Classification Model Simulator Application Using Dash in Python
This article was published as a part of the Data Science Blogathon.
Introduction
Build an app and bring data to life !!!!
Here are various topics that this article explores
Data
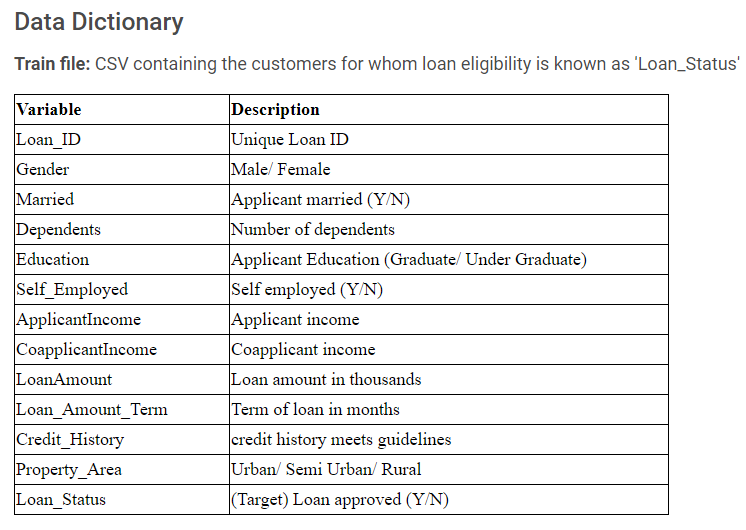

Front End – Add DCC & DAQ controls
Before we begin, let’s take a look at what we will build by the end of this blog.
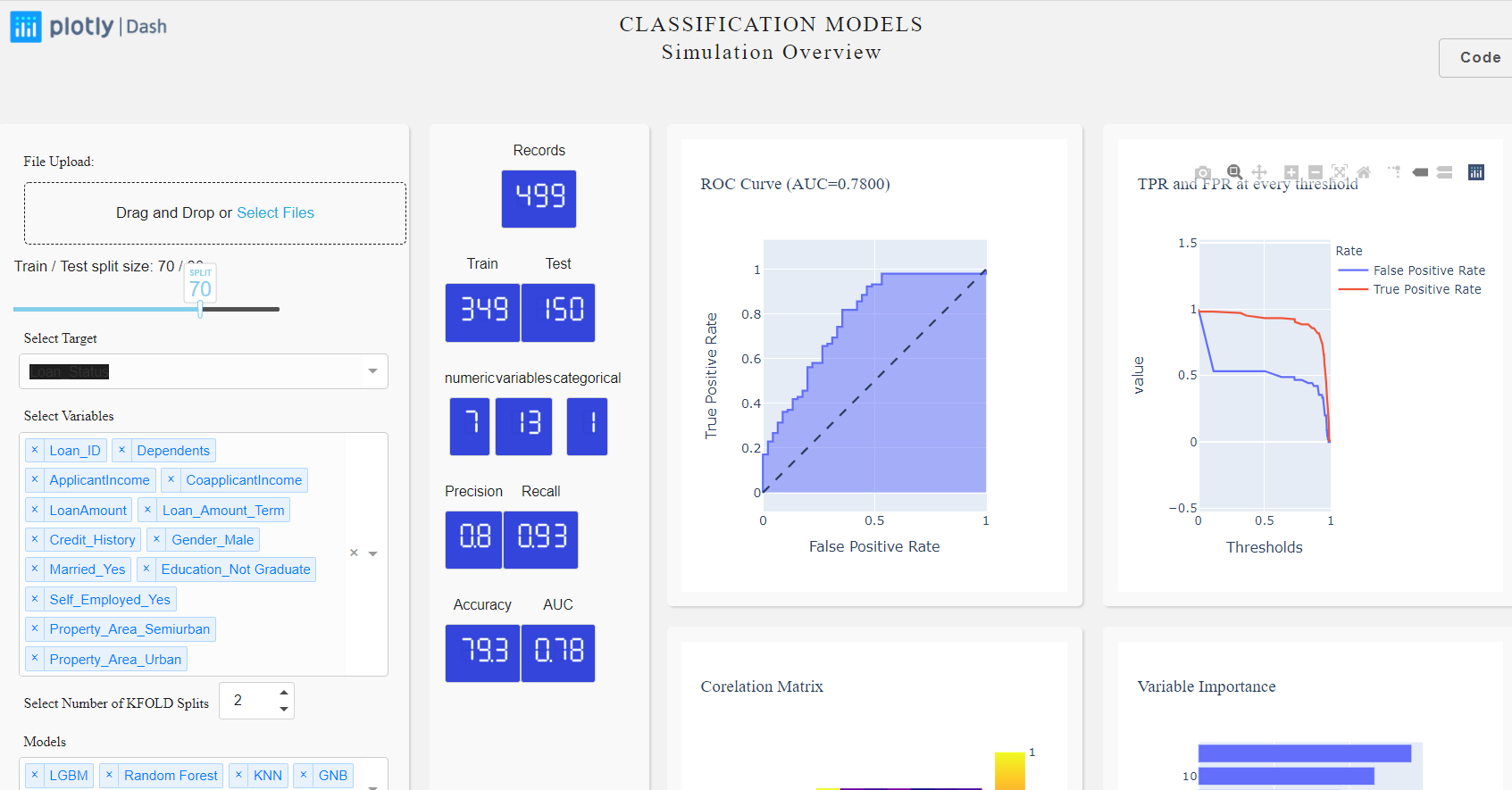
Slider:
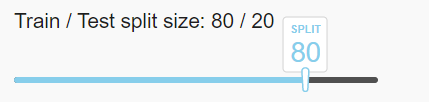
To start with let’s build a slider which we will use to split our dataset into train and test. The train set will be used to train the model and test for validating our model results.
daq.Slider(
id = 'slider',
min=0,
max=100,
value=70,
handleLabel={"showCurrentValue": True,"label": "SPLIT"},
step=10
),
Dropdowns:
options=[{'label':x, 'value':x} for x in obj_Data.df_train_dummies.columns],
html.P("Select Target", className="control_label"),
dcc.Dropdown(
id="select_target",
