PyTorch Transfer Learning Gu with Examples
Introduction
I was working on a computer vision project last year where we had to build a robust face detection model. The concept behind that is fairly straightforward – it’s the execution part that always sticks in my mind.
Given the size of the dataset we had, building a model from scratch was a real challenge. It was going to be potentially time-consuming and a strain on the computational resources we had. We had to figure out a solution quickly because we were working with a tight deadline.
This is when the powerful concept of transfer learning came to our rescue. It is a really helpful tool to have in your data scientist armoury, especially when you’re working with limited time and computational power.
So in this article, we will learn all about PyTorch transfer learning and how to leverage it on a real-world project using Python. We’ll also discuss the role of pre-trained models in this space and how they’ll change the way you build machine learning pipelines.
Learning Objective
This article is part of my PyTorch series for beginners. I strongly believe PyTorch is one of the best deep learning frameworks right now and will only go from strength to strength in the near future. This is a great time to learn how it works and get onboard. Make sure you check out the previous articles in this series:
- A Beginner-Friendly Guide to PyTorch and How it Works from Scratch
- Build an Image Classification Model using Convolutions Neural Networks (CNNs) in PyTorch
If you are completely new to CNNs, you can learn them comprehensively by enrolling in this free course: Convolutional Neural Networks (CNN) from Scratch
Table of contents
- What is Transfer Learning?
- What are Pre-trained Models and How to Pick the Right Pre-trained Model?
- ImageNet vs. MNIST
- Case Study: Emergency vs Non-Emergency Vehicle Classification
- Solving the Challenge using Convolutional Neural Networks (CNNs)
- Solving the Challenge using Transfer Learning
- Conclusion
- Frequently Asked Questions
What is Transfer Learning?
Let me illustrate the concept of transfer learning using an example. Picture this – you want to learn a topic from a domain you’re completely new to. Pick any domain and any topic – you can think of deep learning and neural networks as well.
What are the different approaches you would take to understand the topic? Off the top of my head:
- Search online for resources
- Read articles and blogs
- Refer to books
- Look out for video tutorials, and so on
All of these will help you get comfortable with the topic. In this situation, you are the only person who is putting in all the effort.
But there’s another approach, which might yield better results in a short amount of time.
You can consult a domain/topic expert who has a solid grasp on the topic you want to learn. This person will transfer his/her knowledge to you. thus expediting your learning process.

The first approach, where you are putting in all the effort alone, is an example of learning from scratch. The second approach is referred to as transfer learning. There is a knowledge transfer happening from an expert in that domain to a person who is new to it.
Yes, the idea behind transfer learning is that straightforward!
Neural Networks and Convolutional Neural Networks (CNNs) are examples of learning from scratch. Both these networks extract features from a given set of images (in case of an image related task) and then classify the images into their respective classes based on these extracted features.
This is where transfer learning and pre-trained models are so useful. Let’s understand a bit about the latter concept in the next section.
What are Pre-trained Models and How to Pick the Right Pre-trained Model?
Pre-trained models are super useful in any deep learning project that you’ll work on. Not all of us have the unlimited computational power of the top tech behemoths. We need to make do with our local machines so pre-trained models are a blessing there.
A pre-trained model, as you might have surmised already, is a model already designed and trained by a certain person or team to solve a specific problem.
Recall that we learn the weights and biases while training models like Neural Network and CNNs. These weights and biases, when multiplied with the image pixels, help to generate features.
Pre-trained models share their learning by passing their weights and biases matrix to a new model. So, whenever we do transfer learning, we will first select the right pre-trained model and then pass its weight and bias matrix to the new model.
There are n number of pre-trained models available out there. We need to decide which will be the best-suited model for our problem. For now, let’s consider that we have three pre-trained networks available – BERT, ULMFiT, and VGG16.
Our task is to classify the images (as we have been doing in the previous articles of this series). So, which of these pre-trained models will you pick? Let me first give you a quick overview of these pre-trained networks which will help us to decide the right pre-trained model.
BERT and ULMFiT are used for language modeling and VGG16 is used for image classification tasks. And if you look at the problem at hand, it is an image classification one. So it stands to reason that we will pick VGG16.
Now, VGG16 can have different weights, i.e. VGG16 trained on ImageNet or VGG16 trained on MNIST:
ImageNet vs. MNIST
Now, to decide the right pre-trained model for our problem, we should explore these ImageNet and MNIST datasets. The ImageNet dataset consists of 1000 classes and a total of 1.2 million images. Some of the classes in this data are animals, cars, shops, dogs, food, instruments, etc.:

MNIST, on the other hand, is trained on handwritten digits. It includes 10 classes from 0 to 9:

We will be working on a project where we need to classify images into emergency and non-emergency vehicles (we will discuss this in more detail in the next section). This dataset includes images of vehicles so a VGG16 model trained on the ImageNet dataset would be more useful for us as it has images of vehicles.
This, in a nutshell, is how we should decide the right pre-trained model based on our problem.
Case Study: Emergency vs Non-Emergency Vehicle Classification
Ideally, we would be using the Identify the Apparels problem for this article. We’ve worked on it in the previous two articles of this series and that would help in comparing our progress.
Unfortunately, this isn’t possible here because VGG16 requires that the images should be of the shape (224,224,3) (the images in the other problem are of shape (28,28)). One way to combat this could have been to resize these (28,28) images to (224,224,3) but this will not make sense intuitively.
Here’s the good part – we’ll be working on a brand new project! Here, our aim is to classify the vehicles as emergency or non-emergency.
This project is also a part of the Computer Vision using Deep Learning course by Analytics Vidhya. To work on more such interesting projects and learn the concepts of computer vision in much more detail, feel free to check out the course.
Step 1: Import Required Libraries
Let’s now start with understanding the problem and visualizing a few examples. You can download the images using this link. First, import the required libraries:
Step 2: Read the .csv File
Next, we will read the .csv file containing the image name and the corresponding label:

There are two columns in the .csv file:
- image_names: It represents the name of all the images in the dataset
- emergency_or_no: It specifies whether that particular image belongs to the emergency or non-emergency class. 0 means that the image is a non-emergency vehicle and 1 represents an emergency vehicle
Step 3: Store Image in Array Format
Next, we will load all the images and store them in an array format:

It took approximately 12 seconds to load these images. There are 1,646 images in our dataset and we have reshaped all of them to (224,224,3) since VGG16 requires all the images in this particular shape.
Step 4: Visalize Images
Let’s now visualize a few images from the dataset:
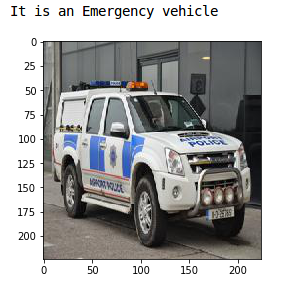
This is a police car and hence has a label of Emergency vehicle. Now we will store the target in a separate variable:
Step 5: Let’s create a validation set to evaluate our model:
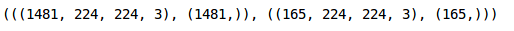
We have 1,481 images in the training set and remaining 165 images in the validation set. We now have to convert the dataset into torch format:

Similarly, we will convert the validation set:

Our data is ready! In the next section, we will build a Convolutional Neural Network (CNN) before we use the pre-trained model to solve this problem.
Solving the Challenge using Convolutional Neural Networks (CNNs)
We are finally at the model building part! Before using transfer learning to solve the problem, let’s use a CNN model and set a benchmark for ourselves.
We will build a very simple CNN architecture with two convolutional layers to extract features from images and a dense layer at the end to classify these features:
Let’s now define the optimizer, learning rate and the loss function for our model and use a GPU to train the model:

This is how the architecture of the model looks like. Finally, we will train the model for 15 epochs. I am setting the batch_size of the model to 128 (you can play around with this):

This will print a summary of the training as well. The training loss is decreasing after each epoch and that’s a good sign. Let’s check the training as well as the validation accuracy:

We got a training accuracy of around 82% which is a good score. Let’s now check the validation accuracy:

The validation accuracy comes out to be 76%. Now that we have a benchmark with us, it’s time to use transfer learning to solve this emergency versus non-emergency vehicle classification problem. Let’s get rolling!
Solving the Challenge using Transfer Learning
I’ve touched on this above and I’ll reiterate it here – we will be using the VGG16 pre-trained model trained on the ImageNet dataset. Let’s look at the steps we will be following to train the model using transfer learning:
- First, we will load the weights of the pre-trained model – VGG16 in our case
- Then we will fine tune the model as per the problem at hand
- Next, we will use these pre-trained weights and extract features for our images
- Finally, we will train the fine tuned model using the extracted features
Step 1: Load the weights of the model
We will now fine tune the model. We will not be training the layers of the VGG16 model and hence let’s freeze the weights of these layers:
Step 2: Train GPU
Since we only have 2 classes to predict and VGG16 is trained on ImageNet which has 1000 classes, we need to update the final layer as per our problem. Since we will be training only the last layer, I have set the requires_grad as True for the last layer. Let’s set the training to GPU:
Step 3: Extract Features
We’ll now use the model and extract features for both the training and validation images. I will set the batch_size as 128 (again, you can increase or decrease this batch_size per your requirement):
Similarly, let’s extract features for our validation images:
Step 5: Convert Data into Torch Format
Next, we will convert these data into torch format:
We also have to define the optimizer and the loss function for our model:
It’s time to train the model. We will train it for 30 epochs with a batch_size set to 128:

Here is a summary of the model. You can see that the loss has decreased and hence we can say that the model is improving. Let’s validate this by looking at the training and validation accuracies:

We got an accuracy of ~ 84% on the training set. Let’s now check the validation accuracy:

The validation accuracy of the model is also similar, i,e, 83%. The training and validation accuracies are almost in sync and hence we can say that the model is generalized. Here is the summary of our results:
| Model | Training Accuracy | Validation Accuracy |
| CNN | 81.57% | 76.26% |
| VGG16 | 83.70% | 83.47% |
We can infer that the accuracies have improved by using the VGG16 pre-trained model as compared to the CNN model. Got to love the art of transfer learning!
Conclusion
This article explored pre-trained models and pytorch transfer learning for image classification. We grasped pre-trained model selection, taking a vehicle image classification case study. Using both CNN and VGG16 models, VGG16’s pre-trained approach yielded superior results. You’ve learned to enhance problem-solving with transfer learning and pre-trained models in PyTorch. Tackle more image classification tasks using this technique for deeper understanding. If you have queries or feedback, share them in the comments.
Ready to escalate your expertise? Explore Analytics Vidhya’s BlackBelt Program, equipping you with data science and AI mastery. Unveil limitless possibilities and pave your path to excellence!
Frequently Asked Questions
A. Transfer learning in PyTorch involves utilizing pre-trained neural network models on one task and adapting them to a different but related task. This approach helps leverage learned features and accelerate model training.
A. Transfer learning involves using a pre-trained model’s architecture and learned weights for a new task. On the other hand, fine-tuning adapts specific layers of the pre-trained model to suit the new task by retraining those layers while keeping others fixed.
A. Yes, ResNet (Residual Network) is a type of transfer learning. It’s a pre-trained convolutional neural network that can be adapted for various image recognition tasks by modifying its final layers.
A. Transfer learning in feature extraction focuses on utilizing the learned features from one task to improve performance on a different but related task. Instead of training a model from scratch, it extracts and fine-tunes specific layers to suit the new task, saving time and resources.
My research interests lies in the field of Machine Learning and Deep Learning. Possess an enthusiasm for learning new skills and technologies.









Pulkit Ji, This is regarding your post on 'Practical Implementation of the Faster R-CNN'. If you could please help me. I am not able to send a comment under that post. It says comments are under moderation. I have two doubts : 1. In the annotations used by you, the 4 variables (xmin,xmax,ymin,ymax) are the left bottom (x,y) coordinates and right top (x,y) coordinates of the bounding box. Using VGG tool, when I make annotations for new dataset, I am getting 4 valus which are top left (x,y) coordinates and width and height of the bounding box. Will I be able to work with these annotations and your code for an entirely new dataset? 2. In the predictions using all the resources that you had made available there, I had an error. Predictions were all very correct but the label was wrong, i.e. the model does rightly identify RBC and WBC but names them the other way. RBC is named as WBC and WBC as RBC. Could you please suggest me how to solve this? With sincere gratitude.
Thanks a lot. model = models.vgg16_bn(pretrained=True) What if we want the pretrained model for VGG16 on MNIST
Hi Mesay, I doubt that keras has the pre-trained weights of MNIST. I will search for it and let you know. You can get the weights by yourself as well. Take the MNIST dataset, create an architecture similar to VGG16 and train it using the MNIST dataset. This will save the weights of VGG16 on MNIST.
Hey, thanks for the great tutorial! I ran into a similar issue in this tutorial as pointed out by SMKJ33 in the second part of the tutorial... There was an error message regarding the format of the tensor: RuntimeError: Expected object of scalar type Long but got scalar type Int for argument #2 'target' in call to _thnn_nll_loss_forward So, in the code, I added the following line # after this line: batch_x, batch_y = train_x[indices], train_y[indices] batch_y = batch_y.long() And then, everything worked. Thanks again!!
How can we predict accuracy for test data set using transfer learning?
Hi PK, Since we do not have actual targets for test set, we can not calculate the accuracy for test set. This is the reason we create a validation set and evaluate model's performance on this validation set.
Your articles are really helpful ..especially for novice learners like me..thank you very much :)