The Hidden Gems of Python – Libraries that make Data Science a Cakewalk
This article was published as a part of the Data Science Blogathon.
Introduction
As the data science community grows, Python is seen dominating the front and center for both development and research. With an active community to back it up and easy open-source packages like Pandas, Tensorflow and Keras, Python has rightfully attracted developers across the globe and established itself as The Language for Data Science.
But, what most beginners miss out on are the lesser-known libraries, their methods, and functions in Python which can make our lives so much easier and our codes so much more efficient.
So here are 10 Data Science libraries that can help you get an edge:
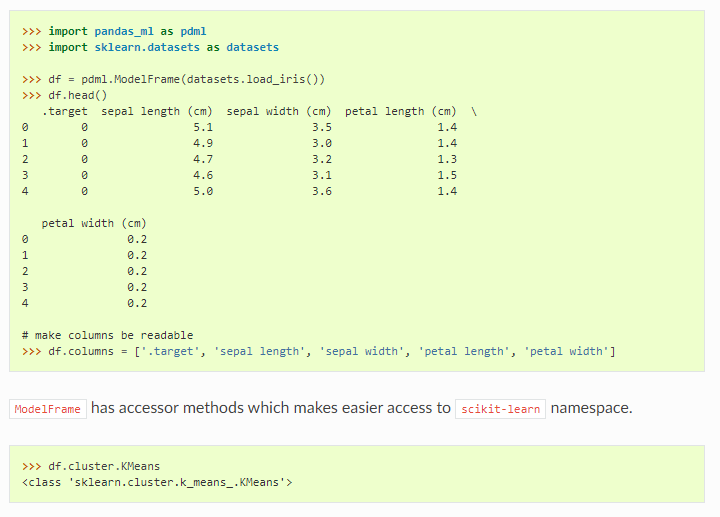
Pandas_ml
Pandas_ml is a library that combines the preprocessing and data manipulation powers of pandas, the reliable machine learning algorithms, and performance metrics of sklearn, the gradient boosting the strength of xgboost, and the visualizations of matplotlib. It basically combines the most reliable libraries of python into one package which is easy to use and will always be handy. So head on to the documentation and start exploring this amazing resource.
Dash
Dash is built on top of Plotly.js, React, and Flask and helps make it easy to use dashboards complete with beautiful plotly graphs and visualizations. It can be used to make interactive ML and Data Science web applications that can be used to perform various functions on data, manipulate the data and analyze results and see different ML models in action deployed on an interactive web platform.
