Quick Guide to Solve Overfitting by Cost Complexity Pruning of Decision Trees
Introduction
Decision Tree is one of the most intuitive and effective tools present in a Data Scientist’s toolkit. It has an inverted tree-like structure that was once used only in Decision Analysis but is now a brilliant Machine Learning Algorithm as well, especially when we have a Classification problem on our hands.
These decision trees are well-known for their capability to capture the patterns in the data mining process. But, excess of anything is harmful, right? Decision Trees are infamous as they can cling too much to the data they’re trained on. Hence, our tree gives poor results on deployment because it cannot deal with a new set of values.
But, don’t worry! Just like a skilled mechanic has wrenches of all sizes readily available in his toolbox, a skilled Data Scientist also has his set of techniques to deal with any kind of problem. And that’s what we’ll explore in this article.
Learning Objectives
- Understand the significance of gini index and its role in decision tree algorithms.
- Learn about the importance of pre-pruning techniques in mitigating overfitting in decision trees.
- Gain practical insights through a step-by-step tutorial on implementing decision trees, including concepts such as root node selection and post-pruning.
This article was published as a part of the Data Science Blogathon!
Table of Contents
The Role of Pruning in Decision Trees
Pruning is one of the techniques that is used to overcome our problem of Overfitting. Pruning, in its literal sense, is a practice which involves the selective removal of certain parts of a tree(or plant), such as branches, buds, or roots, to improve the tree’s structure, and promote healthy growth. This is exactly what Pruning does to our Decision Trees as well. It makes it versatile so that it can adapt if we feed any new kind of data to it, thereby fixing the problem of overfitting.
It reduces the size of a Decision Tree which might slightly increase your training error but drastically decrease your testing error, hence making it more adaptable.
Minimal Cost-Complexity Pruning is one of the types of Pruning of Decision Trees.
This algorithm is parameterized by α(≥0) known as the complexity parameter.
The complexity parameter is used to define the cost-complexity measure, Rα(T) of a given tree T: Rα(T)=R(T)+α|T|
where |T| is the number of terminal nodes in T and R(T) is traditionally defined as the total misclassification rate of the terminal nodes.
In its 0.22 version, Scikit-learn introduced this parameter called ccp_alpha (Yes! It’s short for Cost Complexity Pruning- Alpha) to Decision Trees which can be used to perform the same.
Building the Decision Tree in Python
We will use the Iris dataset to fit the Decision Tree on. You can download the dataset here.
First, let us import the basic libraries required and the dataset:
Python Code:
The Dataset looks like this:
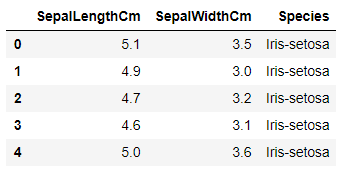
Our aim is to predict the Species of a flower based on its Sepal Length and Width.
We will split the dataset into two parts – Train and Test. We’re doing this so that we can see how our model performs on unseen data as well. We shall use the train_test_split function from sklearn.model_selection to split the dataset.

Now, let’s fit a Decision Tree to the train part and predict on both test and train. We will use DecisionTreeClassifier from sklearn.tree for this purpose.
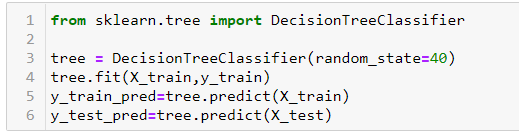
By default, the Decision Tree function doesn’t perform any pruning and allows the tree to grow as much as it can. We get an accuracy score of 0.95 and 0.63 on the train and test part respectively as shown below. We can say that our model is Overfitting i.e. memorizing the train part but is not able to perform equally well on the test part.

