Exploring Ensemble Learning in Machine Learning World!
This article was published as a part of the Data Science Blogathon.
Introduction
Before getting starts with “Ensemble Techniques” in Machine Learning (ML) space. Let try to understand the meaning of the Ensemble in simple terminology, so that we could correlate it with ML. Are you ready!
Ensemble – “A group of items viewed as a whole rather than individually.”. In the below picture a group of people who work or perform together, from the same instrument family.
The term is widely used in the musical world and best fit too. Just find the real meaning of Ensemble in the dictionary, you can understand it better.

Ensemble in Machine Learning
Now let’s compare this within our Machine Learning world. As a group of people in orchestra are performing the synchronize and giving best performance out of them, likewise ensemble methods are techniques, that create multiple models and then combine them to produce an improved version of results for our model. It helps us to produces more quality and accurate solutions than a single model.
Ensemble Learning: is a group of predictors that are trained and used for predictions in ML
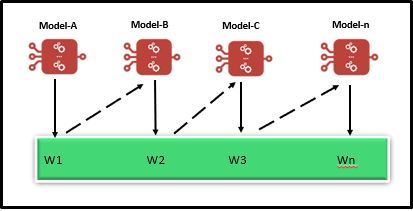
Simple Understanding of Ensemble Learning
A simple representation of this technique is below.
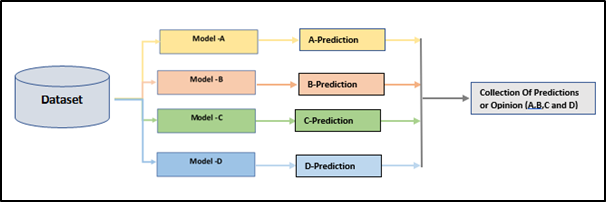
Simple representation
Here a models A, B, C, and D could be anyone of the following Machining Learning algorithm as we are familiar with Logistic Regression, Decision Tree, Random Forest, SVM, etc. It makes sense to us that a group of learners (weak) comes together and to form a stronger community learner, as a result of increasing the accuracy of any Machine Learning model.
Ensemble Exercise
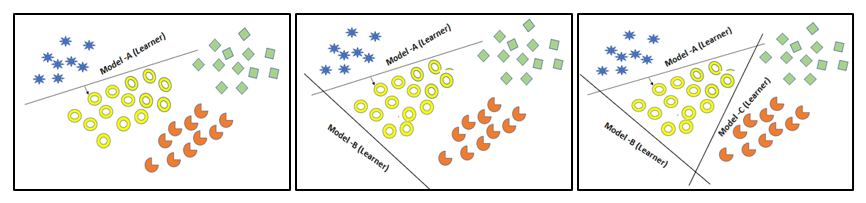
Ensemble Exercise
A quick flashback, hopes you all know the concept behind the Random Forest model. I mean arriving at the predictions of all individual trees of the decision tree model, taking votes from this group, and predicting the class. This is one way of the ensemble, through the decision tree model and so-called Random Forest.
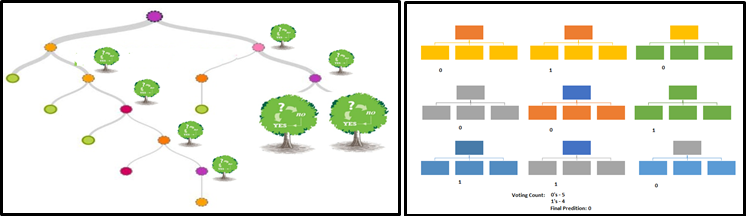
Random Forest
Categories of Ensemble Learning
A strong recommendation for Ensemble Learning as follows, If the predictors are independent, we could train them using a series of different algorithms. So, this approach would increase the chances of different types of errors, improving accuracy.
Let’s discuss the available Ensemble Learning. Before that let see high-level categories as a SEQUENTIAL and PARALLEL ensemble.
SEQUENTIAL ENSEMBLE TECHNIQUES: Sequentially generate the base learners as shown in the below diagram. In this sequential generation, the base learners are encouraging the dependency between the base learners. End of the day the performance of the model is then improved by assigning higher weights to previously misstated learners in the group.
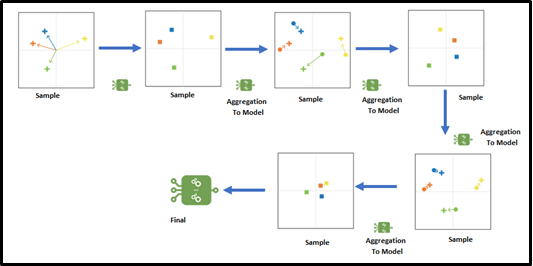
SEQUENTIAL ENSEMBLE TECHNIQUES
PARALLEL ENSEMBLE TECHNIQUES: In which the base learners are generated in parallel as like in Random Forest, as we know that the collection of decision tree makes random forest with base learners to encourage independence between the other base learners. here the error can be reduced dramatically by averaging.
