Beginner’s Guide to Clustering in R Program
This article was published as a part of the Data Science Blogathon.

R you ready? Let’s learn clustering in R.
What is R?
R is a language primarily used for data analysis, made for statistics and graphics in 1993. It is a very analysis-friendly language. Its software is RStudio which is freely available and can be downloaded through:
Data Visualisation using R
In the current times, images speak louder than numbers or word analysis. Yes, graphs and plots are more catchy and relatable to the human eye. Here is where the importance of R data analysis comes in. Clients understand graphical representation of their growth/product assessment/distribution better. Thus, data science is booming nowadays and R is one such language that provides flexibility in plotting and graphs as it has specific functions and packages for such tasks. RStudio is software where data and visualization occur side by side making it very favorable for a data analyst. Scatterplots, boxplots, bar graphs, line graphs, line charts, heat maps, etc are all possible in R with just a simple function eg: Histogram can be plotted by the function hist(data name) with parameters like xlab(x label), color, border, etc.
Taking advantage of this convenience let us further proceed into an Unsupervised learning method – Clustering.
Supervised and Unsupervised learning
There are two types of learnings in data analysis: Supervised and Unsupervised learning.
Supervised learning – Labeled data is an input to the machine which it learns. Regression, classification, decision trees, etc. are supervised learning methods.
Example of supervised learning:
Linear regression is where there is only one dependent variable. Equation: y=mx+c, y is dependent on x.
Eg: The age and circumference of a tree are the 2 labels as input dataset, the machine needs to predict the age of a tree with a circumference as input after learning the dataset it was fed. The age is dependent on the circumference.
The learning thus is supervised on the basis of the labels.
Unsupervised learning – Unlabeled data is fed to the machine to find a pattern on its own. Clustering is an unsupervised learning method having models – KMeans, hierarchical clustering, DBSCAN, etc.
Visual representation of clusters shows the data in an easily understandable format as it groups elements of a large dataset according to their similarities. This makes analysis easy. Unsupervised learning is not always accurate though and is a complex process for the machine as data is unlabeled.
Let us now continue to a clustering example using the Iris flower dataset.
Clustering in R