DecisionTree in sklearn has a function called cost_complexity_pruning_path, which gives the effective alphas of subtrees during pruning and also the corresponding impurities. In other words, we can use these values of alpha to prune our decision tree:
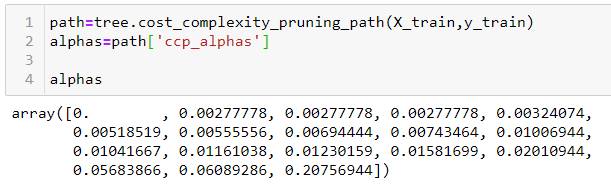
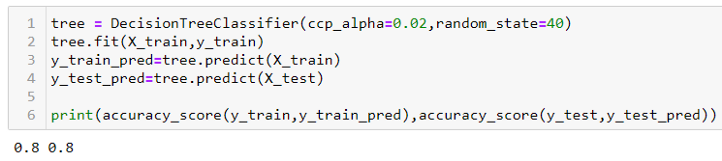
We will set these values of alpha and pass it to the ccp_alpha parameter of our DecisionTreeClassifier. By looping over the alphas array, we will find the accuracy on both Train and Test parts of our dataset.

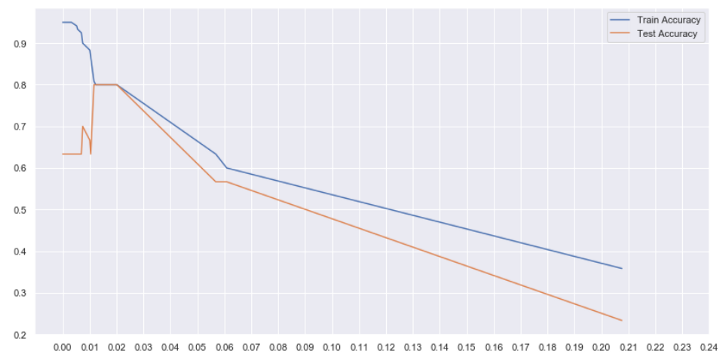
From the above plot, we can see that between alpha=0.01 and 0.02, we get the maximum test accuracy. Although our train accuracy has decreased to 0.8, our model is now more generalized and it will perform better on unseen data.
Conclusion
Minimal Cost-Complexity Pruning emerges as a crucial technique in mitigating overfitting in decision trees. By strategically reducing tree complexity through parameterized pruning, this approach enhances model generalization without compromising predictive accuracy. Through practical implementation in Python, illustrated using the Iris dataset, we demonstrate the effectiveness of pruning in achieving a balanced trade-off between training and testing accuracy. In summary, Minimal Cost-Complexity Pruning equips decision trees with improved adaptability, ensuring robust performance across diverse datasets and real-world applications.
Tree algorithms like Decision Trees are vital components of machine learning models, offering interpretability and efficiency in classification and regression tasks. With advancements such as Minimal Cost-Complexity Pruning, these algorithms become even more powerful tools for data scientists, enabling them to build accurate and reliable models for various applications.
Key Takeaways
- Gini index in decision tree algorithms serves as a measure of impurity for evaluating splits in decision trees, crucial for accurately capturing data patterns.
- Pruning is essential for mitigating overfitting in decision trees by selectively removing tree parts, reducing complexity, and enhancing adaptability to new data without sacrificing predictive accuracy.
- Selecting α in cost-complexity pruning involves finding the optimal balance between model complexity and accuracy.
- Techniques like cross-validation are used to determine the α value that minimizes error and improves generalization.
Frequently Asked Questions
A. Cost complexity pruning theory involves selectively trimming decision trees to prevent overfitting and improve generalization. It aims to find the optimal balance between model complexity and predictive accuracy by penalizing overly complex trees through a cost-complexity measure, typically defined by the total number of leaf nodes and a complexity parameter.
A. Yes, pruning reduces complexity in decision trees by trimming unnecessary branches and nodes. By eliminating redundant splits and reducing the number of leaf nodes, pruning simplifies the tree structure, making it more interpretable and improving its generalization capability.
A. Choosing α in cost-complexity pruning involves finding the value that optimally balances model complexity and predictive accuracy. This can be achieved through techniques such as cross-validation, where different values of α are evaluated on validation data to select the one that minimizes a specified criterion, such as error rate or information gain.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.








