Understanding Text Classification in NLP with Movie Review Example
Introduction
Artificial intelligence has undergone remarkable advancements in recent years. The limitless benefits of machine learning are evident, while Natural Language Processing (NLP) empowers machines to comprehend and convey the meaning of text. NLP’s impact spans healthcare, finance, media, and more. This article explores NLP’s grasp of text, emphasizing words and sequence analysis, with a focus on text classification in NLP and sentiment analysis of 50,000 IMDB reviews. NLP’s reach extends to cars, smartphones, and AI-powered chatbots like Siri and Alexa. Its pivotal role in information retrieval and voice detection underlines its value, ultimately enhancing human-computer interactions and communication in the evolution of AI.
Learning Objectives
- Gain insight into how Natural Language Processing (NLP) enables machines to comprehend textual content and parts of speech.
- Learn about the significance of Words and Sequence Analysis in NLP, focusing on techniques like text classification, vector semantics, word embeddings, probabilistic language models, sequential labeling, and speech reorganization.
- Explore various methods used in text classification, including identifying how NLP algorithms categorize text into different predefined classes.
- Understand the concept of semantic understanding and word embeddings, which are essential in bridging the gap between textual data and machine understanding.
- The concept of probabilistic language models enables computers to predict and generate coherent and contextually appropriate text.
- Gain insights into sequential labeling, an essential technique in NLP, where data points are labeled in sequence to extract meaningful information.
- Analyze sentiment analysis on a dataset of fifty thousand IMDB movie reviews to identify whether user reviews are positive or negative.
- Discover how NLP techniques are practically applied in real-world scenarios, particularly in analyzing user sentiments and opinions from large datasets.
This article was published as a part of the Data Science Blogathon.
Table of contents
What is Text Classification?
Text classification in NLP involves categorizing and assigning predefined labels or categories to text documents, sentences, or phrases based on their content. Text classification aims to automatically determine the class or category to which a piece of text belongs. It’s a fundamental task in NLP with numerous practical applications, including sentiment analysis, spam detection, topic labeling, language identification, and more. Text classification algorithms analyze the features and patterns within the text to make accurate predictions about its category, enabling machines to organize, filter, and understand large volumes of textual data.

Applications of NLP
Natural Language Processing (NLP) finds diverse applications in text classification across various industries and domains. Some critical applications include:
- Sentiment Analysis: NLP analyzes text sentiment, categorizing content as positive, negative, or neutral. This is crucial for gauging customer opinions, feedback, and market sentiment.
- Spam Detection: NLP helps identify and filter out spam emails or messages by analyzing their content and characteristics, enhancing communication security.
- Topic Labeling: Text classification aids in automatically assigning topics or categories to documents, making content organization and retrieval more efficient.
- Language Identification: NLP algorithms can detect the language in which a text is written, which is useful for multilingual content processing and translation.
- News Categorization: NLP enables news articles to be categorized into sections like politics, technology, sports, etc., improving content organization for readers.
- Product Classification: E-commerce platforms use NLP for product categorization, ensuring items are correctly labeled and presented to customers.
- Customer Feedback Analysis: NLP analyzes customer reviews and feedback to extract insights, helping businesses understand customer satisfaction and areas of improvement.
- Medical Document Classification: NLP aids in categorizing medical records, research papers, and patient notes, assisting in efficient data retrieval for healthcare professionals.
- Legal Document Categorization: Law firms use NLP to classify legal documents, making managing and retrieving information from large databases easier.
- Social Media Monitoring: NLP tracks and classifies social media posts, tweets, and comments, allowing brands to monitor their online presence and engage with users.
- Fraud Detection: In finance, NLP helps classify financial texts to detect fraudulent activities and identify potential risks.
- Resume Screening: NLP automates resume screening by categorizing job applications based on skills, experience, and qualifications.
- Content Recommendation: NLP-driven text classification assists in recommending relevant articles, blogs, or products to users based on their interests.
Also Read: Top 13 NLP Projects You Must Know in 2023
Words and Sequences
NLP system needs to understand text, sign, and semantic properly. Many methods help the NLP system to understand text and symbols. They are text classification, vector semantic, word embedding, probabilistic language model, sequence labeling, and speech reorganization.
Text Classification
Text clarification is the process of categorizing the text into a group of words. By using NLP, text classification can automatically analyze text and then assign a set of predefined tags or categories based on its context. NLP is used for sentiment analysis, topic detection, and language detection. There is mainly three text classification approach:
- Rule-based System
- Machine System
- Hybrid System
In the rule-based approach, texts are separated into an organized group using a set of handicraft linguistic rules. Those handicraft linguistic rules contain users to define a list of words that are characterized by groups. For example, words like Donald Trump and Boris Johnson would be categorized into politics. People like LeBron James and Ronaldo would be categorized into sports.
Machine-based classifier learns to make a classification based on past observation from the data sets. User data is prelabeled as tarin and test data. It collects the classification strategy from the previous inputs and learns continuously. Machine-based classifier usage a bag of a word for feature extension.