If you love data science and want to show your work in a concise clear manner but just don’t have the time or interest to learn web development, this package is for you. Creating web applications in python has never been easier, check out Dash to make your own Data Science web app now!
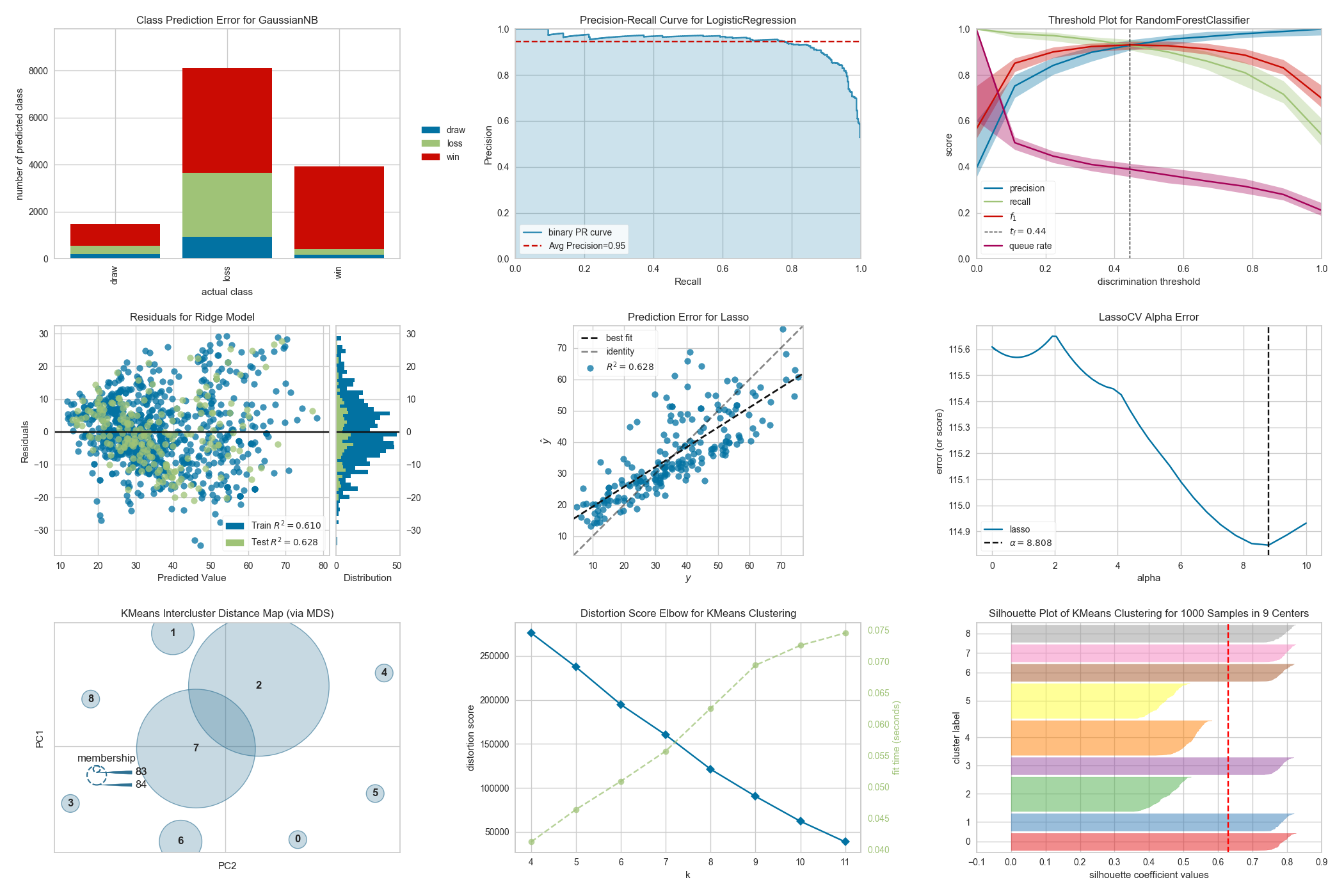
YellowBrick
If you have sat on any machine learning problem, you probably know how difficult it is to select features, tune hyperparameters, select the best models, and understand the performance metrics. Well, your days of worry are over, because YellowBrick is the tool for just that.
This library is built on the foundation of scikit-learn and matplotlib and offers a wide range of visualizations to solve problems such as feature selection on the basis of importance, tuning model’s hyperparameters, and comparing how models perform using various visualizations based on performance metrics. This library helps you interpret your model’s performance and makes it easier for you to improve upon it.
Dabl
Dabl – Data Analysis Baseline Library is another amazing python library that can be used to automate several steps of your Data Science pipeline. Dabl can be used to perform data analysis, automate the known 80% of Data Science which is data preprocessing, data cleaning, and feature engineering.
This library also comprises strong tools to build baseline models for supervised learning problems such as classification or regression and is perfect for beginners to try their hands on Machine Learning. With easy methods such as dabl.clean, and dabl.SimpleClassifier, dabl makes it easier to build a machine learning pipeline and saves both time and resources. So, if you have a deadline hanging over your head or just want to try out ML in your free time, give Dabl a try!
