Interesting NLP Use Cases Every Data Science Enthusiast should know!
This article was published as a part of the Data Science Blogathon
Introduction
Natural Language Processing (NLP) is a subpart of Artificial Intelligence that uses algorithms to understand and process human language. Various computational methods are used to process and analyze human language and a wide variety of real-life problems are solved using Natural Language Processing.

Using Natural Language Processing, we use machines by making them understand how human language works. Basically, we use text data and make computers analyze and process large quantities of such data. There is high demand for such data in today’s world as such data contains a vast amount of information and insight into business operations and profitability.
Importance of NLP :
Natural Language Processing has made things very easy in our modern life. Remember the time, when you typed the first few phrases of a question in Google, and Google guessed the remaining question. That is by NLP.
How Gmail now provides sample replies to the emails you receive, is also thanks to NLP. NLP has made our lives a lot easier in the technology we use in our day-to-day lives.
There are a lot of uses of NLP. Let us have a look at some interesting NLP uses.
NLP Uses :
Grammar Correction Tools
Grammar correction tools are one of the most widely used applications of NLP. Such tools check errors in our text and give suggestions on which corrections are to be made. These tools are already fed with data about correct grammar and know between correct and incorrect usage.
Grammarly is one of the most common tools in this scenario. Grammar correction tools are of immense use and utility to all. Everyone starting from students to senior executives can use them to make their writing better and crisp.
With grammar tools, the quality of writing improves drastically and many people are interested in the paid version of the product, leading to better revenues.
Grammarly is a cloud-based grammar correction tool. According to them, their team of linguists and deep learning engineers design algorithms that learn the rules and patterns of good writing, by analyzing millions of sentences from research text.
It also learns with data, every time a user accepts or ignores a suggestion given by Grammarly, the AI gets smarter. The exact functioning of the AI is not revealed, but surely it uses a lot of NLP techniques.

Text Summarisation
Text Summarisation is an interesting application of NLP. Often, you want to submit an essay or write an article, but there seems to be a limit to the length of the text you can submit.
Text Summarization is the process of condensing a long piece of text into a shorter version, preserving the basic idea of the text and still containing all the key points.
Manual text summarization is often very expensive and time-consuming and a tedious job. The large amount of text data available in today’s modern world of big data is enormous. This huge amount of text data has a large potential for business growth and useful analytics. Automatic text summarization has huge potential these days.
Text Compactor is a good and useful tool for text summarization. Do check out. Text Summaries reduce reading time, make the selection process easier in many cases. With better computational resources and better research, the summary can be as good as written by a human. There are mainly two types of Text Summarization :
1. Extractive Methods.
2. Abstractive Methods.
In Extractive methods, algorithms use sentences and phrases from the source text to create the summary. The algorithm uses word frequency, the relevance of phrases, and other parameters to arrive at the summary.
Summarization by abstractive methods is a way of summary creation by the generation of new sentences and phrases as compared to the source document. This type of method is often more difficult to execute and needs more advanced approaches like Deep Learning.
Implementing The Text Summarizer
One of the most simple ways to implement a text summarizer is to create a summarizer based on using the sentences with the most weightage. Weightage is calculated by taking words with the most usage in the original text. The code :
import docx2txt import re import heapq import nltk import docx
text= docx2txt.process("Text Input.docx")
#Removing thw Square Brackets and Extra Spaces article_text = re.sub(r'[[0-9]*]', ' ', text) article_text = re.sub(r's+', ' ',article_text ) #Sentence tokenization sentence_list = nltk.sent_tokenize(article_text)
#Now we need to find the frequency of each word before it was tokenized into sentences
#Word frequency
#Also we are removing the stopwords from the text we are using
stopwords = nltk.corpus.stopwords.words('english')
#Storing the word frequencies in a dictionary
word_frequencies = {}
for word in nltk.word_tokenize(article_text):
if word not in stopwords:
if word not in word_frequencies.keys():
word_frequencies[word] = 1
else:
word_frequencies[word] += 1
#Now we need to find the weighted frequency #We shall divide the number of occurances of all the words by the frequency of the most occurring word
maximum_frequncy = max(word_frequencies.values())
for word in word_frequencies.keys():
word_frequencies[word] = (word_frequencies[word]/maximum_frequncy)
#Using relative word frequency, not absolute word fequency so as to distribute the values from 0-1
#Calculating Sentence Scores
#Scores for each sentence obtained by adding weighted frequencies of the words that occur in that particular sentence.