In a bag of words, a vector represents the frequency of words in a predefined dictionary of a word list. We can perform NLP using the following machine learning algorithms: Naïve Bayer, SVM, and Deep Learning.

The third approach to text classification is the Hybrid Approach. Hybrid approach usage combines a rule-based and machine Based approach. Hybrid based approach usage of the rule-based system to create a tag and use machine learning to train the system and create a rule. Then the machine-based rule list is compared with the rule-based rule list. If something does not match on the tags, humans improve the list manually. It is the best method to implement text classification
Vector Semantic
Vector Semantic is another way of word and sequence analysis. It defines semantic and interprets words meaning to explain features such as similar words and opposite words. The main idea behind vector semantic is two words are alike if they have used in a similar context. Vector semantic divide the words in a multi-dimensional vector space. Vector semantic is useful in sentiment analysis.

Word Embedding
Word embedding is another method of word and sequence analysis. Embedding translates spares vectors into a low-dimensional space that preserves semantic relationships. Word embedding is a type of word representation that allows words with similar meaning to have a similar representation. There are two types of word embedding-
- Word2vec
- Doc2Vec.
Word2Vec is a statistical method for effectively learning a standalone word embedding from a text corpus.

Doc2Vec is similar to Doc2Vec, but it analyzes a group of text like pages.

Probabilistic Language Model
Another approach to word and sequence analysis is the probabilistic language model. The goal of the probabilistic language model is to calculate the probability of a sentence of a sequence of words. For example, the probability of the word “a” occurring in a given word “to” is 0.00013131 percent.

Sequence Labeling
Sequence labeling is a typical NLP task that assigns a class or label to each token in a given input sequence. If someone says “play the movie by tom hanks”. In sequence, labeling will be [play, movie, tom hanks]. Play determines an action. Movies are an instance of action. Tom Hanks goes for a search entity. It divides the input into multiple tokens and uses LSTM to analyze it. There are two forms of sequence labeling. They are token labeling and span labeling.
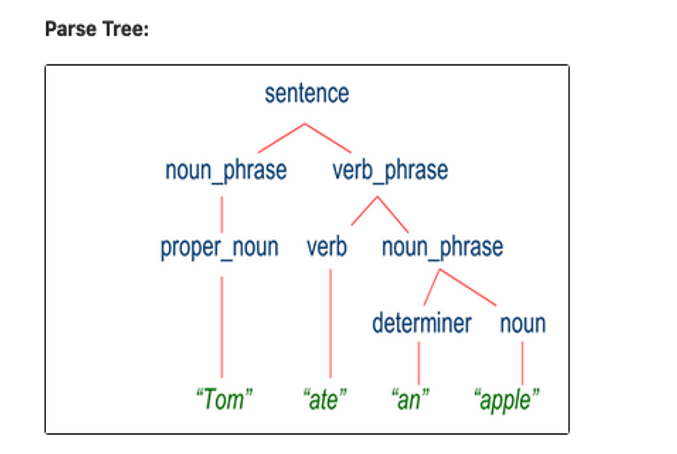
Parsing is a phase of NLP where the parser determines the syntactic structure of a text by analyzing its constituent words based on an underlying grammar. For example, “tom ate an apple” will be divided into proper noun tom, verb ate, determiner , noun apple. The best example is Amazon Alexa.

We discuss how text is classified and how to divide the word and sequence so that the algorithm can understand and categorize it. In this project, we are going to discover a sentiment analysis of fifty thousand IMDB movie reviewer. Our goal is to identify whether the review posted on the IMDB site by its user is positive or negative.
This project covers text mining techniques like Text Embedding, Bags of Words, word context, and other things. We will also cover the introduction of a bidirectional LSTM sentiment classifier. We will also look at how to import a labeled dataset from TensorFlow automatically. This project also covers steps like data cleaning, text processing, data balance through sampling, and train and test a deep learning model to classify text.
Parsing
Parser determines the syntactic structure of a text by analyzing its constituent words based on an underlying grammar. It divides group words into component parts and separates words.
Semantic
Text is at the heart of how we communicate. What is really difficult is understanding what is being said in written or spoken conversation? Understanding lengthy articles and books are even more difficult. Semantic is a process that seeks to understand linguistic meaning by constructing a model of the principle that the speaker uses to convey meaning. It’s has been used in customer feedback analysis, article analysis, fake news detection, Semantic analysis, etc.
Text Classification in NLP Example with Code
Here is the code Sample:
Importing Necessary Library
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
#Importing require Libraries
import os
import matplotlib.pyplot as plt
import nltk
from tkinter import *
import seaborn as sns
import matplotlib.pyplot as plt
sns.set()
import scipy
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_datasets as tfds
from tensorflow.python import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding, LSTM
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_reportDownloading Necessary File
# this cells takes time, please run once
# Split the training set into 60% and 40%, so we'll end up with 15,000 examples
# for training, 10,000 examples for validation and 25,000 examples for testing.
original_train_data, original_validation_data, original_test_data = tfds.load(
name="imdb_reviews",
split=('train[:60%]', 'train[60%:]', 'test'),
as_supervised=True)Getting Word Index from Keras Datasets
#tokanizing by tensorflow
word_index = tf.keras.datasets.imdb.get_word_index(
path='imdb_word_index.json')
In [8]:
{k:v for (k,v) in word_index.items() if v < 20}Output
Out[8]:
{'with': 16, 'i': 10, 'as': 14, 'it': 9, 'is': 6, 'in': 8, 'but': 18, 'of': 4, 'this': 11, 'a': 3, 'for': 15, 'br': 7, 'the': 1, 'was': 13, 'and': 2, 'to': 5, 'film': 19, 'movie': 17, 'that': 12}Positive and Negative Review Comparision
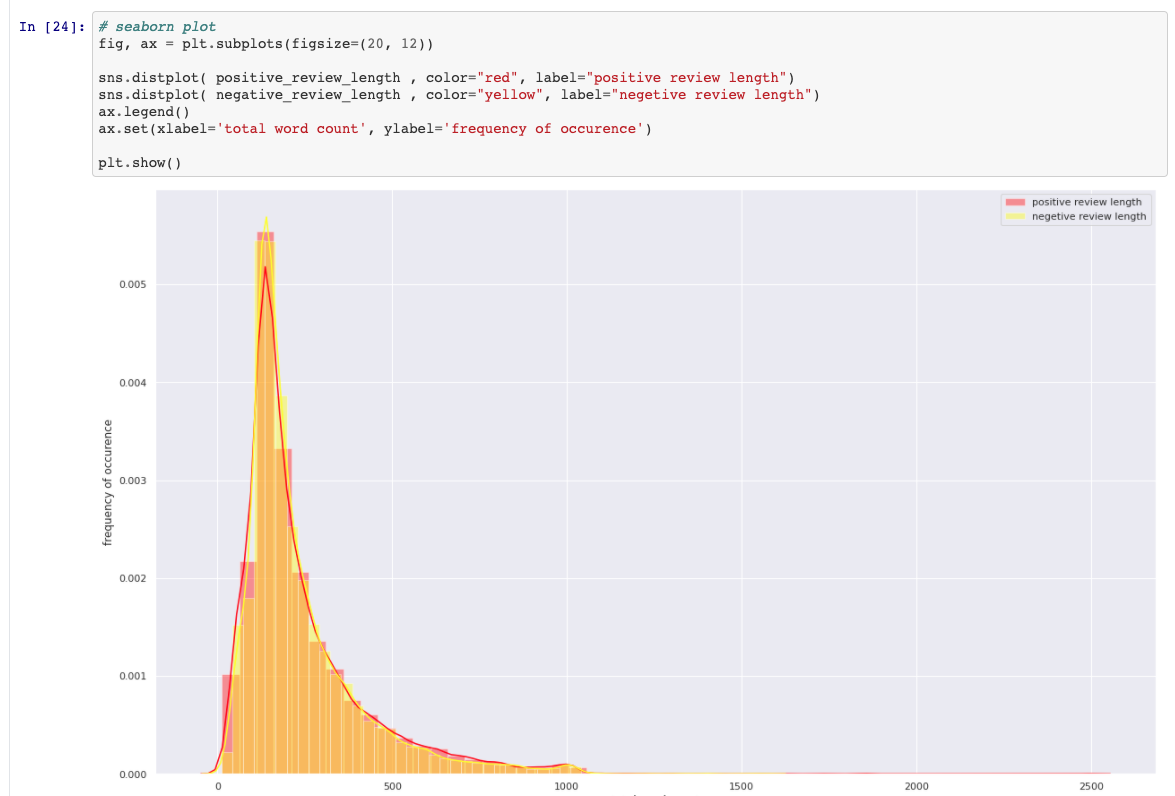
Creating Train, Test Data