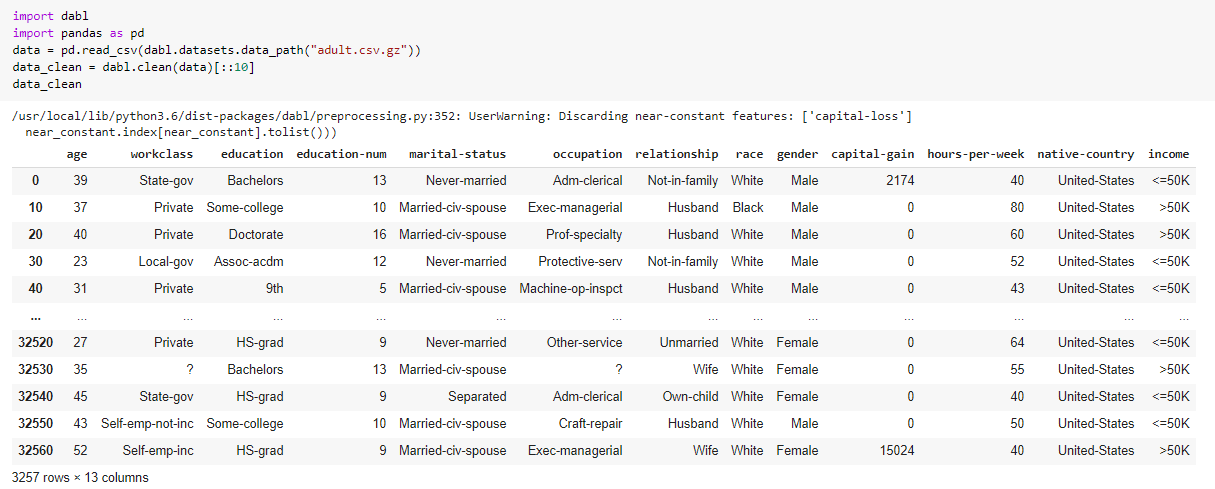
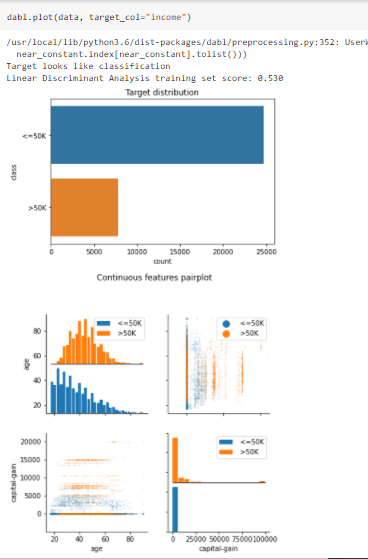
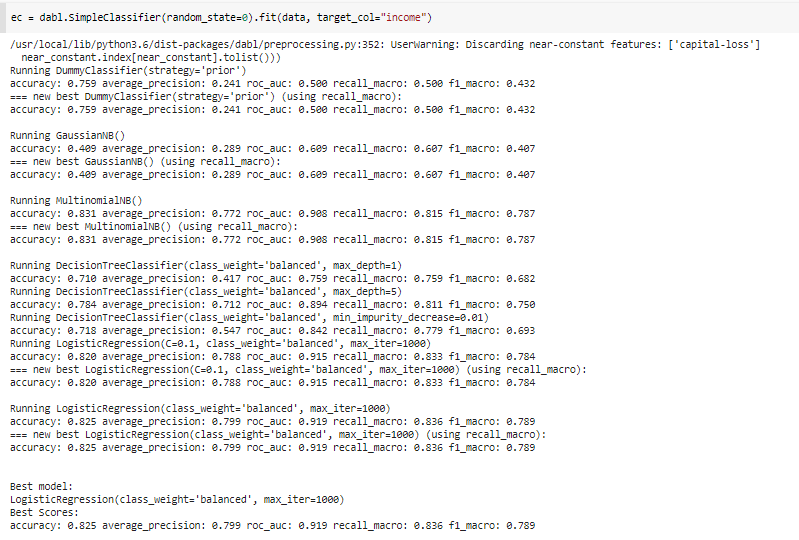
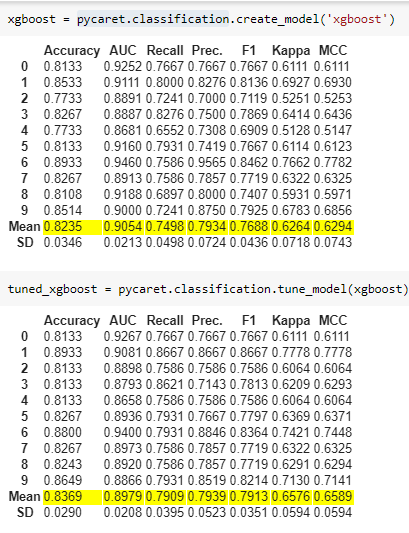
PyCaret
PyCaret is a low-code python wrapper around several data science and machine learning libraries such as scikit-learn and xgboost. It provides an easy to use tool for efficiently experimenting in the data science pipeline and can save you a ton of time! PyCaret can be used to easily code machine learning pipelines for classification and regression problems that are development-ready in no time. PyCaret is The library for “smart rather than hard work” in python. So save yourself some time and a lot of research with PyCaret.
