One Hot Encoding vs. Label Encoding using Scikit-Learn
When working with categorical data in machine learning, it is essential to convert these variables into a numerical format that algorithms can understand. Two commonly used techniques for encoding categorical variables are one-hot and label encoding. Choosing the appropriate encoding method can significantly impact the performance of a ML model. In this article, we will explore the differences between one-hot encoding vs label encoding, their use cases, and how to implement them using the powerful Scikit-Learn library in Python.
Table of contents
What is Categorical Encoding?
Typically, any structured dataset includes multiple columns – a combination of numerical as well as categorical variables. A machine can only understand the numbers. It cannot understand the text. That’s essentially the case with Machine Learning algorithms too.
Categorical encoding is the process of converting categorical columns to numerical columns so that a machine learning algorithm understands it. It is a process of converting categories to numbers.
Different Approaches to Categorical Encoding
So, how should we handle categorical variables? As it turns out, there are multiple ways of handling Categorical variables. In this article, I will discuss the two most widely used techniques:
- Label Encoding
- One-Hot Encoding
Checkout our course on Applied Machine Learning – Beginner to Professional to know everything about ML functions!
What is Label Encoding?
Label Encoding is a popular encoding technique for handling categorical variables. A unique integer or alphabetical ordering represents each label.
Let’s see how to implement label encoding in Python using the scikit-learn library and also understand the challenges with label encoding.
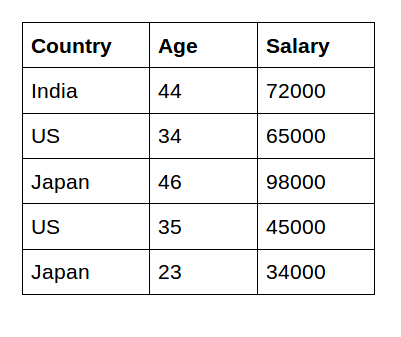
First import the required libraries and dataset:
Output:
Understanding the datatypes of features:
Output:
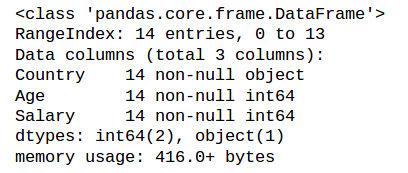
As you can see here, the first column, Country, is the categorical feature as it is represented by the object data type and the rest of them are numerical features as they are represented by int64.
Now, let us implement label encoding in Python:
Output:
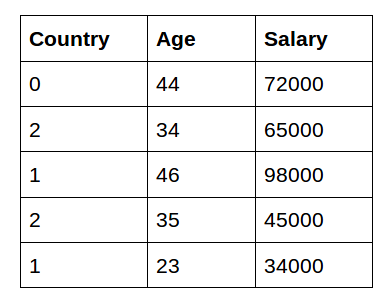
As you can see here, label encoding uses alphabetical ordering. Hence, India has been encoded with 0, the US with 2, and Japan with 1.
Challenges with Label Encoding
In the above scenario, the Country names do not have an order or rank. But, when label encoding is performed, the country names are ranked based on the alphabets. Due to this, there is a very high probability that the model captures the relationship between countries such as India < Japan < the US.
What is One Hot Encoding?
One-Hot Encoding is another popular technique for treating categorical variables. It simply creates additional features based on the number of unique values in the categorical feature. Every unique value in the category will be added as a feature. One-Hot Encoding is the process of creating dummy variables.
In this encoding technique, each category is represented as a one-hot vector. Let’s see how to implement one-hot encoding in Python:
Output:
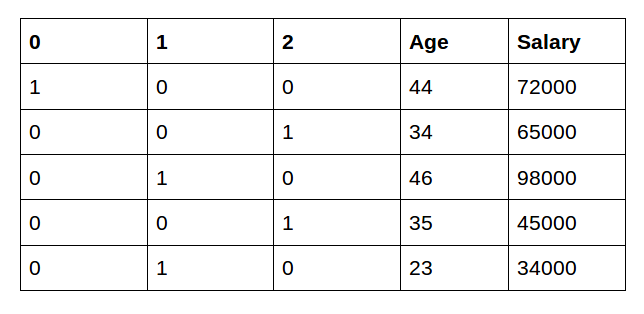
As you can see here, 3 new features are added as the country contains 3 unique values – India, Japan, and the US. In this technique, we solved the problem of ranking as each category is represented by a binary vector.
Can you see any drawbacks with this approach? Think about it before reading on.
Challenges of One-Hot Encoding: Dummy Variable Trap
One-Hot Encoding results in a Dummy Variable Trap as the outcome of one variable can easily be predicted with the help of the remaining variables. Dummy Variable Trap is a scenario in which variables are highly correlated to each other.
The Dummy Variable Trap leads to the problem known as multicollinearity. Multicollinearity occurs where there is a dependency between the independent features. Multicollinearity is a serious issue in machine learning models like Linear Regression and Logistic Regression.
