Data Extraction from Unstructured PDFs
This article was published as a part of the Data Science Blogathon
Introduction:
Data Extraction is the process of extracting data from various sources such as CSV files, web, PDF, etc. Although in some files, data can be extracted easily as in CSV, while in files like unstructured PDFs we have to perform additional tasks to extract data from PDF Python.
There are a couple of Python libraries using which you can extract data from PDFs. For example, you can use the PyPDF2 library for extracting text from PDFs where text is in a sequential or formatted manner i.e. in lines or forms. You can also extract tables in PDFs through the Camelot library. In all these cases data is in structured form i.e. sequential, forms or tables.
However, in the real world, most of the data is not present in any of the forms & there is no order of data. It is present in unstructured form. In this case, it is not feasible to use the above python libraries since they will give ambiguous results. To analyze unstructured data, we need to convert it to a structured form.
As such, there is no specific technique or procedure for extracting data from unstructured PDFs since data is stored randomly & it depends on what type of data you want to extract from PDF.
Here, I will show you a most successful technique & a python library through which you can extract data from bounding boxes in unstructured PDFs and then performing data cleaning operation on extracted data and converting it to a structured form.
Table of contents
PyMuPDF:
I have used the PyMuPDF library for this purpose. This library provided many applications such as extracting images from PDF, extracting texts from different shapes, making annotations, draw a bounded box around the texts along with the features of libraries like PyPDF2.
Now, I will show you how I extracted data from the bounding boxes in a PDF with several pages.
Here are the PDF and the red bounding boxes from which we need to extract data.



I have tried many python libraries like PyPDF2, PDFMiner, pikepdf, Camelot, and tabulat. However, none of them worked except PyMuPDF to extract data from PDF using Python.
Before going into the code it’s important to understand the meaning of 2 important terms which would help in understanding the code.
Word: Sequence of characters without space. Ex – ash, 23, 2, 3.
Annots: An annotation associates an object such as a note, image, or bounding box with a location on a page of a PDF document, or provides a way to interact with the user using the mouse and keyboard. The objects are called annots.
Please note that in our case the bounding box, annots, and rectangles are the same thing. Therefore, these terms would be used interchangeably.
First, we will extract text from one of the bounding boxes. Then we will use the same procedure to extract data from all the bounding boxes of pdf.
Code:
import fitz
import pandas as pd
doc = fitz.open('Mansfield--70-21009048 - ConvertToExcel.pdf')
page1 = doc[0]
words = page1.get_text("words")
Firstly, we import the fitz module of the PyMuPDF library and pandas library. Then the object of the PDF file is created and stored in doc and 1st page of pdf is stored on page1. page.get_text() extracts all the words of page 1. Each word consists of a tuple with 8 elements.
In words variable, the First 4 elements represent the coordinates of the word, 5th element is the word itself, 6th,7th, 8th elements are block, line, word numbers respectively.
OUTPUT
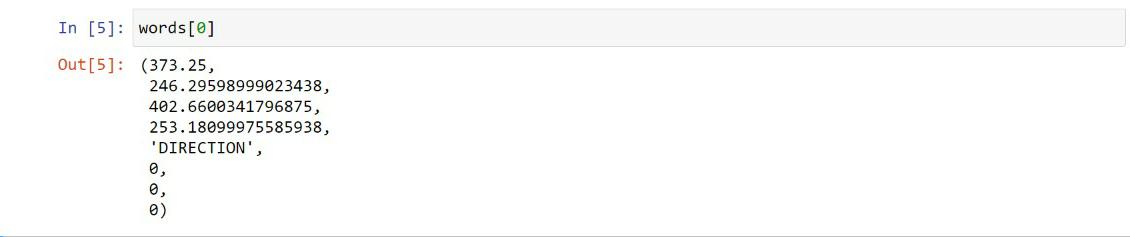
Extract the coordinates of the first object :
first_annots=[] rec=page1.first_annot.rect rec #Information of words in first object is stored in mywords mywords = [w for w in words if fitz.Rect(w[:4]) in rec] ann= make_text(mywords) first_annots.append(ann)
This function selects the words contained in the box, sort the words and return in form of a string :
def make_text(words):
line_dict = {}
words.sort(key=lambda w: w[0])
for w in words:
y1 = round(w[3], 1)
word = w[4]
line = line_dict.get(y1, [])
line.append(word)
line_dict[y1] = line
lines = list(line_dict.items())
lines.sort()
return "n".join([" ".join(line[1]) for line in lines])
OUTPUT

page.first_annot() gives the first annot i.e. bounding box of the page.
.rect gives coordinates of a rectangle.
Now, we got the coordinates of the rectangle and all the words on the page. We then filter the words which are present in our bounding box and store them in mywords variable.
We have got all the words in the rectangle with their coordinates. However, these words are in random order. Since we need the text sequentially and that only makes sense, we used a function make_text() which first sorts the words from left to right and then from top to bottom. It returns the text in string format.
Hurrah! We have extracted data from one annot. Our next task is to extract data from all annots of the PDF which would be done in the same approach.
Extracting each page of the document and all the annots/rectanges :
for pageno in range(0,len(doc)-1):
page = doc[pageno]
words = page.get_text("words")
for annot in page.annots():
if annot!=None:
rec=annot.rect
mywords = [w for w in words if fitz.Rect(w[:4]) in rec]
ann= make_text(mywords)
all_annots.append(ann)
all_annots, a list is initialized to store the text of all annots in the pdf.
The function of the outer loop in the above code is to go through each page of PDF, while that of the inner loop is to go through all annots of the page and performing the task of adding texts to all_annots list as discussed earlier.
Printing all_annots provides us the text of all annots of the pdf which you can see below.
OUTPUT
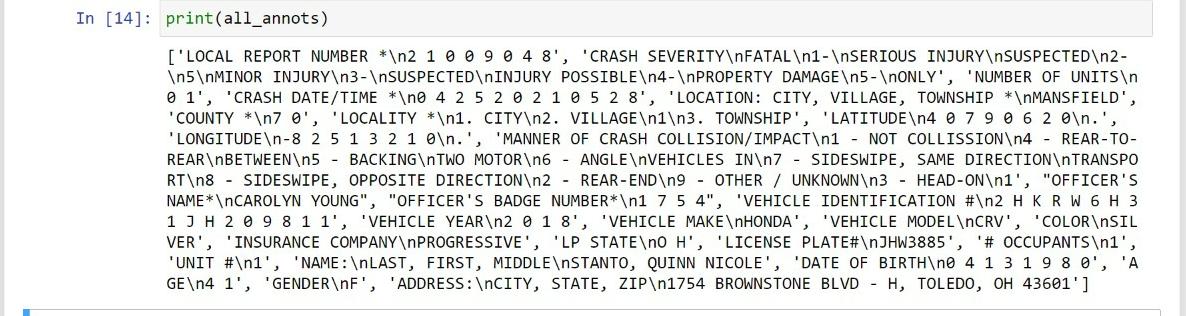
Finally, we have extracted the texts from all the annots/ bounding boxes.
Its time to clean the data and bring it in an understandable form.
Data Cleaning and Data Processing
Splitting to form column name and its values :
cont=[]
for i in range(0,len(all_annots)):
cont.append(all_annots[i].split('n',1))
Removing unnecessary symbols *,#,:
liss=[]
for i in range(0,len(cont)):
lis=[]
for j in cont[i]:
j=j.replace('*','')
j=j.replace('#','')
j=j.replace(':','')
j=j.strip()
#print(j)
lis.append(j)
liss.append(lis)
Spliting into keys and values and removing spaces in the values which only contain digits :
keys=[]
values=[]
for i in liss:
keys.append(i[0])
values.append(i[1])
for i in range(0, len(values)):
for j in range(0,len(values[i])):
if values[i][j]>='A' and values[i][j]<='Z':
break
if j==len(values[i])-1:
values[i]=values[i].replace(' ','')
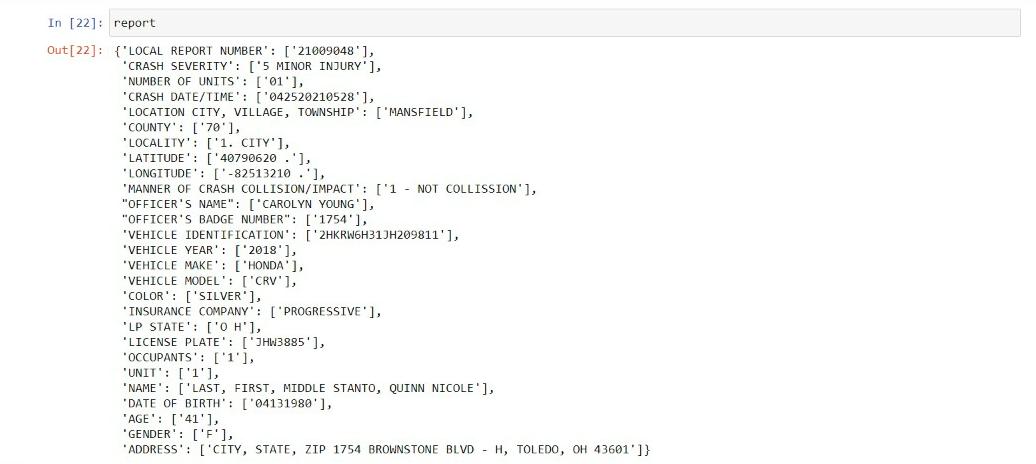
With the key-value pairs, we create a dictionary which is shown below:
Converting to dictionary :
report=dict(zip(keys,values))
report[‘VEHICLE IDENTIFICATION’]=report[‘VEHICLE IDENTIFICATION’].replace(‘ ‘,”)
dic=[report['LOCALITY'],report['MANNER OF CRASH COLLISION/IMPACT'],report['CRASH SEVERITY']]
l=0
val_after=[]
for local in dic:
li=[]
lii=[]
k=''
extract=''
l=0
for i in range(0,len(local)-1):
if local[i+1]>='0' and local[i+1]<='9':
li.append(local[l:i+1])
l=i+1
li.append(local[l:])
print(li)
for i in li:
if i[0] in lii:
k=i[0]
break
lii.append(i[0])
for i in li:
if i[0]==k:
extract=i
val_after.append(extract) break report['LOCALITY']=val_after[0] report['MANNER OF CRASH COLLISION/IMPACT']=val_after[1] report['CRASH SEVERITY']=val_after[2]
OUTPUT
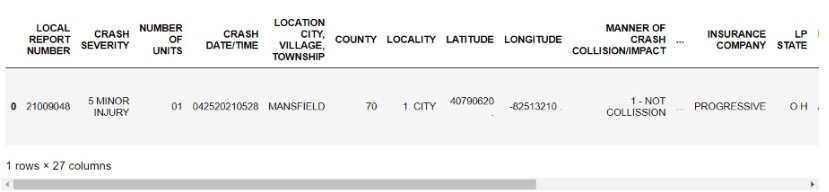
Lastly, dictionary is converted to dataframe with the help of pandas.
Converting to DataFrame and exporting to CSV:
data=pd.DataFrame.from_dict(report)
data.to_csv('final.csv',index=False)
OUTPUT
Now, we can perform analysis on our structured data or export it to excel.
How to Extract Data from Unstructured PDF Files with Python?
To extract data from unstructured PDF files using Python, you can use a combination of libraries such as PyPDF2 and NLTK (Natural Language Toolkit). Here’s a general approach:
- Install the required libraries by running the following command
pip install PyPDF2 nltk
- Import the necessary modules in your Python script
import PyPDF2
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords - Load the PDF file using
PyPDF2def extract_text_from_pdf(pdf_path):
pdf_file = open(pdf_path, ‘rb’)
pdf_reader = PyPDF2.PdfFileReader(pdf_file)
num_pages = pdf_reader.numPages
text = “”
for page_num in range(num_pages):
page = pdf_reader.getPage(page_num)
text += page.extract_text()
pdf_file.close()
return text - Preprocess the extracted text by removing stopwords and non-alphanumeric characters
def preprocess_text(text):
tokens = word_tokenize(text.lower())
stop_words = set(stopwords.words(‘english’))
cleaned_tokens = [token for token in tokens if token.isalnum() and token not in stop_words]
cleaned_text = ‘ ‘.join(cleaned_tokens)
return cleaned_text - Call the functions and extract the data from the PDF
pdf_path = “path/to/your/pdf/file.pdf”
extracted_text = extract_text_from_pdf(pdf_path)
preprocessed_text = preprocess_text(extracted_text)
# Process the preprocessed text further as per your specific requirements
# such as information extraction, entity recognition, etc.
This is a basic example to get you started. Depending on the structure and content of your PDF files, you may need to apply additional techniques for more accurate and specific data extraction.
Frequently Asked Questions
A. Yes, I can extract data from a PDF file. By parsing the file, I can retrieve text, images, tables, and other information contained within the PDF. Additionally, I can perform various operations like text extraction, table extraction, and metadata extraction to provide you with the necessary data from the PDF file.
A. Textract is a Python library provided by Amazon Web Services (AWS) that allows you to extract text and data from documents. It utilizes optical character recognition (OCR) technology to analyze images or PDF files and extract textual content, tables, and forms. Textract supports various document formats, including PDF, images (JPEG, PNG), and scanned documents. It can be integrated into Python applications to automate the extraction of information from documents efficiently.
I hope that you have enjoyed reading this blog and it has given you an intuition of dealing with unstructured data.
References:
Source of the featured image: Real Python https://realpython.com/python-data-engineer/
PyMuPDF documentation : https://pymupdf.readthedocs.io/en/latest/
About the Author:
Hi! I am Ashish Choudhary. I am pursuing B.Tech from the JC Bose University of Science & Technology. Data Science is my passion and feels proud to write interesting blogs related to it. Feel free to contact me on Linkedin linkedin.com/in/ashish-choudhary-7b6029166.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.








hey ashish excellent article. however i struct somewhere in my code. how could i contact u
thankyou for this post but I would appreciate it if you can share a link for the pdf used for the data extraction as that would make it easier to try this exercise.
I have tried to execute /practice the same below code : import fitz import pandas as pd doc = fitz.open('FlipKart_Invoice_2022_3.pdf') page1 = doc[0] words = page1.get_text("words") first_annots=[] rec=page1.first_annot.rect mywords = [w for w in words if fitz.Rect(w[:4]) in rec] ann= make_text(mywords) first_annots.append(ann) but, I am facing the below error : rec=page1.first_annot.rect AttributeError: 'NoneType' object has no attribute 'rect' Could you help me here ?
I am facing AttributeError: 'NoneType' object has no attribute 'rect'. Could you please help me here ?
Hi, great code by the way. However, when I tried, if I draw the bounding boxes using 'smallpdf.com' website the code is working but if I draw boxes using 'pypdf2' the boxes are not recognized by the code. Any sugessions!