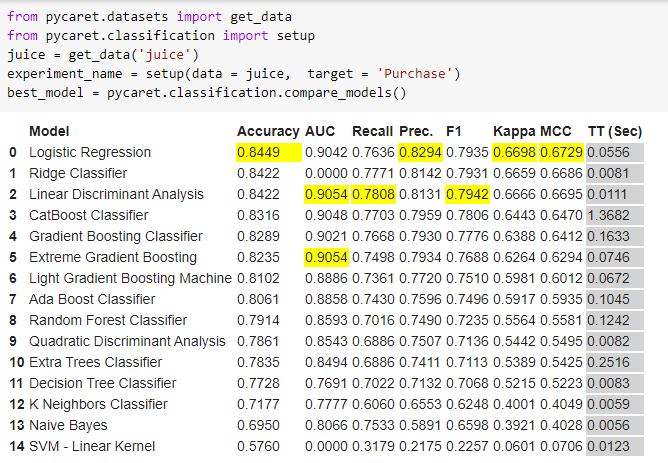
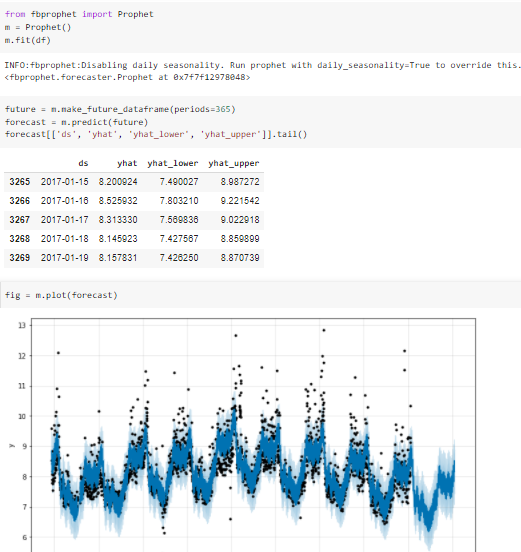
Prophet
Prophet is an open-source time series forecasting library from Facebook. It uses a decomposable regressor model which is based on three models – trend, seasonality, and holidays which makes the prophet an extremely powerful tool for time series problems. It is accurate, fast, and can be tuned for specific problems by giving in seasonality, holidays, changepoints, and the type of growth that the time series represents. Prophet is a quick and reliable way of solving forecasting problems.