Clusters are a group of the same items or elements like a cluster of stars or a cluster of grapes or a cluster of networks and so on…
Real-world use of clustering:
It is used in e-commerce sites to form groups of customers based on their profile like age, gender, spending, regularity so on. It is useful in marketing and sales as it helps cluster the target audience for the product. Spam filtering in mails and many more are real-world applications of clustering.
Clustering in R refers to the assimilation of the same kind of data in groups or clusters to distinguish one group from the others(gathering of the same type of data). This can be represented in graphical format through R. We use the KMeans model in this process.
What is the K Means algorithm?
K Means is a clustering algorithm that repeatedly assigns a group amongst k groups present to a data point according to the features of the point. It is a centroid-based clustering method.
The number of clusters is decided, cluster centers are selected in random farthest from one another, the distance between each data point and center is calculated using Euclidean distance, the data point is assigned to the cluster whose center is nearest to that point. This process is repeated until the center of clusters does not change and data points remain in the same cluster.
All this is theory but in practice, R has a clustering package that calculates the above steps.
Step 1
I will work on the Iris dataset which is an inbuilt dataset in R using the Cluster package. It has 5 columns namely – Sepal length, Sepal width, Petal Length, Petal Width, and Species. Iris is a flower and here in this dataset 3 of its species Setosa, Versicolor, Verginica are mentioned. We will cluster the flowers according to their species. The code to load the dataset:
data("iris")
head(iris) #will show top 6 rows only
Step 2
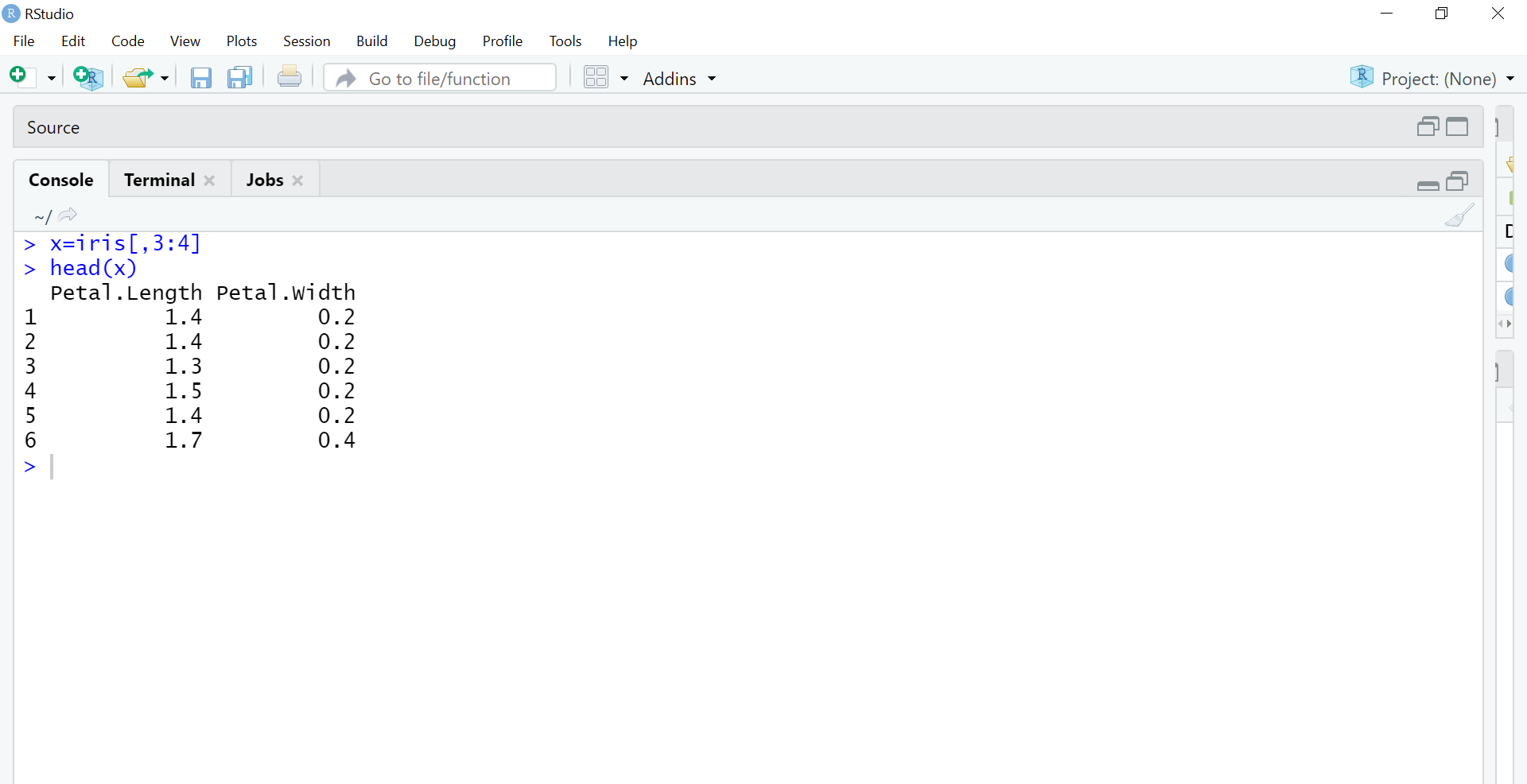
The next step is to separate the 3rd and 4th columns into separate object x as we are using the unsupervised learning method. We are removing labels so that the huge input of petal length and petal width columns will be used by the machine to perform clustering unsupervised.
x=iris[,3:4] #using only petal length and width columns head(x)
Step 3
The next step is to use the K Means algorithm. K Means is the method we use which has parameters (data, no. of clusters or groups). Here our data is the x object and we will have k=3 clusters as there are 3 species in the dataset.
Then the ‘cluster’ package is called. Clustering in R is done using this inbuilt package which will perform all the mathematics. Clusplot function creates a 2D graph of the clusters.
