image
image = imread('puppy.jpeg',as_gray=True)
#calculating horizontal edges using prewitt kernel
edges_prewitt_horizontal = prewitt_h(image)
#calculating vertical edges using prewitt kernel
edges_prewitt_vertical = prewitt_v(image)
imshow(edges_prewitt_vertical, cmap='gray')

Conclusion
This was a friendly introduction to getting your hands dirty with image feature extraction. This is a very important part of a data scientist’s toolkit given the rapid rise in the number of images being generated these days. So what can you do once you are acquainted with this topic? We will deep dive into the next steps in my next article – dropping soon! So watch this space and if you have any questions or thoughts on this article, let me know in the comments section below.
Frequently Asked Questions
A. In CNNs, feature extraction is about recognizing essential patterns in data, especially images. The network’s layers learn to identify specific features, enabling it to understand complex visual information.
A. Feature extraction in image processing can be done through various methods like mathematical transformations, statistics, or using pre-trained models. For image processing, standard techniques include edge detection, texture analysis, and color-based methods.
A. Feature Selection: It involves choosing a subset of relevant features from the original set, keeping the most informative ones while discarding less important ones.
Feature Extraction: This process transforms the original features into a new set, preserving essential information and highlighting key patterns. It creates a more compact representation of the data.
In short, feature selection picks some features, while feature extraction in image processing generates new ones based on the existing ones.
More on Image Feature Extraction Python
Here is an article on advanced image feature extraction techniques:
Also, here are two comprehensive courses to get you started with machine learning and deep learning:
An avid reader and blogger who loves exploring the endless world of data science and artificial intelligence. Fascinated by the limitless applications of ML and AI; eager to learn and discover the depths of data science.








Thanks u so much for that knowledge sharing.I had understood more about image data.
Very concise and well explained. Thanks
Really glad you found the article useful @HSU.
Great article
Thank you, Agana.
Saying so much while saying nothing. Waste of time The title is miss leading This is not even the beginning of image data. It seems nothing but an ad
Thank you for your comment Elia. Could you name certain techniques that could also be included as a part of this article? That will help me improve the article in the future.
Thank you dear lady, How to use these features for classification/recognition?
Hi, If the size of images is same, the number of features for each image would be equal. You can now use these as inputs for the model.
Very good explained Can u give some links about identification writer of handWriting scripts using deep learning Thank u very much
hi, thanks for this post. Can you tell me how its implement on multiple images? like 1 to 10 number images. can you give me your email id so can I describe my problem and tell you about my image dataset. my email id is [email protected]
I read the article and am so interesting in doing my research work in image data too. But am a slow learner how can you help me come up with an article too. Thanks
well explained .. hats off !!
good article on different image feature extraction techniques
A really interesting article and support me a lot ... But if you can recommend me an article that clearly articulates the 'color features' and 'texture features' please? And under what category are grouped your methods of extracting features (the methods you listed above)? are they categorized under color features or texture features?
Meticulously explained !! Thank you for the article.
Thanks for such nice blog
Very good article, thanks a lot. I am looking forward to see other articles about issues such as texture feature extraction, image classification, segmentation etc.
nice code sir!!! thanks a lott...
Hi Aishwariya, Thanks for the wonderful blog on extracting features of a image using Python. But I am unable to perform the imshow function. It is not returning the image in a graph. I am using the default Python IDLE.
Thank you so much for this article. I have learned about the featured extraction by reading this nice article.
Would you mind sharing how you got the image with all the pixel values as shown at the beginning of the post?
Where can I find the original puppy image? I wish to test the code for my own research.
hi aishwarya dear nice job you have done
Hello I tried your code but when I run the part "Extract Features From HOG Images" I have this error TypeError: hog() got an unexpected keyword argument 'visualise' can you help me please ? Thank you very much
Thank you for giving such a wonderful information and surely it will be helpful in using python in feature extraction and classification.
Awesome, explanation about the Image data.
Thank you so much.The info was really helpful
Great...Really helpful..Thank You