So, in order to overcome the problem of multicollinearity, one of the dummy variables has to be dropped. Here, I will practically demonstrate how the problem of multicollinearity is introduced after carrying out the one-hot encoding.
One of the common ways to check for multicollinearity is the Variance Inflation Factor (VIF):
- VIF=1, Very Less Multicollinearity
- VIF<5, Moderate Multicollinearity
- VIF>5, Extreme Multicollinearity (This is what we have to avoid)
Compute the VIF scores:
Output:
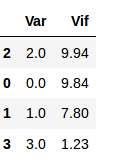
From the output, we can see that the dummy variables which are created using one-hot encoding have VIF above 5. We have a multicollinearity problem.
Now, let us drop one of the dummy variables to solve the multicollinearity issue:
Output:
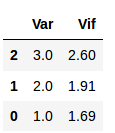
Wow! VIF has decreased. We solved the problem of multicollinearity. Now, the dataset is ready for building the model.
We recommend you to go through Going Deeper into Regression Analysis with Assumptions, Plots & Solutions for understanding the assumptions of linear regression.
One-Hot Encoding vs Label Encoding
| Method | One-Hot Encoding | Label Encoding |
|---|---|---|
| Description | Converts each categorical value into a binary vector, creating new binary columns for each category. | Assigns a unique numerical label to each category, preserving the ordinal relationship if present. |
| Example | Original category: “Red” | Original category: “Red” |
| Encoded: [1, 0, 0] | Encoded: 1 | |
| Example | Original category: “Green” | Original category: “Green” |
| Encoded: [0, 1, 0] | Encoded: 2 | |
| Example | Original category: “Blue” | Original category: “Blue” |
| Encoded: [0, 0, 1] | Encoded: 3 |
When to use a Label Encoding vs. One Hot Encoding
This question generally depends on your dataset and the model which you wish to apply. But still, a few points to note before choosing the right encoding technique for your model:
We apply One-Hot Encoding when:
- The categorical feature is not ordinal (like the countries above)
- The number of categorical features is less so one-hot encoding can be effectively applied
We apply Label Encoding when:
- The categorical feature is ordinal (like Jr. kg, Sr. kg, Primary school, high school)
- The number of categories is quite large as one-hot encoding can lead to high memory consumption
Label Encoding vs One Hot Encoding vs Ordinal Encoding
- Label Encoding: Label encoding assigns a unique numerical label to each category in a categorical variable. It preserves the ordinal relationship between categories if present. For example, “Red” may be encoded as 1, “Green” as 2, and “Blue” as 3.
- One-Hot Encoding: One-hot encoding converts each category in a categorical variable into a binary vector. It creates new binary columns for each category, representing the presence or absence of the category. Each category is mutually exclusive. For example, “Red” may be encoded as [1, 0, 0], “Green” as [0, 1, 0], and “Blue” as [0, 0, 1].
- Ordinal Encoding: Ordinal encoding is similar to label encoding but considers the order or rank of categories. It assigns unique numerical labels to each category, preserving the ordinal relationship between categories. For example, “Cold” may be encoded as 1, “Warm” as 2, and “Hot” as 3.
End Notes
Understanding the differences between one-hot encoding vs label encoding is crucial for effectively handling categorical data in machine learning projects. By mastering these encoding methods and implementing Scikit-Learn, data scientists can enhance their skills and deliver more robust and accurate ML solutions.
One way to master all the data science skills is with our Blackbelt program. It offers comprehensive training in data science, including topics like feature engineering, encoding techniques, and more. Explore the program to know more!
Frequently Asked Questions
A. Label encoding and one-hot encoding are methods for handling categorical variables in machine learning. The choice between them depends on the specific dataset and the ML algorithm you use.
A. Label encoding is simpler and more space-efficient, but it may introduce an arbitrary order to categorical values. One-hot encoding avoids this issue by creating binary columns for each category, but it can lead to high-dimensional data.
A. Target encoding uses the target variable to encode categorical features, while label encoding assigns unique labels to each category. Target encoding can capture target-related information but may introduce data leakage and overfitting risks.
Aspiring Data Scientist with a passion to play and wrangle with data and get insights from it to help the community know the upcoming trends and products for their better future.With an ambition to develop product used by millions which makes their life easier and better.








Hi Alakh, Wanted to ask about the case where variable is not ordinal but number of categories is very large. How to treat those categorical variables.
For decision tree algorithms like random forest, even if the categorical variable is nominal, it doesn't seem to have a problem with being represented as ordinal using label or ordinal encoder. Seems unintuitive. Can someone please explain? H20 infact says that they use enum encoding where the categories are given a numerical value , but the numbers themselves are irrelevant(hence not imposing ordinality on nominal variables). But their classification performance doesn't seem to be much different from sklearn's random forest classifier using ordinal encoder)
Thank you.
alakh ...concept is explained in a simple way.
Hi! Thank you for this very precise article. When we are using decision trees, is it safe to say that one-hot encoding is not recommended? Ali
What if the categorical variables are not ordinal but The number of categories is quite large?
Thank you !!!!!; please teach at Northwestern U