How Can You Build a Career in Data Science and Machine Learning?
Introduction to Machine Learning
Machine Learning is the crux of Artificial Intelligence. With increasing developments in AI, IoT and other smart technologies, machine learning jobs are gaining higher exposure and demand in the technology market. If you are currently an IT professional, you might be interested in a career switch because of the exciting opportunities the industry offers to its aspirants. Or, you might have an interest that you have wanted to pursue long.
However, not knowing exactly how to start a career in machine learning can lead an aspirant in the wrong way. There should be a proper agenda on how to identify the right opportunity and approach it in a systematic way. In this article, let us see some of the essential steps that one can take towards their machine learning journey.

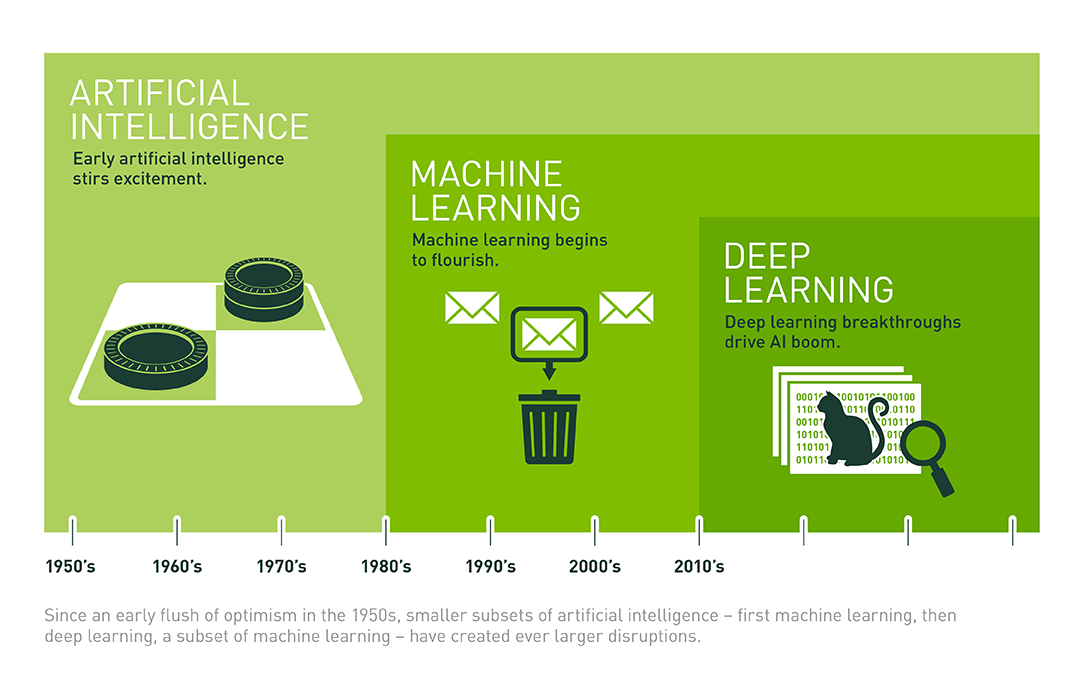
AI, Machine Learning & Deep Learning
Artificial Intelligence is the science and engineering of making intelligent machines, especially intelligent computer programs. Artificial Intelligence is related to the similar task of using computers to understand human intelligence, but AI does not have to confine itself to methods that are biologically observable.” Machine learning is a subfield of artificial intelligence, which enables machines to learn from past data or experiences without being explicitly programmed.
Machine Learning enables a computer system to make predictions or take some decisions using historical data without being explicitly programmed. Machine learning uses a massive amount of structured and semi-structured data so that a machine learning model can generate accurate results or give predictions based on that data.
Deep Learning is a subset of machine learning where algorithms are created and function similar to those in machine learning, but there are numerous layers of these algorithms, each providing a different interpretation to the data it feeds on. Such a network of algorithms is called artificial neural networks(ANN), being named so as their functioning is an inspiration, or you may say; an attempt at imitating the function of the human neural networks present in the brain.