options=[{'label':x, 'value':x} for x in obj_Data.df_train_dummies.columns],
multi=False,
value='Loan_Status',
clearable=False,
),
Numeric Input with DAQ:
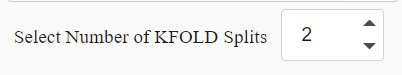
We also would like to have the user select a number of splits for model building. For more information refer KFOLD. let’s add a numeric field with min=1 and max=10.
daq.NumericInput(
id='id-daq-splits',
min=0,
max=10,
size = 75,
value=2
),
LED Display with DAQ:
daq.LEDDisplay(
id='records',
#label="Default",
value=0,
label = "Records",
size=FONTSIZE,
color = FONTCOLOR,
backgroundColor=BGCOLOR
)
html.Div(
[dcc.Graph(id="main_graph")],
),
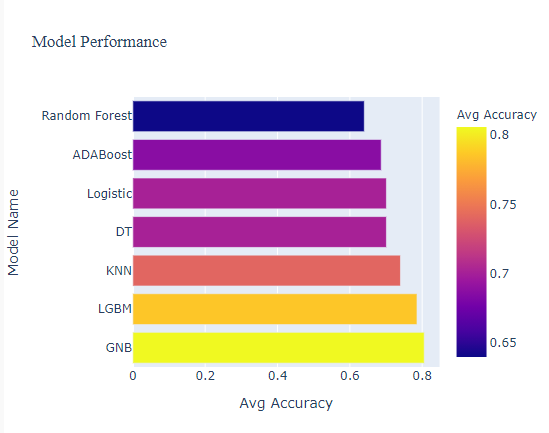
Back End – let’s build models and measure metrics:
Classification Model/s:
...
...
clf = lgb.LGBMClassifier(n_estimators=1000,max_depth=4,random_state=22)
clf.fit(X_trn,y_trn)
predictions = clf.predict(X_val)
fun_metrics(predictions, y_val)
fpr, tpr, _ = roc_curve(y_val, predictions)
fun_metricsPlots(fpr, tpr, "LGBM")
fun_updateAccuracy(clf, predictions)
....