model=kmeans(x,3) library(cluster) clusplot(x,model$cluster)
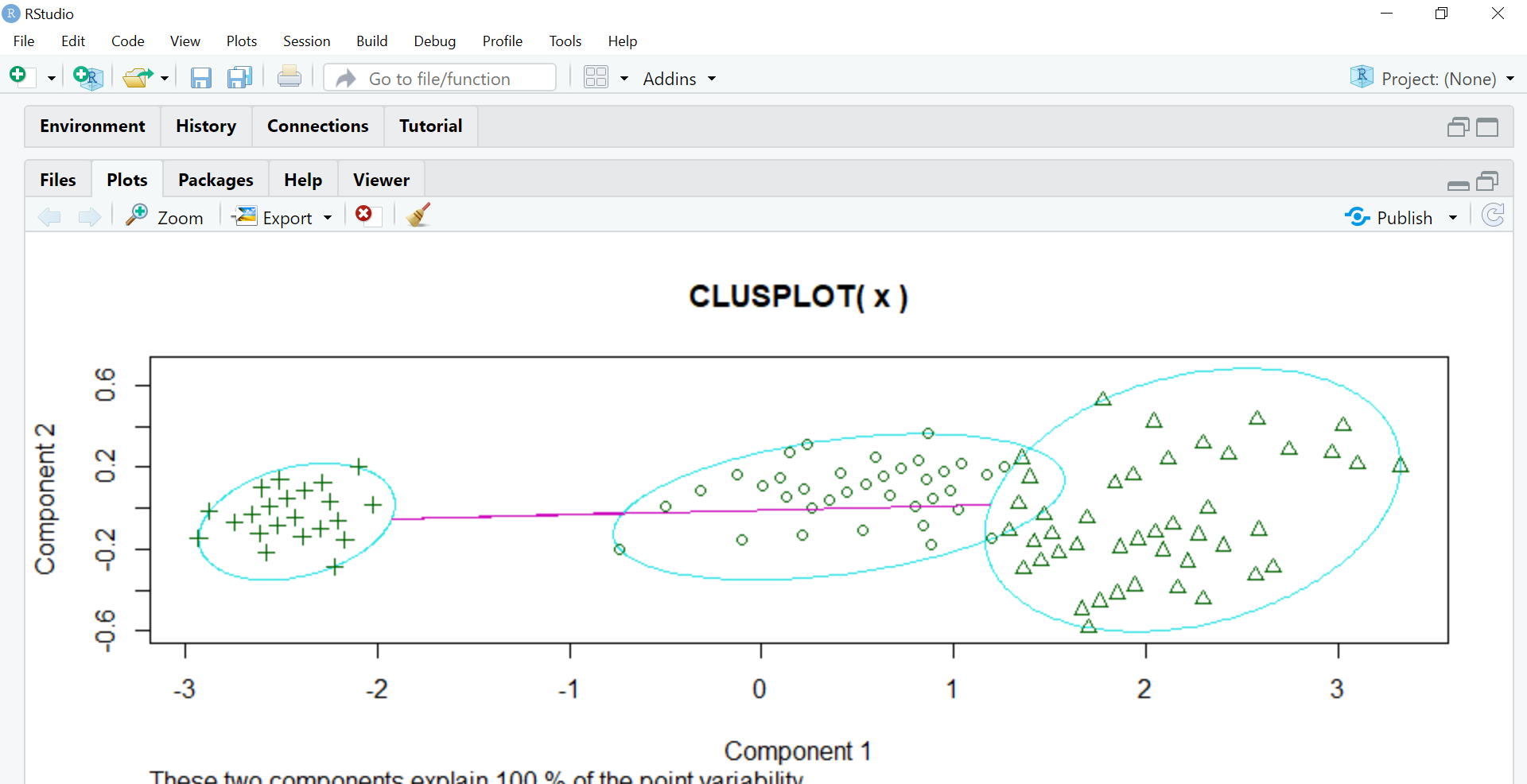
Component 1 and Component 2 seen in the graph are the two components in PCA (Principal Component Analysis) which is basically a feature extraction method that uses the important components and removes the rest. It reduces the dimensionality of the data for easier KMeans application. All of this is done by the cluster package itself in R.
These two components explain 100% variability in the output which means the data object x fed to PCA was precise enough to form clear clusters using KMeans and there is minimum (negligible) overlapping amongst them.