sentence_scores = {}
for sent in sentence_list:
for word in nltk.word_tokenize(sent.lower()):
if word in word_frequencies.keys():
if len(sent.split(' ')) < 25:
if sent not in sentence_scores.keys():
sentence_scores[sent] = word_frequencies[word]
else:
sentence_scores[sent] += word_frequencies[word]
#To summarize the article we are going to take the sentences with 10 highest scores
#This parameter can be changed according to the length of the text
summary_sent = heapq.nlargest(10, sentence_scores, key=sentence_scores.get)
summary = ' '.join(summary_sent)
print(summary)
mydoc = docx.Document()
mydoc.add_paragraph(summary)
mydoc.save("Text Output.docx")
The overall logic is simple. The code extracts the input code from a text document. Text is processes and stopwords are removed. Then the word frequencies are calculated in each sentence and sentences are given a sentence score. The number of sentences in the summary can also be decided. Ultimately the summary text is written to another doc file.
The sample below taken from the Ferrari Wikipedia page shows an implementation of the code.
A sample input fed into the code:
Enzo Ferrari was not initially interested in the idea of producing road cars when he formed Scuderia Ferrari in 1929, with headquarters in Modena. Scuderia Ferrari (pronounced [skudeˈriːa]) literally means "Ferrari Stable" and is usually used to mean "Team Ferrari." Ferrari bought,[citation needed] prepared, and fielded Alfa Romeo racing cars for gentleman drivers, functioning as the racing division of Alfa Romeo. In 1933, Alfa Romeo withdrew its in-house racing team and Scuderia Ferrari took over as its works team:[1] the Scuderia received Alfa's Grand Prix cars of the latest specifications and fielded many famous drivers such as Tazio Nuvolari and Achille Varzi. In 1938, Alfa Romeo brought its racing operation again in-house, forming Alfa Corse in Milan and hired Enzo Ferrari as manager of the new racing department; therefore the Scuderia Ferrari was disbanded.[1] The first vehicle made with the Ferrari name was the 125 S. Only two of this small two-seat sports/racing V12 car were made. In 1949, the 166 Inter was introduced marking the company's significant move into the grand touring road car market. The first 166 Inter was a four-seat (2+2) berlinetta coupe with body work designed by Carrozzeria Touring Superleggera. Road cars quickly became the bulk of Ferrari sales. The early Ferrari cars typically featured bodywork designed and customised by independent coachbuilders such as Pininfarina, Scaglietti, Zagato, Vignale and Bertone. The original road cars were typically two-seat front-engined V12s. This platform served Ferrari very well through the 1950s and 1960s. In 1968 the Dino was introduced as the first two-seat rear mid-engined Ferrari. The Dino was produced primarily with a V6 engine, however, a V8 model was also developed. This rear mid-engine layout would go on to be used in many Ferraris of the 1980s, 1990s and to the present day. Current road cars typically use V8 or V12 engines, with V8 models making up well over half of the marque's total production. Historically, Ferrari has also produced flat 12 engines. In September 1939, Ferrari left Alfa Romeo under the provision he would not use the Ferrari name in association with races or racing cars for at least four years.[1] A few days later he founded Auto Avio Costruzioni, headquartered in the facilities of the old Scuderia Ferrari.[1] The new company ostensibly produced machine tools and aircraft accessories. In 1940, Ferrari produced a race car – the Tipo 815, based on a Fiat platform. It was the first Ferrari car and debuted at the 1940 Mille Miglia, but due to World War II it saw little competition. In 1943, the Ferrari factory moved to Maranello, where it has remained ever since. The factory was bombed by the Allies and subsequently rebuilt including works for road car production. 125 S replica 166 MM Touring Barchetta The first series produced Ferrari, the 1958 250 GT Coupé The first Ferrari-badged car was the 1947 125 S, powered by a 1.5 L V12 engine;[1] Enzo Ferrari reluctantly built and sold his automobiles to fund Scuderia Ferrari.[18] The Scuderia Ferrari name was resurrected to denote the factory racing cars and distinguish them from those fielded by customer teams. In 1960 the company was restructured as a public corporation under the name SEFAC S.p.A. (Società Esercizio Fabbriche Automobili e Corse).[19] Early in 1969, Fiat took a 50% stake in Ferrari. An immediate result was an increase in available investment funds, and work started at once on a factory extension intended to transfer production from Fiat's Turin plant of the Ferrari engined Fiat Dino. New model investment further up in the Ferrari range also received a boost. In 1988, Enzo Ferrari oversaw the launch of the Ferrari F40, the last new Ferrari launched before his death later that year. In 1989, the company was renamed Ferrari S.p.A.[19] From 2002 to 2004, Ferrari produced the Enzo, their fastest model at the time, which was introduced and named in honor of the company's founder, Enzo Ferrari. It was to be called the F60, continuing on from the F40 and F50, but Ferrari was so pleased with it, they called it the Enzo instead. It was initially offered to loyal and recurring customers, each of the 399 made (minus the 400th which was donated to the Vatican for charity) had a price tag of $650,000 apiece (equivalent to £400,900). On 15 September 2012, 964 Ferrari cars worth over $162 million (£99.95 million) attended the Ferrari Driving Days event at Silverstone Circuit and paraded round the Silverstone Circuit setting a world record.[20] Ferrari's former CEO and Chairman, Luca di Montezemolo, resigned from the company after 23 years, who was succeeded by Amedeo Felisa and finally on 3 May 2016 Amedeo resigned and was succeeded by Sergio Marchionne, CEO and Chairman of Fiat Chrysler Automobiles, Ferrari's parent company.[21] In July 2018, Marchionne was replaced by board member Louis Camilleri as CEO and by John Elkann as chairman.
The output:
Ferrari bought,[citation needed] prepared, and fielded Alfa Romeo racing cars for gentleman drivers, functioning as the racing division of Alfa Romeo. The early Ferrari cars typically featured bodywork designed and customised by independent coachbuilders such as Pininfarina, Scaglietti, Zagato, Vignale and Bertone. In 1940, Ferrari produced a race car – the Tipo 815, based on a Fiat platform. The Dino was produced primarily with a V6 engine, however, a V8 model was also developed. In 1988, Enzo Ferrari oversaw the launch of the Ferrari F40, the last new Ferrari launched before his death later that year. In 1943, the Ferrari factory moved to Maranello, where it has remained ever since. Current road cars typically use V8 or V12 engines, with V8 models making up well over half of the marque's total production. In 1949, the 166 Inter was introduced marking the company's significant move into the grand touring road car market. Enzo Ferrari was not initially interested in the idea of producing road cars when he formed Scuderia Ferrari in 1929, with headquarters in Modena. It was the first Ferrari car and debuted at the 1940 Mille Miglia, but due to World War II it saw little competition.
The code determined the 10 most suitable sentences and used them to form the summary. This summary is made using an Extractive method, as the summary contains sentences from the original text.
Text Analytics
Text Analytics is the process of gathering useful data and insights from text data. Businesses often have a large amount of data at their disposal, examples of text data would include customer product reviews, chatbot data, customer suggestion mails, and more.
