Hands-On Introduction to Web Scraping in Python: A Powerful Way to Extract Data for your Data Science Project
Overview
- Web scraping is a highly effective method to extract data from websites (depending on the website’s regulations)
- Learn how to perform web scraping in Python using the popular BeautifulSoup library
- We will cover different types of data that can be scraped, such as text and images
Introduction
The data we have is too less to build a machine learning model. We need more data!
If this sounds familiar, you’re not alone! It’s the eternal problem of wanting more data to train our machine learning models. We don’t get cleaned and ready-for-use Excel or .csv files in data science projects, right?
So how do we deal with the obstacle of the paucity of data?
One of the most effective and simple ways to do this is through web scraping. I have personally found web scraping a very helpful technique to gather data from multiple websites. Some websites these days also provide APIs for many different types of data you might want to use, such as Tweets or LinkedIn posts.

But there might be occasions when you need to collect data from a website that does not provide a specific API. This is where having the ability to perform web scraping comes in handy. As a data scientist, you can code a simple Python script and extract the data you’re looking for.
So in this article, we will learn the different components of web scraping and then dive straight into Python to see how to perform web scraping using the popular and highly effective BeautifulSoup library.
We have also created a free course for this article – Introduction to Web Scraping using Python. This structured format will help you learn better.
A note of caution here – web scraping is subject to a lot of guidelines and rules. Not every website allows the user to scrape content so there are certain legal restrictions at play. Always ensure you read the website’s terms and conditions on web scraping before you attempt to do it.
Table of contents
3 Popular Tools and Libraries used for Web Scraping in Python
You’ll come across multiple libraries and frameworks in Python for web scraping. Here are three popular ones that do the task with efficiency and aplomb:
BeautifulSoup
- BeautifulSoup is an amazing parsing library in Python that enables the web scraping from HTML and XML documents.
- BeautifulSoup automatically detects encodings and gracefully handles HTML documents even with special characters. We can navigate a parsed document and find what we need which makes it quick and painless to extract the data from the webpages. In this article, we will learn how to build web scrapers using Beautiful Soup in detail
Scrapy
Selenium
- Selenium is another popular tool for automating browsers. It’s primarily used for testing in the industry but is also very handy for web scraping. Check out this amazing article to know more about how web scraping using Selenium works in Python
Components of Web Scraping
Here’s a brilliant illustration of the three main components that make up web scraping:

Let’s understand these components in detail. We’ll do this by scraping hotel details like the name of the hotel and price per room from the goibibo website:

Note: Always follow the robots.txt file of the target website which is also known as the robot exclusion protocol. This tells web robots which pages not to crawl.
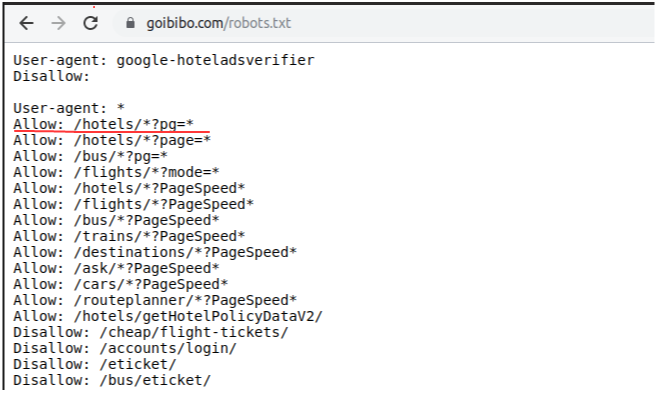
So, looks like we are allowed to scrape the data from our targeted URL. We are good to go and write the script of our web robot. Let’s begin!
Step 1: Crawl
The first step in web scraping is to navigate to the target website and download the source code of the web page. We are going to use the requests library to do this. A couple of other libraries to make requests and download the source code are http.client and urlib2.
Once we have downloaded the source code of the webpage, we need to filter the contents that we need:
Step 2: Parse and Transform
The next step in web scraping is to parse this data into an HTML Parser and for that, we will use the BeautifulSoup library. Now, if you have noticed our target web page, the details of a particular hotel are on a different card like most of the web pages.
So the next step would be to filter this card data from the complete source code. Next, we will select the card and click on the ‘Inspect Element’ option to get the source code of that particular card. You will get something like this:

The class name of all the cards would be the same and we can get a list of those cards by just passing the tag name and attributes like the <class> tag with its name like I’ve shown below:

We have filtered the cards data from the complete source code of the web page and each card here contains the information about a separate hotel. Select only the Hotel Name, perform the Inspect Element step, and do the same with the Room Price:

Now, for each card, we have to find the above Hotel Name which can be extracted from the <p> tag only. This is because there is only one <p> tag for each card and Room Price by <li> tag along with the <class> tag and class name:
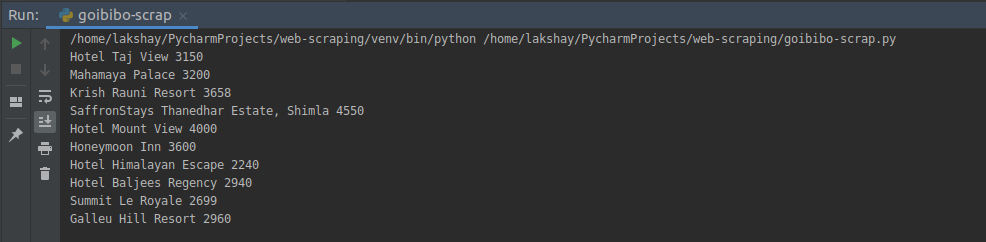
Step 3: Store the Data
The final step is to store the extracted data in the CSV file. Here, for each card, we will extract the Hotel Name and Price and store it in a Python dictionary. We will then finally append it to a list.
Next, let’s go ahead and transform this list to a Pandas data frame as it allows us to convert the data frame into CSV or JSON files:

Congrats! We have successfully created a basic web scraper. I want you to try out these steps and try to get more data like ratings and address of the hotel. Now let’s see how to perform some common tasks like scraping URLs, Email IDs, Images, and Scrape Data on Page Loads.
Scrape URLs and Email IDs from a Web Page
Two of the most common features we try to scrape using web scraping are website URLs and email IDs. I’m sure you’ve worked on projects or challenges where extracting email IDs in bulk was required (see marketing teams!). So let’s see how to scrape these aspects in Python.
Using the Console of the Web Browser
- Let’s say we want to keep track of our Instagram followers and want to know the username of the person who unfollowed our account. First, log in to your Instagram account and click on followers to check the list:

- Scroll down all the way so that we have all the usernames loaded in the background in our browser’s memory
- Right-click on the browser’s window and click ‘Inspect Element’
- In the Console Window, type this command:
urls = $$(‘a’); for (url in urls) console.log ( urls[url].href);

- With just one line of code, we can find out all the URLs present on that particular page:

- Next, save this list at two different time stamps and a simple Python program will let you know the difference between the two. We would be able to know the username of who unfollowed our account!
- There can be multiple ways we can use this hack to simplify our tasks. The main idea is that with a single line of code we can get all the URLs in one go
Using the Chrome Extension Email Extractor
- Email Extractor is a Chrome plugin that captures the Email IDs present on the page that we are currently browsing
- It even allows us to download the list of Email IDs in CSV or Text file:

BeautifulSoup and Regex
The above solutions are efficient only when we want to scrape data from just one page. But what if we want the same steps to be done on multiple webpages?
There are many websites that can do that for us at some price. But here’s the good news – we can also write our own web scraper using Python! Let’s see how to do that in the live coding window below.
Scrape Images in Python
In this section, we will scrape all the images from the same goibibo webpage. The first step would be the same to navigate to the target website and download the source code. Next, we will find all the images using the <img> tag:

From all the image tags, select only the src part. Also, notice that the hotel images are available in jpg format. So we will select only those:

Now that we have a list of image URLs, all we have to do is request the image content and write it in a file. Make sure that you open the file ‘wb’ (write binary) form:

You can also update the initial page URL by page number and request them iteratively to gather data in a large amount.
Scrape Data on Page Load
Let’s have a look at the web page of the steam community Grant Theft Auto V Reviews. You will notice that the complete content of the webpage will not get loaded in one go.
We need to scroll down to load more content on the web page (the age of endless scrolling!). This is an optimization technique called Lazy Loading used by the backend developers of the website.
But the problem for us is when we try to scrape the data from this page, we will only get a limited content of the webpage:
Some websites also create a ‘Load More’ button instead of the endless scrolling idea. This will load more content only when you click that button. The problem of limited content still remains. So let’s see how to scrape these kinds of web pages.
Navigate to the target URL and open the ‘Inspect Element Network’ window. Next, click on the reload button and it will record the network for you like the order of image loads, API requests, POST requests, etc.
Clear the current records and scroll down. You will notice that as you scroll down, the webpage is sending requests for more data:

Scroll further and you will see the pattern in which the website is making requests. Look at the following URLs – only some of the parameter values are changing and you can easily generate these URLs through a simple Python code:

You need to follow the same steps to crawl and store the data by sending requests to each of the pages one by one.
Conclusion
This was a simple and beginner-friendly introduction to web scraping in Python using the powerful BeautifulSoup library. I’ve honestly found web scraping to be super helpful when I’m looking to work on a new project or need information for an existing one.
Note: If you want to learn this in a more structured format, we have a free course where we teach web scrapping BeatifulSoup. You can enroll here – Introduction to Web Scraping using Python
As I mentioned, there are other libraries as well which you can use for performing web scraping. I would love to hear your thoughts on which library you prefer (even if you use R!) and your experience with this topic. Let me know in the comments section below and we’ll connect!
Frequently Asked Questions
1. Install BeautifulSoup or Scrapy using pip.
2. Use the requests library to get webpage HTML.
3. Parse HTML with BeautifulSoup for data extraction.
4. Code to navigate and collect desired info.
1. Beautiful Soup and Scrapy are popular.
2. Beautiful soup for simple tasks
3. Scrapy for complex, structured projects.
1.BeautifulSoup is beginner-friendly.
2. Simple syntax for HTML parsing.
1. APIs provide structured data access.
2. Designed for developers, offering reliability
3. Web scraping depends on HTML, which is prone to breakage.
4. APIs are efficient, delivering specific data without parsing entire pages.
Podcast: Play in new window | Download









This is really good article. Thank you so much.
All the data available on a website can be saved with merely the click of a button. Bots are involved in the scraping of data. While screen scraping is limited to copying whatever the pixels display on screen, bots have the ability to extract underlying HTML codes as well as the data stored in a database in the background.
Nice article .. thanks for sharing!! I have a query! How can we write those images in a particular folder instead of working directory.. could you please advise?
Thanks for sharing an interesting article.