Data Science Process
It is time to get accustomed to the general process in a data science project. It always starts with finding a valid business use-case depending upon the industry you are working in. Next, we need to find the data to support the business problem. This usually requires the Data Engineer to develop ETL scripts in tools like Informatica or Talend that will connect to the data source(s) and retrieve data. Usually, data sourcing can be a challenging task if there are security constraints in place as per company policy.
Data can be either in textual format stored in flat files or RDBMS databases. Or, it can be in the form of video or audio files. At this stage, the data analyst explores the data in columns and rows look for obvious issues like duplicates and missing data. The data manipulation or cleansing can make up to 70% of the project’s time depending on the amount of pre-processing that needs to be done.
Next, the machine learning engineer/data scientist applies algorithms like regression, classification, segmentation, etc on the data and measures the accuracy metrics. it is expected that different models can be generated that give different performance measures. The final model is selected and deployed in the production environment.
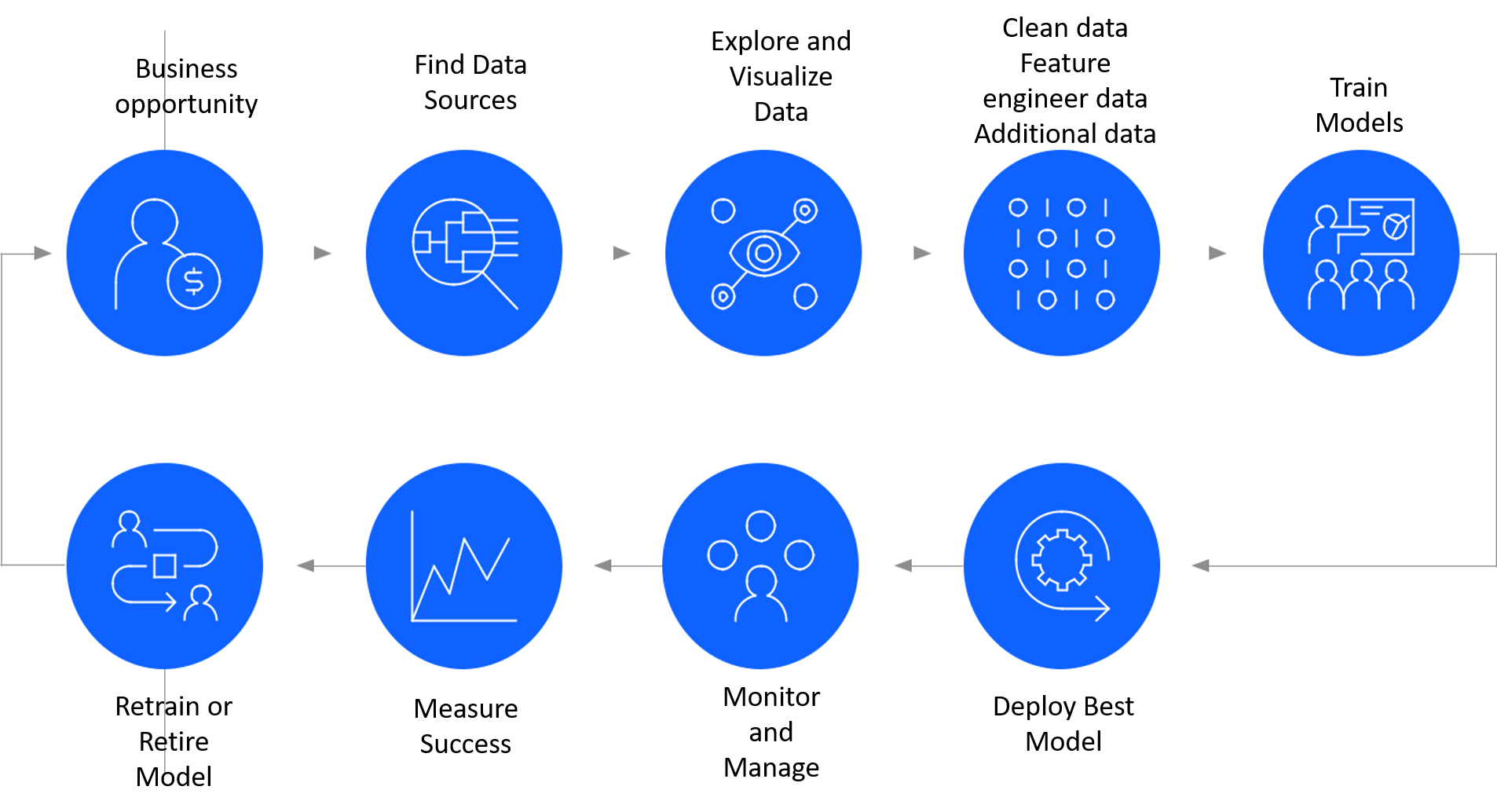
Image sourced from Quanthub.com
Understand the Prerequisites
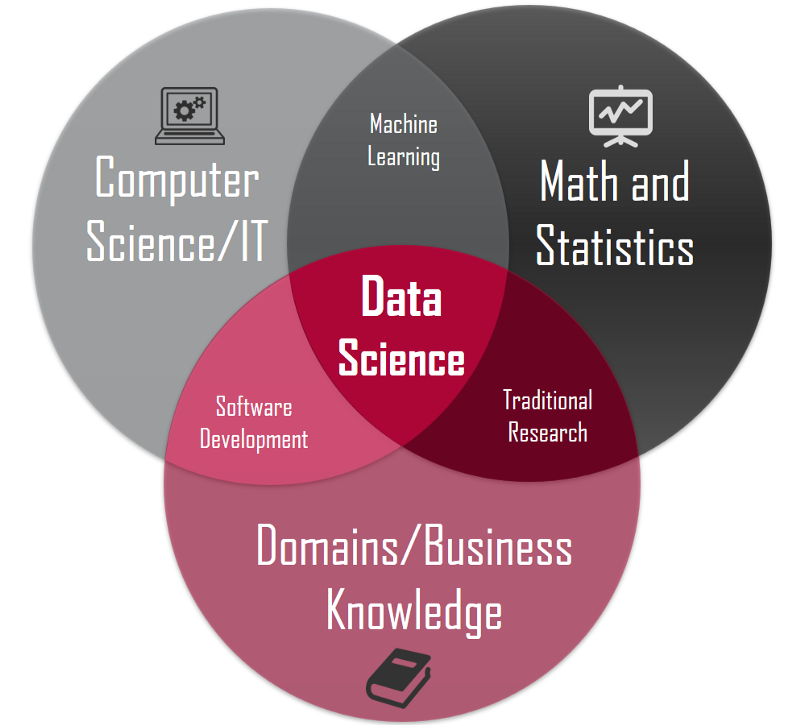
To get into a field in Data Science/Machine Learning, you must have a strong technical background in one or more of the following topics. Remember, this is a highly technical field and one must be prepared to have the requisite educational qualification before starting the journey.
Mathematics: Behind numerous standard models and constructions in Data Science there is mathematics that makes things work. It is important to understand it to be successful in Data Science. It includes crucial fields such as Discrete Mathematics, Calculus, Linear Algebra, and Probability. Learning the theoretical background for data science or machine learning can be a daunting experience, as it involves multiple fields of mathematics and a long list of online resources.
However, suppose you are a beginner in machine learning and looking to get a job in the industry. In that case, its not recommended to study all the math before starting to do actual practical work, this bottom-up approach is counter-productive. The amount of math you’ll need depends on the role. Generally, every data scientist needs to know some statistics and probability theory.
Computer Science: Computer Science is the study of computers and computational systems. Unlike electrical and computer engineers, computer scientists deal mostly with software and software systems; this includes their theory, design, development, and application. Computer science deals with the theoretical foundations of information and computation, taking a scientific and practical approach to computation and its applications.
Computation is defined as any type of calculation or use of computing technology that follows well-defined models (such as algorithms and protocols) in the practice of information processing (which in turn is defined as the use of these models to transform data in computers). Computer science is considered by many of its practitioners to be a foundational science – one which makes other knowledge and achievements possible.
The study of computer science involves systematically studying methodical processes (such as algorithms) in order to aid the acquisition, representation, processing, storage, communication of, and access to information. This is done by analyzing the feasibility, structure, expression, and mechanization of these processes and how they relate to this information. In computer science, the term ‘information’ refers usually to information which is encoded in bits and bytes in computer memory.

Statistics: Probability and Statistics form the basis of Data Science. Estimates and predictions form an important part of Data Science. With the help of statistical methods, we make estimates for further analysis. Thus, statistical methods are largely dependent on the theory of probability. And all probability and statistics are dependent on Data.
Statistics can be a powerful tool when performing the art of Data Science (DS). From a high-level view, statistics is the use of mathematics to perform technical analysis of data. A basic visualization such as a bar chart might give you some high-level information, but with statistics, we get to operate on the data in a much more information-driven and targeted way. The math involved helps us form concrete conclusions about our data rather than just guesstimating. It’s often the first stats technique you would apply when exploring a dataset and includes things like bias, variance, mean, median, percentiles, and many others.

Programming in R/Python
R is a programming language and software environment for statistical analysis, graphics representation, and reporting. R is freely available under the GNU General Public License, and pre-compiled binary versions are provided for various operating systems like Linux, Windows, and Mac. This programming language was named R, based on the first letter of first name of the two R authors (Robert Gentleman and Ross Ihaka).
R and its libraries implement a wide variety of statistical and graphical techniques, including linear and nonlinear modeling, classical statistical tests, time-series analysis, classification, clustering, and others. R is easily extensible through functions and extensions, and the R community is noted for its active contributions in terms of packages. Python is a powerful general-purpose programming language.
It is used in web development, data science, creating software prototypes, and so on. Fortunately for beginners, Python has simple easy-to-use syntax. This makes Python an excellent language to learn to program for beginners. It is one of the best languages used by data scientists for various data science projects/applications. Python provides great functionality to deal with mathematics, statistics, and scientific function.
It provides great libraries to deals with data science applications. The comparison of Python and R has been a hot topic in industry circles for years. R has been around for more than two decades, specialized for statistical computing and graphics while Python is a general-purpose programming language that has many uses along with data science and statistics.


Business/Domain Knowledge: Business knowledge is a business owner’s extensive reservoir of understanding of customers’ needs and preferences, business environments and their dynamics, staff skills, experiences and potentials, and the business‘ overall foreseeable direction. Every data scientist must place great importance on learning business knowledge related to the problem they are solving.
In fact, every newly hired data scientist in the organization should avoid building any models for the first several weeks – use that time to develop a deep business knowledge as well as master the “meta-data” – data about data. Putting a priority on business knowledge in your initial days at an organization will help your technical skills find a smooth runway to land or take off in the future,
Roles and Job Descriptions
Data science experts are needed in virtually every job sector—not just in technology. In fact, the five biggest tech companies—Google, Amazon, Apple, Microsoft, and Facebook—only employ one half of one percent of U.S. employees. However, in order to break into these high-paying, in-demand roles an advanced education is generally required. We have listed out some of the relevant career options in Data Science that you can break into with advanced education.
Data Scientist: A Data Scientist will be responsible for modeling complex problems, discovering insights and identifying opportunities through the use of statistical, machine learning, algorithmic, data mining, and visualization techniques. The person will need to collaborate effectively with internal stakeholders and cross-functional teams to solve problems, create operational efficiencies, and deliver successfully against high organizational standards. As a data scientist, you might be asked to assess how a change in marketing strategy could affect your company’s bottom line.