Text analytics can be used to understand and identify data patterns and make business decisions. These methods include word/phase-frequency calculation, word cloud generation, sentiment analysis, and others. Also, it gives a good way to work with a large amount of text data.
In the process of Text analytics, the source text or documents are processed, then various NLP methods are applied to them. Firstly, useless punctuation and symbols are removed. If the text happens to be web-scraped, there will be a lot of HTML, which has to be cleaned. Punctuation cleaning methods are then applied.
Then stopwords are to be removed. Stopwords are the most common words in a language, and often do not portray any sentiment. Stopwords in English are and, on, the, that, at, is, in, etc. There are various ways and algorithms to remove these stopwords from our text. Stemming and Lemmatization are also among the important steps in cleaning the text for analytics. With all the basic NLP techniques, the text becomes ready to be processed and worked upon.
Text Analytics using Power BI
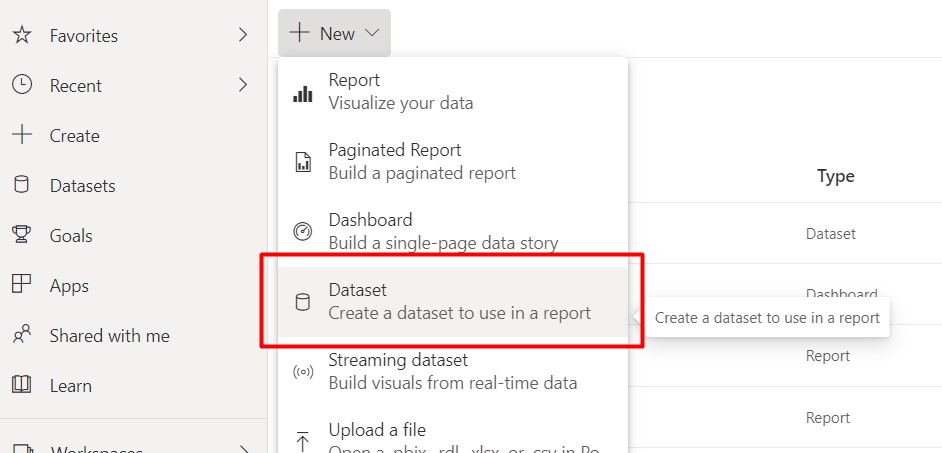
Let us work on some text analytics using Power BI. The dataset we are taking is the Pfizer and BioNTech Vaccine Tweets dataset from Kaggle. Dataset link: Pfizer Vaccine Tweets.
After downloading the data, we add the data to the Power BI service workspace.
Now we shall be working with one of the most simple and easy to implement Text Analytics method: A word cloud.
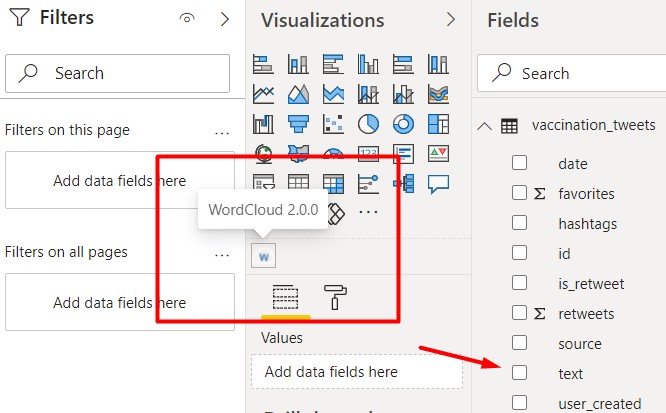
We drag and drop the WordCloud visual to the workspace.
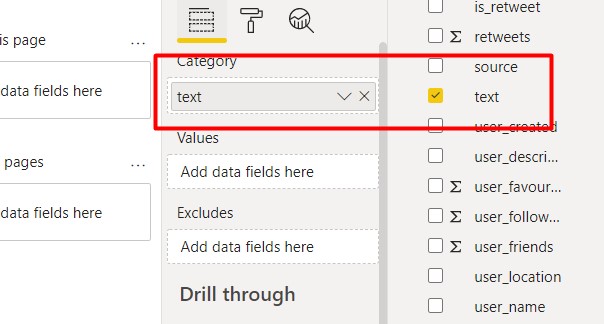
Now, as the “text” field contains the tweet text, we will drag and drop it into the Category area. One of the best things about the Word Cloud visual is that the frequency of the words decides which words will be in the Word Cloud and the size of the words is decided by the frequency.
We set the maximum number of words to 150. This indicates that the top 150 words which appeared the most will be present in the word cloud.
Now we remove the stopwords from the text. Stopwords are the most common words in a language that are needed for basic grammar and sentence structure. In English, common stopwords are “the”, “is”, “but” , “is”, “at” etc.
Now with the stopwords removed, the Word Cloud looks like this :

Here we can see a wide variety of vaccine technicalities and other stuff. The point to be noted is that “HTTPS” appears the largest as users might have shared websites and such, which led to it appearing the most.
Chatbots
Businesses need to have a strong customer helpline and support network. Chatbots are an integral part of a strong customer support network. Virtual assistants and chatbots are part of most online services and apps these days.
Chatbots have Natural Language Generation capabilities via which they can converse with a human customer or client and solve their problem or understand their problem before a human executive can take over. Chatbots are trained with probable questions and answers to those questions. Companies like Zomato have efficient chatbots that can solve a wide variety of queries.
Chatbots can make the user experience easier and more convenient, making the whole business more efficient. Automated chatbots can stay online 24/7, all 365 days of the year, something which human support executives can never do (a single person considered).

Chatbots are very efficient in capturing leads and converting them into customers for the business. With better technology, chatbots are getting more and more cost-effective and easy to interact with. The data fed to the chatbot is text data in form of user queries and user doubts.
The exact functioning of different chatbots might be different, but all follow a database or algorithm in which, when the user input is passed, a response is given which solves a business problem.
Market Research and Market Intelligence
Companies use various NLP methods to analyze news and happenings in the market in an attempt to stay ahead of their competition. NLP tools monitor all the press releases, news reports, and competitor’s social media handles to get an idea of the market. With these data, companies and adjust their strategy to gain an edge over their competition.
Topic Modelling and Content Themes
Often companies want to gain more and more traffic from SEO to their websites. A good content strategy is important for that. Topic extraction can help in the identification of the most well-performing content on the internet for the marketing teams to decide on. Companies can understand audience intentions and use the data to better serve the needs of customers and audience. Using such data, better content themes can be identified and lead to better marketing strategies.
Email Classification
It is not a new thing today that our inbound emails get classified into our primary inbox, promotions, and spam inbox. Ever wondered? how does it happen? Well, NLP is at play here as well. Basically, it is a classification problem. Based on old data and other parameters, the AI is trained to identify the type of inbound mail. Spam mail tends to have a lot of irrelevant messages and unclear outbound links. Similarly, commercial and promotional emails tend to have promotional content, like coupons, discount offers. With the help of NLP, such messages are identified. The AI, based on the text content, can make the classification.
These are some of the most interesting NLP applications, there are many more interesting applications of NLP.
About me
Prateek Majumder
Data Science and Analytics | Digital Marketing Specialist | SEO | Content Creation
Connect with me on Linkedin.
Thank You.
The media shown in this article on K-Means Clustering Algorithm are not owned by Analytics Vidhya and are used at the Author’s discretion.
Prateek is a final year engineering student from Institute of Engineering and Management, Kolkata. He likes to code, study about analytics and Data Science and watch Science Fiction movies. His favourite Sci-Fi franchise is Star Wars. He is also an active Kaggler and part of many student communities in College.