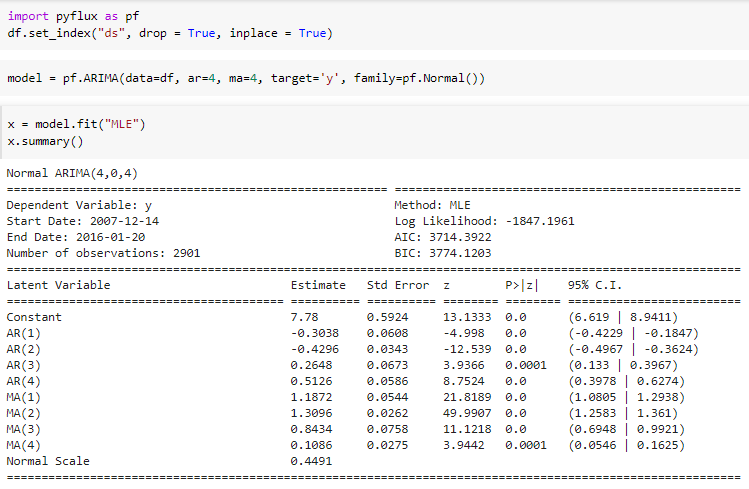
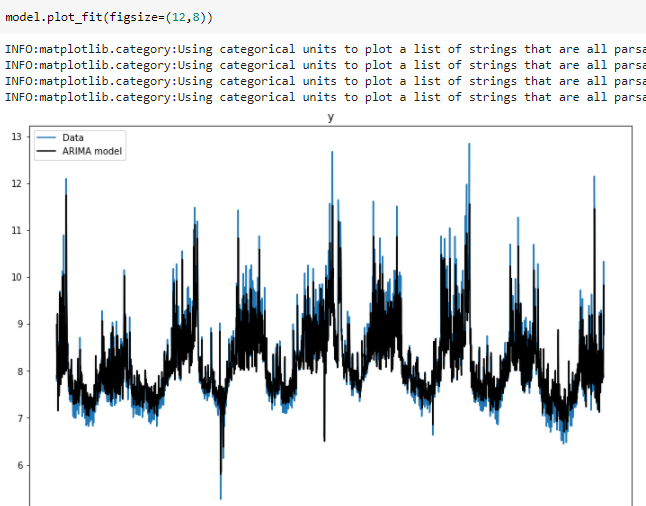
PyFlux
PyFlux is amongst the data science libraries for time series forecasting. Unlike Prophet, this one has several options of different tried and tested time series forecasting models inbuilt for the user to choose from, this one library lets you call different models, tune the parameters and see what suits your data. Pyflux comprises trusted models such as ARIMA, Garch, etc as well as an array of inference options. If you are looking for an easy way to compare different models for your time series forecasting problem, be sure to check out Pyflux.
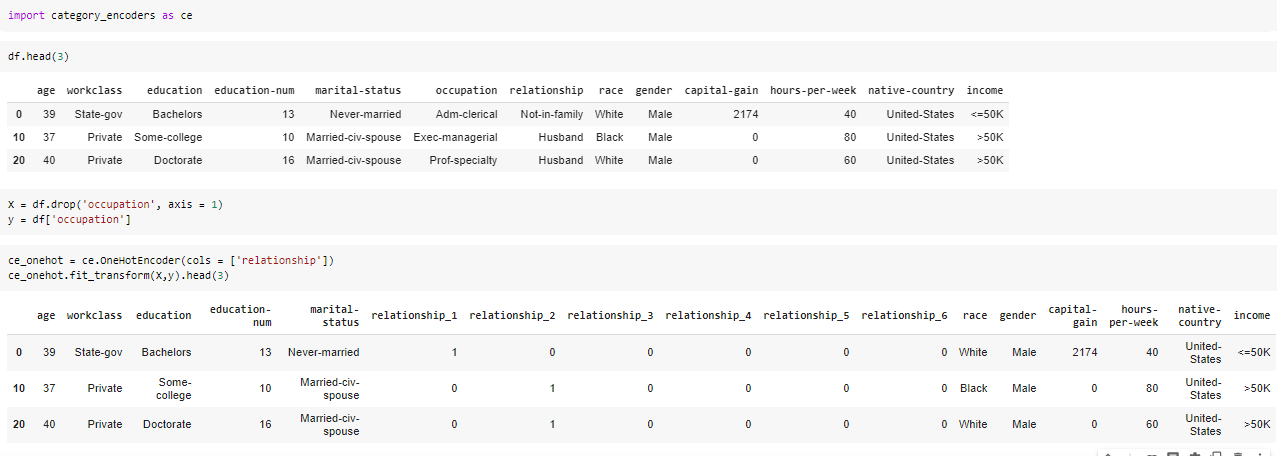
Category-encoders
If you have worked on multi-class classification problems, you probably know how time-consuming category encoding is, here is where category-encoders come into play. It is an efficient easy way to encode categorical variables, this library consists of transformers that can be used inside your data science pipeline and has various methods such as the trusted one-hot encoding. So, the next time you encounter an ML problem with multiple categorical variables, remember to use Category-encoders.
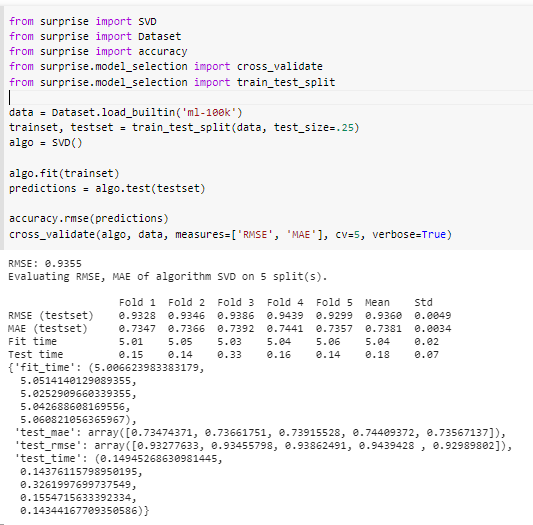
Surprise
Surprise surprise! There is a library to automate building recommendation systems! The recommendation system problem area has grown four-folds in the field of Data Science with audience-targeted ads and content. Surprise leverages on this very fact and provides you with a scikit-learn inspired solution for building recommendation systems. It supports methods such as train_test_split and cross_validate which makes the recommender system pipeline much easier. So next time you need to build a recommender system, don’t forget to use surprise!
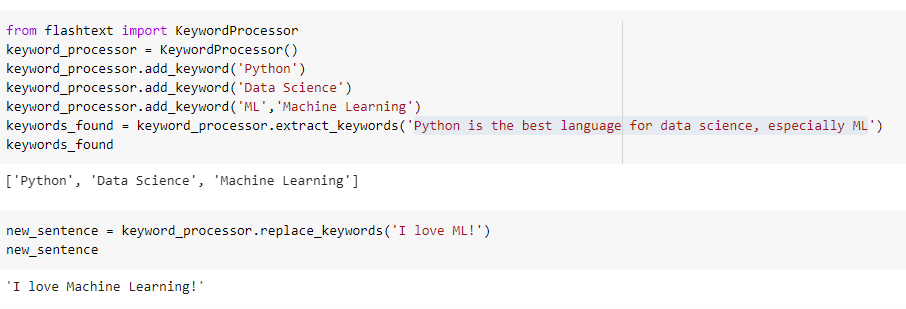
FlashText
If you have played around with NLP, you might know how some keywords and phrases can have an effect on the outcome of the entire model. FlashText is an easy to use the library, which can solve this very problem. Created for the sole purpose of finding and replacing keywords, FlashText can prove to be extremely efficient and helpful in NLP tasks such as summarization, topic modeling, document classification, and more. So the next time you need to manipulate your textual data, be sure to use FlashText for super fast and efficient results!
End Notes
So, now you know the ultimate secrets to getting those super fast and super accurate results for your Data Science problems, be it classification or regression; or time series forecasting; or recommender systems; or just some trusty data analysis, these libraries will up your game and give you the ultimate edge needed to ace the growing world of data science. Be sure to play around with these and always be on the lookout for more such hidden gems in python!








Very helpful content