This would entail a lot of data analysis work (acquiring, cleaning, and visualizing data), but it would also probably require building and training a machine learning model that can make reliable future predictions based on past data.
Machine Learning Engineer: Research new data approaches and algorithms to be used in adaptive systems including supervised, unsupervised, and deep learning techniques. Machine learning engineers often go by titles like Research Scientist or Research Engineer. There is some commonality between a machine learning engineer and a data scientist. At some companies, this title just means a data scientist who has specialized in machine learning algorithms.
At other companies, “machine learning engineer” is more of a software engineering role that involves taking a data scientist’s analysis and turning it into deployable software. Although the specifics vary, virtually all machine learning engineer positions will require at least data science programming skills and pretty advanced knowledge of machine learning algorithms.
Data Analyst: Data analysts sift through data and provide reports and visualizations to explain what insights the data is hiding. When somebody helps people from across the company understand specific queries with charts, they are filling the data analyst role. In some ways, you can think of them as junior data scientists, or the first step on the way to a data science job. Transform and manipulate large data sets to suit the desired analysis for companies. For many companies, this role can also include tracking web analytics and analyzing A/B testing.
Data analysts also aid in the decision-making process by preparing reports for organizational leaders which effectively communicate trends and insights gleaned from their analysis.
Statistician: ‘Statistician’ is what data scientists were called before the term ‘data scientist’ existed. At a high level, statisticians are professionals who apply statistical methods and models to real-world problems. They gather, analyze, and interpret data to aid in many business decision-making processes. Statisticians are valuable employees in a range of industries, and often seek roles in areas such as business, health and medicine, government, physical sciences, and
environmental sciences. Many entry-level statistician roles require candidates to hold a master’s degree, usually in statistics or mathematics.
However, those who demonstrate proficiency in both statistical analyses as well as another subject area, for example, economics and econometrics, computer and material science, or biology can have a distinct competitive advantage when seeking employment in a specialized industry.
Data Architect: A Data Architect ensures data solutions are built for performance and design analytics applications for multiple platforms. In addition to creating new database systems, data architects often find ways to improve the performance and functionality of existing systems, as well as working to provide access to database administrators and analysts. The Data Architect will work closely with the users, systems designers, and developers on a Project team.
It is a natural evolution from Data Analyst and Database Designer and reflects the emergence of Internet Web Sites which need to integrate data from different unrelated Data Sources. These Sources can be either external, such as Market Feeds,(e.g. Bloomberg), and News Agencies,(e.g. Reuters). Or internal, such as existing systems, such as HR for Employee details.
Business Intelligence Developer: Business intelligence (BI) is a set of technologies and practices for transforming business information into actionable reports and visualizations. A business intelligence developer is an engineer that’s in charge of developing, deploying, and maintaining BI interfaces. Those include query
tools, data visualization, and interactive dashboards, ad hoc reporting, and data modeling tools. BI developers design and develop strategies to assist business users in quickly finding the information they need to make better business decisions. Extremely data-savvy, they use BI tools or develop custom BI analytic applications to facilitate the end-users’ understanding of their systems.
Prospective employers typically look for a BI developer who is an excellent communicator and troubleshooter. This job position requires an individual who can conduct testing, create data storage tools, collaborate with teams during system integration, and be responsible for the maintenance and support of data
analytic platforms.
Enterprise Architect: An enterprise architect is responsible for aligning an organization’s strategy with the technology needed to execute its objectives. To do so, they must have a complete understanding of the business and its technology needs in order to design the systems architecture required to meet those needs. Enterprise architects are key in establishing an organization’s IT infrastructure and maintaining and updating IT hardware, software, and services to ensure it supports established enterprise goals.
Big Data Engineer/Data Engineer: A Big Data Engineer is a person who creates and manages a company’s Big Data infrastructure and tools, and is someone that knows how to get results from vast amounts of data quickly. The actual definition of this role varies and often mixes with the Data Scientist role. Here, we will assume that it is a role focused on engineering, without statistics and strong machine learning skills required. They will work on collecting, storing, processing, and analyzing of huge sets of data.