Step 4
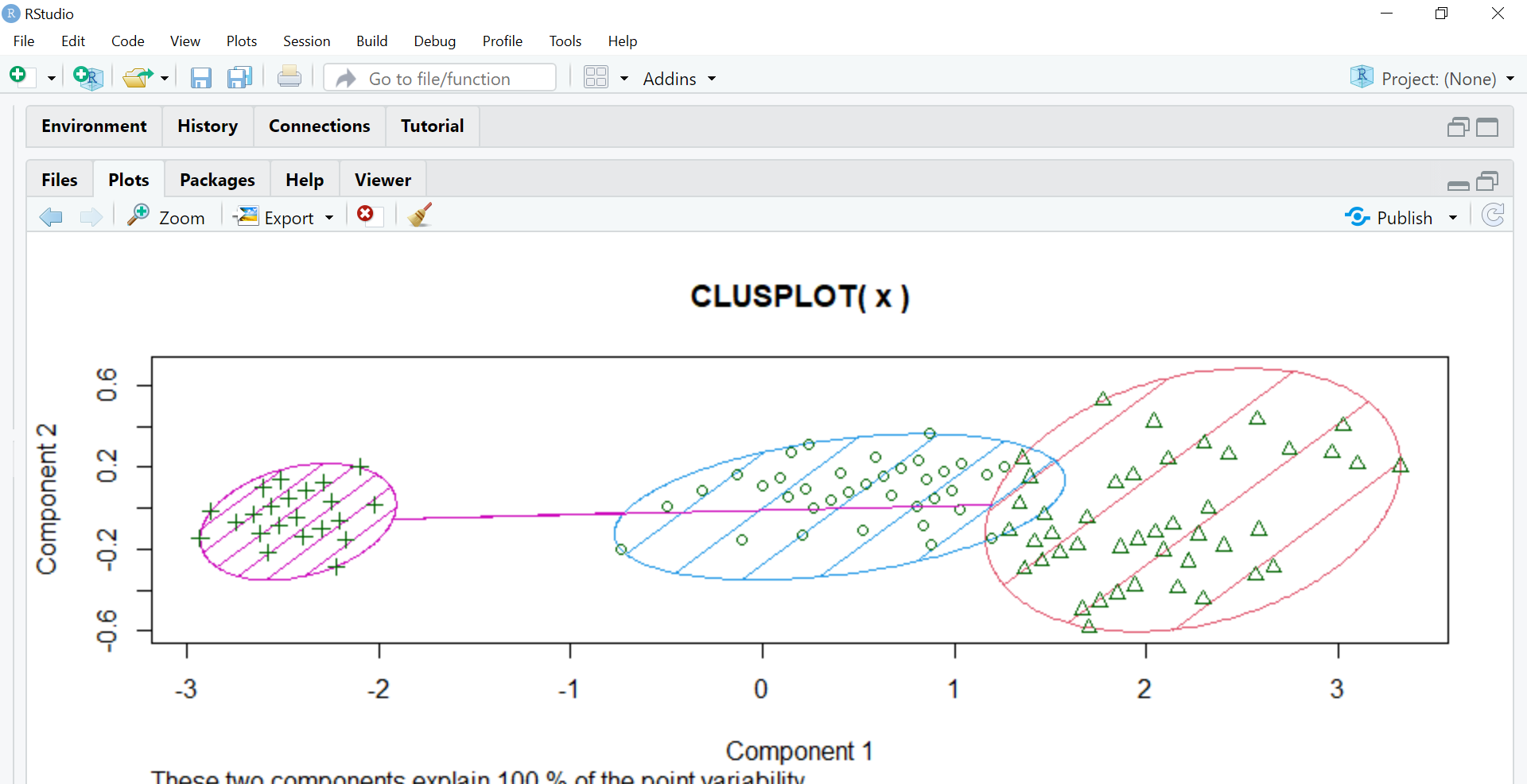
The next step is to assign different colors to the clusters and shading them hence we use the color and shade parameters setting them to T which means true.
clusplot(x,model$cluster,color=T,shade=T)
Frequently Asked Questions
A. Clustering in R refers to the process of grouping similar data points together based on their characteristics. R, a programming language for statistical computing and graphics, offers various clustering algorithms like k-means, hierarchical clustering, and DBSCAN. These methods help uncover patterns and structures within data by partitioning it into distinct clusters, aiding in tasks like segmentation, pattern recognition, and data exploration.
A. To use clustering in R:
1. Load Data: Import your data into R using functions like read.csv().
2. Preprocess Data: Clean and preprocess the data if needed.
3. Choose Clustering Method: Select a clustering algorithm like k-means, hierarchical clustering, or DBSCAN.
4. Feature Scaling: Normalize or standardize data for algorithms sensitive to scale.
5. Apply Clustering Algorithm: Use functions like kmeans() or hclust() to perform clustering.
6. Visualize Results: Plot clusters using tools like plot() or visualize dendrograms for hierarchical clustering.
7. Evaluate Clusters: Assess the quality of clusters using metrics like silhouette score or domain-specific evaluation.
8. Interpret Results: Analyze clusters to gain insights about patterns and relationships within the data.
Conclusion
All this sums up the basics of clustering in R. Here I use an inbuilt dataset but imported datasets can be used for clustering too. Eg: clustering the users of a site based on items favored and so on. It is very useful for business comparisons.
Importing datasets in R:
dataset <- read.csv("path.csv")
View(dataset)
attach(dataset)
Thanks for taking out time and reading this article ,feel free to comment on what further can be improved as learning is an everyday processafterall..
ConnectwithmeonLinkedIn:https://www.linkedin.com/in/akansha-bose-149b14164/
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.








Heartly thanks for such nice explanation in simple wording with example.
I came to this page to solve a small problem and your code did exactly what I'd hoped It just worked with my 25000 row dataset! Many thanks Duncan