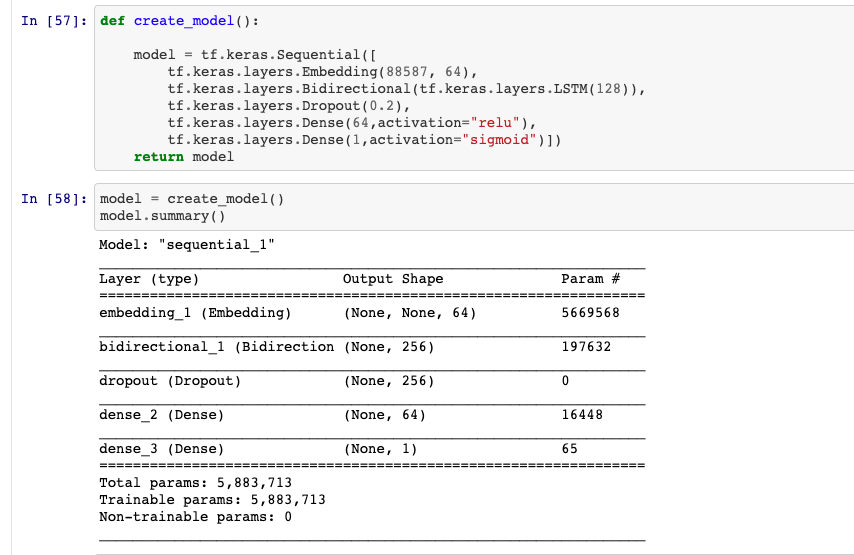
Model and Model Summary
Splitting Data and Fitting the Model
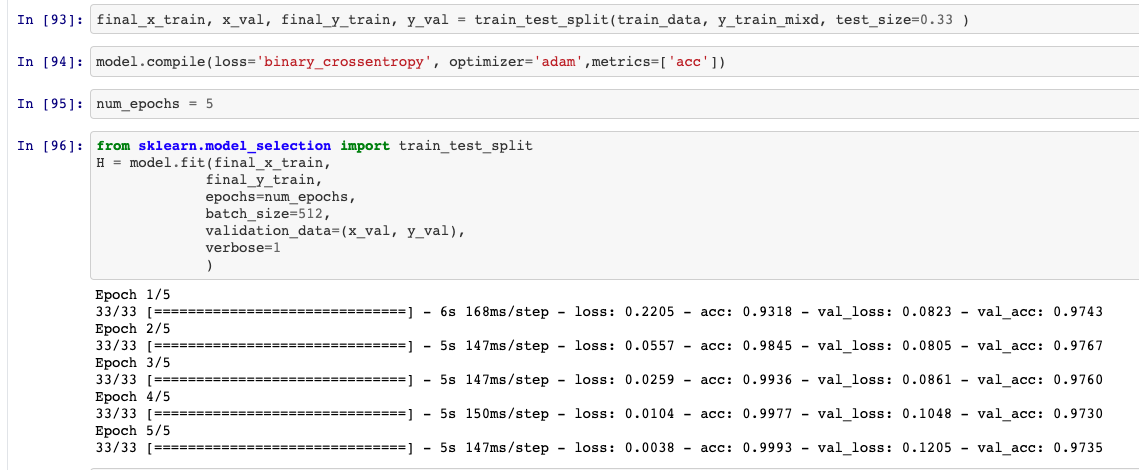
Model Effect Overview
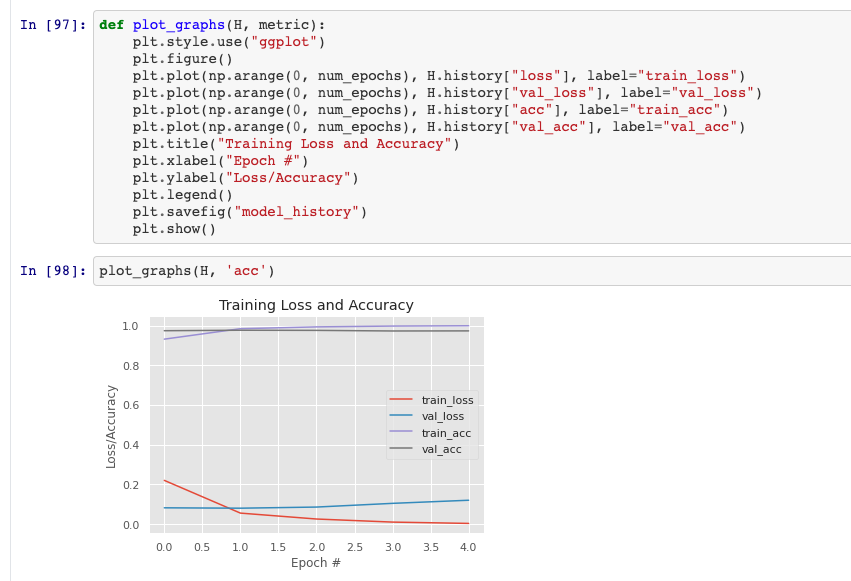
Confusion Matrix and Correlation Report
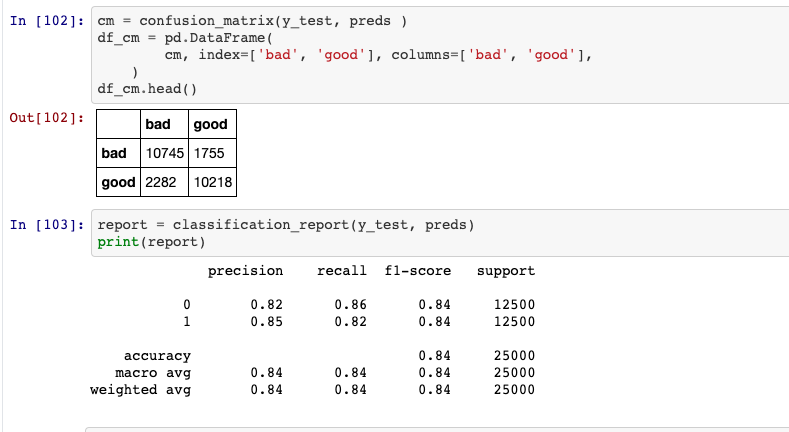
Note: Data Source and Data for this model is publicly available and can be accessed by using Tensorflow. For the complete code and details, please follow this GitHub Repository.
Conclusion
In conclusion, NLP is a field full of opportunities. NLP has a tremendous effect on how to analyze text and speeches. NLP is doing better and better every day. Knowledge extraction from the large data set was impossible five years ago. The rise of the NLP technique made it possible and easy. There are still many opportunities to discover in NLP.
If you want to learn advanced topics in NLP and AI, then enroll in our Blackbelt Plus program! You can also explore our other data science and NLP courses here.
Frequently Asked Questions
A. Text classification is the process of categorizing text into predefined classes or categories. It includes binary classification (two classes) and multiclass classification (more than two classes).
A. An example of text classification is classifying emails as spam or not spam. Another is sentiment analysis, where texts are categorized as positive, negative, or neutral.
A. Text classification is vital in organizing, understanding, and extracting insights from large volumes of text data, enhancing applications like content filtering, sentiment analysis, and topic labeling.
A. There’s no one-size-fits-all algorithm. Common algorithms include Naive Bayes, Support Vector Machines (SVM), and deep learning models like Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN). The best choice depends on the specific dataset and task.