....
if bestModel == 'GNB':
model = GaussianNB()
elif bestModel == 'LGBM':
model = lgb.LGBMClassifier()
elif bestModel == 'Logistic':
model = LogisticRegression()
elif bestModel == 'KNN':
model = KNeighborsClassifier()
elif bestModel == 'Raondom Forest':
model = RandomForestClassifier()
elif bestModel == 'DT':
model = tree.DecisionTreeClassifier()
else:
model = AdaBoostClassifier()
Measure Model Metrics:
from sklearn.metrics import roc_curve, roc_auc_score, recall_score, precision_score,accuracy_score precision = round(precision_score(testy, yhat),2) recall = round(recall_score(testy, yhat),2) accuracy = round(accuracy_score(testy, yhat)*100,1)

Build an AUC-ROC plot with Plotly Express:
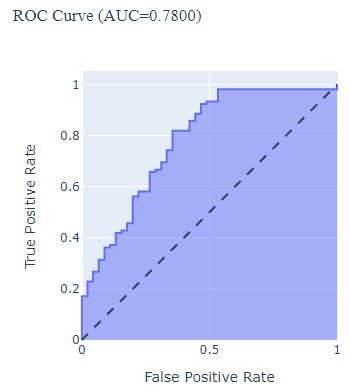
fig_ROC = px.area(
x=lr_fpr, y=lr_tpr,
title=f'ROC Curve (AUC={lr_auc:.4f})',
labels=dict(x='False Positive Rate', y='True Positive Rate')
)
fig_ROC.add_shape(
type='line', line=dict(dash='dash'),
x0=0, x1=1, y0=0, y1=1
)
fig_ROC.update_yaxes(scaleanchor="x", scaleratio=1)
fig_ROC.update_xaxes(constrain='domain')
Interaction with callbacks:
[
Output("main_graph", 'figure'),
Output("recall", 'value'),
]
....
[
Input("select_target", "value"),
Input("select_independent", "value"),
...
]
....
@app.callback(
[
Output("main_graph", 'figure'),
Output("individual_graph", 'figure'),
Output("aggregate_graph", 'figure'),
Output("slider-output-container", 'children'),
Output("precision", 'value'),
Output("recall", 'value'),
Output("accuracy", 'value'),
Output("auc", 'value'),
Output("trainset", 'value'),
Output("testset", 'value'),
Output('model-graduated-bar', 'value'),
Output('id-insights', 'children'),
Output("model-graphs", 'figure'),
Output("best-model", 'children'),
Output("id-daq-switch-model", 'on'),
Output('auto-toast-model', 'is_open')
],
[
Input("select_target", "value"),
Input("select_independent", "value"),
Input("slider", "value"),
Input("id-daq-splits", "value"),
Input("select_models", "value")
]
)
def measurePerformance(target, independent, slider, splits, selected_models):
fig_ROC, Fig_Precision, fig_Threshold,precision, recall, accuracy, trainX, testX, auc, fig_model, bestModel = multiModel.getModels(target,independent, slider, splits, selected_models)
auc_toast = True if auc < 0.5 else False
return fig_ROC, Fig_Precision, fig_Threshold, 'Train / Test split size: {} / {}'.format(slider, 100-slider), precision, recall, accuracy,auc, trainX, testX, auc*100, f'The best performing model is {bestModel} with accuracy of {accuracy}, precision of {precision} and recall of {recall} with Area under curve of {auc}. Try for various K FOLD values to explore further.' ,fig_model, f'The top performaing model is {bestModel}', True, auc_toast
Write some testcases using PyTest:
#pip install pytest
import pytest
def test_buildModels():
fig_ROC, fig_precision, fig_threshold, precision, recall, accuracy, trainX, testX, lr_auc = buildModel(target, independent, slider, selected_models)
assert precision < 1
Configure test cases
Test cases under execution
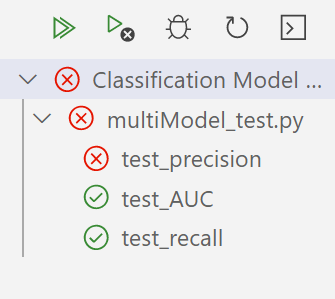
One test case failed
Logging errors:
# install the library if you haven't already done # pip install logging import logging logging.basicConfig(filename= 'model.log', level = logging.DEBUG,format='%(asctime)s:%(levelname)s:%(filename)s:%(funcName)s:%(message)s')
The errors can be tracked in the model.log file. Here is a sample error:

Once all the UI components and models are successfully built. You can access the application in your localhost (http://127.0.0.1:8050) and can play with the train/test slider, splits, and variables to see the plots and metrics instantly get updated.
Conclusion:
What Next?:
Happy learnings !!!!
References:







