Out-of-the-box NLP functionalities for your project using Transformers Library!
This article was published as a part of the Data Science Blogathon.
Introduction
In this tutorial, you will learn how you can integrate common Natural Language Processing (NLP) functionalities into your application with minimal effort. We will be doing this using the ‘transformers‘ library provided by Hugging Face.
1. First, Install the transformers library.
# Install the library !pip install transformers

2. Next, import the necessary functions.
# Necessary imports from transformers import pipeline

3. Irrespective of the task that we want to perform using this library, we have to first create a pipeline object which will intake other parameters and give an appropriate output. The required model weights will be downloaded the first time when the code is run.
Sentiment Analysis
Here is an example of how you can easily perform sentiment analysis. Sentiment analysis is predicting what sentiment, a sentence falls in. In other words, the model tries to classify whether the sentence was positive or negative.
# Create pipeline instance
sentiment = pipeline('sentiment-analysis')
# Positive sentiment example
result = sentiment('I am really happy today')
print(result)
print()
# Negative sentiment example
result = sentiment('I am feeling kinda sad')
print(result)

Question Answering
Code for performing Question-Answering tasks. Use the template in the image given below. Enter your question in the ‘question’ key of the dictionary passed into the pipeline object and the reference material in the ‘context’ key.
q_and_a = pipeline('question-answering')
result = q_and_a({
'question': 'What is the purpose of this tutorial?',
'context': 'This tutorial lets you implement NLP functionalities with ease'
})
print(result)
print()
print(f"The answer to your question: {result['answer']}")

Masking
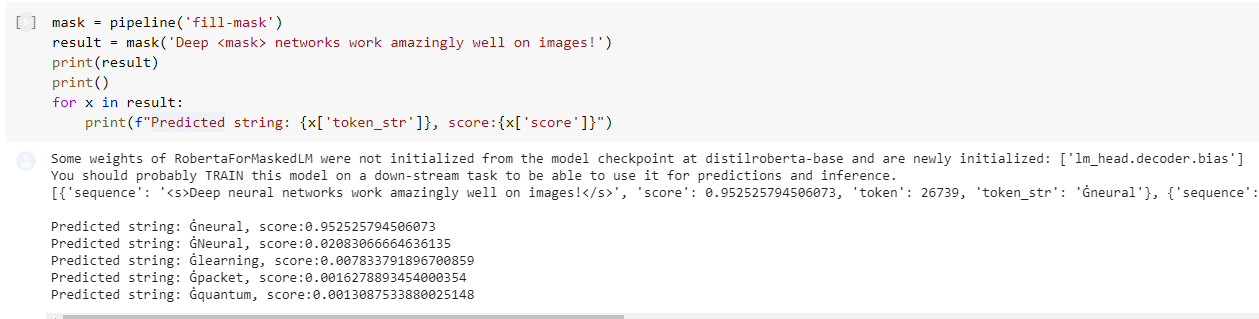
Code for masking, i.e., filling missing words in sentences. The missing word to be predicted is to be represented using ‘<mask>’ as shown in the code execution image below.
mask = pipeline('fill-mask')
result = mask('Deep <mask> networks work amazingly well on images!')
print(result)
print()
for x in result:
print(f"Predicted string: {x['token_str']}, score:{x['score']}")
Named Entity Recognition
Implementing Named Entity Recognition (NER). Named Entity Recognition deals with extracting entities from a given sentence. For Example, ‘Adam‘ would be extracted as a ‘name’, and ‘19‘ would be extracted as a ‘number’.
ner = pipeline('ner')
result = ner('Analytics Vidhya is a company in India')
print(result)

Text Summarization
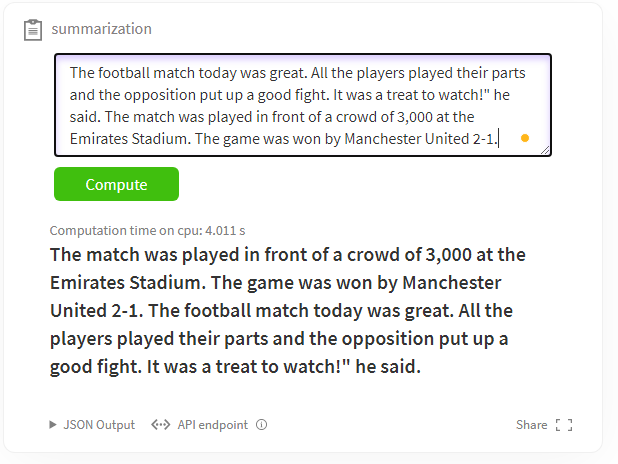
These were some of the common out-of-the-box NLP functionalities that you can easily implement using the transformers library. There are many other functionalities, and you can check them out at the Hugging Face website. Here is an example of ‘Text Summarization‘. Text Summarization takes in a passage as input and tries to summarize it.
Great! Now, you can integrate NLP functionalities with high performance directly in your applications.
Related Links:
- Notebook Link for directly running the code in Google Colaboratory.
- You can watch almost all the functionalities shown in this tutorial in this youtube video made by ‘MLNerdie Delhi‘.
- You can have a look at all the models provided by Hugging face and try them on their website.
- Github repo link of the transformers library.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.