You will also be responsible for integrating them with the architecture used across the company. Big Data engineers are tasked with building massive big data reservoirs and highly scalable and fault-tolerant distributed systems, that can inherently store and process massive volumes or rapidly changing data streams. They are also responsible for developing, constructing, testing, and maintaining frameworks like large-scale data processing systems and databases.

Tools and Skills
So, now you know that to get into the field of Data Science, you need to have a certain skill set. It is usually a mix of technical and non-technical staff. Whereas roles such as Data Scientist/Machine Learning Engineer will require you to have the hardcore technical know-how, business-facing/strategy roles will need more domain knowledge and communication skills.
| Technology/Domain | Tools/Languages | |
|
Descriptive Statistics, Inferential Statistics, Linear Algebra, Differential Calculus, Discrete Mathematics | |
| Programming in R/Python | Getting Data In/Out, Managing Dataframes, Loop Functions, Regular Expressions, Control Structures, Implementing Machine Learning algorithms | |
| Big Data | Hadoop Ecosystem(Hive, Pig,Sqoop, Flume), Big Data Lakes, No SQL, Apache Spark, Spark MLLib | |
| Business Intelligence | SQL, Microsoft Power BI, SAP BI, Tableau, Oracle Fusion | |
| Machine Learning | ScikitLearn: Regression, Classification, Segmentation, Feature Engineering, Dimensionality Reduction, Training and Deploying Models | |
| Advanced Machine Learning(Deep Learning) | TensorFlow, Keras, Artificial Neural Networks, Deep NeuralNets, Convolutional Neural Networks, Autoencoders, Reinforcement Learning | |
| Domain Knowledge | Solid understanding of the industry you’re working in, and know what business problems your company is trying to solve. You must understand how the problem you solve can impact the business | |
| Data Visualization |
Matplotlib: low level, provides lots of freedom.
Pandas Visualization: easy to use interface, built on Matplotlib.
Seaborn: high-level interface, great default styles.
ggplot: based on R’s ggplot2, uses Grammar of Graphics.
|
|
| Communication Skills | Clearly translate technical findings to a non-technical team, such as the Marketing or Sales departments. Create a storyline around the data to make it easy for anyone to understand |

Start Preparing
Now, you not only know the basic eligibility criteria to join the industry but the skill sets you need to work on as well. The next phase of career transitioning is to start working on the skills you lack and getting your basics right. Read books on probability or statistics, brush up your coding skills, and gain firsthand exposure to your weaknesses.
As you prepare, we also recommend you join a substantial course on artificial intelligence and machine learning because it will not just help you get the basics right but gradually take you through advanced concepts as well. Let’s go through some of the sources for gaining knowledge about Machine Learning.
Books
- An Introduction to Statistics with Python with Applications in the Life Sciences(by Thomas Haslwanter)
- Practical Statistics for Data Scientists, 50 Essential Concepts(by Peter Bruce and Andrew Bruce)
- R for Data Science, Learn and Explore the concepts of Data Science with R(by Dan Toomey)
- Python Data Science Handbook, Essential Tools for Working With Data(by Jake Vanderplas)
- Mastering Python for Data Science(by Samir Madhavan)
-
Introduction to Machine Learning with Python: A Guide for Data Scientists(by Andreas C. Mueller)
-
Machine Learning with PySpark: With Natural Language Processing and Recommender Systems(by Pramod Singh)
-
R for data science: Import, Tidy, Transform, Visualize, And Model Data(by Hadley Wickham)
-
Data Science and Big Data Analytics: Discovering, Analyzing, Visualizing and Presenting Data (by EMC Education Services)
-
Python Machine Learning By Example(by Yuxi Liu)

Get Certification
At the initial stage, you should go through the content that is freely available on the internet to gain a rudimentary understanding of the field. As you gain confidence, you will need some mentoring to stay on the right track and not lose focus. A course from an AI institute teaches you the required skills the right way and allows you to get hands-on experience in the industry.
You also get access to course materials that would further help you understand better about the technologies. Here, I have listed some of the popular online courses in Machine Learning. These are courses mainly intended toward the working professional who wants to continue their current job while undergoing online training in Data Science/Machine Learning. You can visit the individual websites of these courses to get detailed information about the courses.
International
| Certificate Program in Data Science | UC Berkeley Extension |
| Professional Certificate in Data Science for Executives | Columbia University |
| Data Science Graduate Certificate | Harvard Extension School |
| Specialized Certificate in Machine Learning Methods | UC San Diego Extension |
| MicroMasters® Program in Statistics and Data Science | Massachusetts Institute of Technology |
| Senior Data Scientist/Principal Data Scientist | Data Science Council of America |
| AI & Machine Learning Professional | SAS Academy for Data Science |

Get Practice
The best way to learn anything is by practicing it. A number of theories and tutorials are available online as well as offline to learn machine learning. But one cannot truly learn until and unless one truly gets some hands-on training to learn how to actually solve the problems. We list down 5 online platforms where a machine learning engineer can practice solving business problems.
- Google Colab: Colab is a free Jupyter notebook environment that runs entirely in the cloud. This platform provides GPU which is free of cost and supports Python 2 and 3 versions. Most importantly, it does not require a setup and the notebooks that you create can be simultaneously edited by your team members – just the way you edit documents in Google Docs. Colab supports many popular machine learning libraries which can be easily loaded in your notebook.
- CloudxLab: CloudxLab is a cloud-based virtual lab for practicing Big Data (Hadoop, Spark, etc), Machine Learning, and Deep Learning technologies. Practice Anywhere, anytime, using any operating system. You will just need an internet connection and an account with CloudxLab. You can log in to CloudxLab via any device, any browser, and start practicing Big Data technologies.No more virtual machines. Only practice in real-time. Using BootML creates your own Machine learning code from your dataset with the best possible algorithms. No need to worry about any in-depth knowledge of ML. Attend webinars on Machine Learning by industry experts.
- OpenML: The Open Machine Learning project is an inclusive movement to build an open, organized, online ecosystem for machine learning. We build open-source tools to discover (and share) open data from any domain, easily draw them into your favorite machine learning environments, quickly build models alongside (and together with) thousands of other data scientists, analyze your results against the state of the art, and even get automatic advice on how to build better models
- Kaggle : Kaggle is an online community of data scientists and machine learning practitioners. Kaggle allows users to find and publish data sets, explore and build models in a web-based data-science environment, work with other data scientists and machine learning engineers, and enter competitions to solve data science challenges. With over 19,000 public datasets and 200,000 public notebooks, this platform provides one of the best places to practice data science computational problems.
Summary
With data science and analytics becoming an important part of most organizations, the subject has attracted wide attention among experienced IT professionals and engineering graduates. By now you should have created a good portfolio of skillset and project experience. Be ready to make the switch to a role in Data Science. If you’re looking for on-the-job learning and an entry-level role that’s often a path to a permanent, full-time job, internships are a great option.
Although most people who study data science are looking for full-time employment with an established company or startup, it’s worth remembering that data science skills afford you the opportunity to work as a freelancer. If you are seeking a pure-play Data Scientist or a Machine Learning Engineer role then make sure to get your academics right.
These are technical roles that will require good knowledge in Computer Programming and Statistics. If you are more inclined towards interfacing with business then you need to learn as much as you can about the industry you are working for. To be able to convert technical insights into a language that can be easily understood by everyone is an important aspect. Data Science is an ever-evolving field with new topics coming to the forefront every year. So, it important to keep yourself abreast of the latest tool and technologies in the field.











Thanks) it's a very thorough article
Thank you for giving us some important features. we appreciate your thoughts.
Thank you for giving us some important features.
Thank you for giving us some important information.