One step ahead, we can classify ensemble as HOMOGENEOUS and HETEROGENEOUS ENSEMBLE based on the building the model
HOMOGENEOUS ENSEMBLE is a collection of classifiers of the same type, built upon a different subset of data as we use to do in the Random Forest model.
- Data 1 <> Data 2 <> Data 3 …… Data n
- Examples: Bagging and Boosting
HETEROGENEOUS ENSEMBLE is a set of classifiers of different types, built upon the same data.
- Data 1 = Data 2 = Data 3 …… Data n
- Examples: Stacking
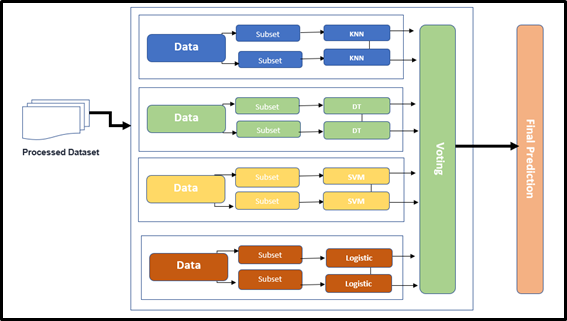
HETEROGENEOUS ENSEMBLE
Comparison of Homogeneous and Heterogeneous Ensemble

So far, we have discussed different category
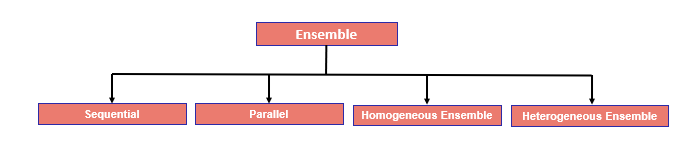
Different Category
Now, will move on to types in details,
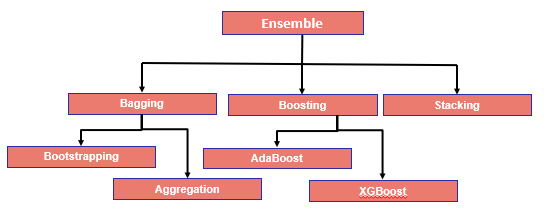
Types of Ensemble methods
Bagging: Which reduces the variance to a large extent level and eventually increases accuracy. So, it is eliminating overfitting, which was a big challenge in many predictive models. This is often considered as a homogeneous weak learner and learns them independently from each other in parallel and combines them following by averaging process
Further classified into two types as Bootstrapping and Aggregation.
- The key advantage of the method is the weak base learners are combined to form a single strong learner, which is more stable than single learners.
- As mentioned earlier, it also eliminates any variance and reducing the overfitting of models.
- Expensive computationally is the major challenge in this method.
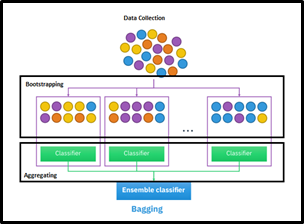
Bootstrapping is a sampling-based technique, where the samples are derived from the whole population using the replacement procedure. This replacement method helps make the selection procedure randomized. The base learning algorithm is run on the samples to complete the procedure.
Aggregation is based on the probability bootstrapping procedures (Shown in the above diagram) or based on all outcomes of the predictive models.
Boosting: Most widely used Ensemble method and powerful. Actually, speaking this was designed for classification problems and further extended to regression problem statement too. This is basically a combination of 3+ weak algorithms (learners) to generate a strong learner.
Available Boosting algorithms are AdaBoost, Gradient Boosting Machine (GBM), XGBoost, and Light GBM
The situation for Boosting, Let’s have a situation that first model predicted erroneous and followed by the second model as well predicted inaccurate, then will analyze these results by combining and extract the better prediction. This is nothing but Boosting overall results. Hence Boosting proves the ensemble core concepts as combining a weak learner into a stronger one.
Stacking [Stacked generalization]: Stacking is based on the normal way of training a model and perform the aggregation, as we have shown in the diagram – HETEROGENEOUS ENSEMBLE. In which we have two layers one is called the Base-model and Meta-model. The base-level models are trained based on a complete training set, then the meta-model is trained on the outputs of the base-level model, like features.
Since the base level often consists of different learning algorithms and therefore stacking ensembles are often called heterogeneous.
So, we understood different types of Ensemble Techniques!
Here the overall takeaway for you all,
- The target for the ensemble techniques is used to improving predictability in models by combining several models or training different sets of data with a single model to make one very strong model.
- In the ensemble technique, we used to apply either order to decrease variance, bias, or improve predictions.
- The most popular ensemble methods are in practice are Boosting, Bagging, And Stacking.
- Ensemble methods are suitable for regression and classification problems, where they are used to reduce variance and bias to enhance the accuracy of models.
Guys! Thanks for reading this article will discuss more in the upcoming blogs!
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.










