Must Known Techniques for text preprocessing in NLP
This article was published as a part of the Data Science Blogathon
In any Machine learning task, cleaning or preprocessing the data is as important as model building. Text data is one of the most unstructured forms of available data and when comes to deal with Human language then it’s too complex. Have you ever wondered how Alexa, Siri, Google assistant can understand, process, and respond in Human language. NLP is a technology that works behind it where before any response lots of text preprocessing takes place. This tutorial will study the main text preprocessing techniques that you must know to work with any text data.

Table of Contents
- Overview on NLP
- Text Preprocessing
- Libraries used to deal with NLP Problems
- Text Preprocessing Techniques
- Expand Contractions
- Lower Case
- Remove Punctuations
- Remove words and digits containing digits
- Remove Stopwords
- Rephrase Text
- Stemming and Lemmatization
- Remove White spaces
- EndNote
Introduction to NLP
Natural Language Processing is a branch of Artificial Intelligence that analyzes, processes, and efficiently retrieves information text data. By utilizing the power of NLP one can solve a huge range of real-world problems which include summarizing documents, title generator, caption generator, fraud detection, speech recognition, recommendation system, machine translation, etc.
Text Preprocessing
Text preprocessing is a method to clean the text data and make it ready to feed data to the model. Text data contains noise in various forms like emotions, punctuation, text in a different case. When we talk about Human Language then, there are different ways to say the same thing, And this is only the main problem we have to deal with because machines will not understand words, they need numbers so we need to convert text to numbers in an efficient manner.
Libraries used to deal with NLP problems
There are many libraries and algorithms used to deal with NLP-based problems. A regular expression(re) is mostly used library for text cleaning. NLTK(Natural language toolkit) and spacy are the next level library used for performing Natural language tasks like removing stopwords, named entity recognition, part of speech tagging, phrase matching, etc.
NLTK is an old library used for practicing NLP techniques by beginners. Spacy is the latest released library with the most advanced techniques and mostly used in the production environment so I would like to encourage you to learn both the libraries and experience its power.
pip install nltk
Techniques for Text Preprocessing
Let’s make our hands dirty by practicing the techniques mostly used to clean text and make it noise-free.
Understanding Problem Statement
The first step before implementing any Machine learning project is understanding the problem. So, we are going to use Email spam data to demonstrate each technique and clean the data. The dataset contains 5697 unique emails and a label column indicating mail is span or Ham which is the target variable on which based on the content we need to classify the mails.
Please download the dataset from here.
Load data
Now we will load data and perform some basic preprocessing to see the data.
Python Code:
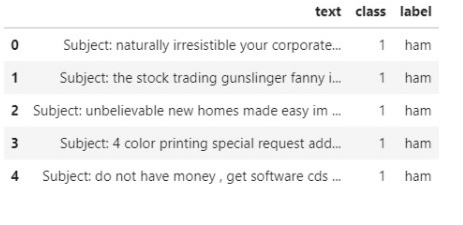
Now we will start with the techniques for text preprocessing and clean the data which is ready to build a machine learning model. let us see the first mail and when we will apply the text cleaning technique we will observe the changes to the first mail.
data['text'][0]

We can observe lots of noise at first mail like extra spaces, many hyphen marks, different cases, and many more. let’s get started with studying different techniques.
1) Expand Contractions
Contraction is the shortened form of a word like don’t stands for do not, aren’t stands for are not. Like this, we need to expand this contraction in the text data for better analysis. you can easily get the dictionary of contractions on google or create your own and use the re module to map the contractions.
contraction_dict = {"ain't": "are not","'s":" is","aren't": "are not"}
# Regular expression for finding contractions
contractions_re=re.compile('(%s)' % '|'.join(contractions_dict.keys()))
def expand_contractions(text,contractions_dict=contractions_dict):
def replace(match):
return contractions_dict[match.group(0)]
return contractions_re.sub(replace, text)
# Expanding Contractions in the reviews
data['reviews.text']=data['reviews.text'].apply(lambda x:expand_contractions(x))
we are not having any contraction in the first mail so, it is as it is. But I want to demonstrate this technique to you. Here, I have made a very small contractions dictionary, You can get all the contractions dictionary from google. expand contraction function uses a regular expression to map the contraction to the word. It will match the word with keys and if it is present then replace that word with its value.
2) Lower Case
If the text is in the same case, it is easy for a machine to interpret the words because the lower case and upper case are treated differently by the machine. for example, words like Ball and ball are treated differently by machine. So, we need to make the text in the same case and the most preferred case is a lower case to avoid such problems.
data['text'] = data['text'].lower()

You can observe the complete text in lower case
3) Remove punctuations
One of the other text processing techniques is removing punctuations. there are total 32 main punctuations that need to be taken care of. we can directly use the string module with a regular expression to replace any punctuation in text with an empty string. 32 punctuations which string module provide us is listed below.
'!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~'
Code to remove punctuation is
#remove punctuation
data['text'] = data['text'].apply(lambda x: re.sub('[%s]' % re.escape(string.punctuation), '' , x))
we have used a sub-method that takes 3 main parameters, the first is a pattern to search, the second is by which we have to replace, and the third is string or text which we have to change. so we have passed all the punctuation and finds if anyone present then replaces with an empty string. Now if you look at the first mail it will look something like this.

we can see lots of change in our mail, and all the hyphens, modulus signs, unwanted commas, and full stops are removed from the text.
4) Remove words and digits containing digits
Sometimes it happens that words and digits combine are written in the text which creates a problem for machines to understand. hence, We need to remove the words and digits which are combined like game57 or game5ts7. This type of word is difficult to process so better to remove them or replace them with an empty string. we use regular expressions for this. The first mail is not having digits but other mails in the dataset contain this problem like mail 4.
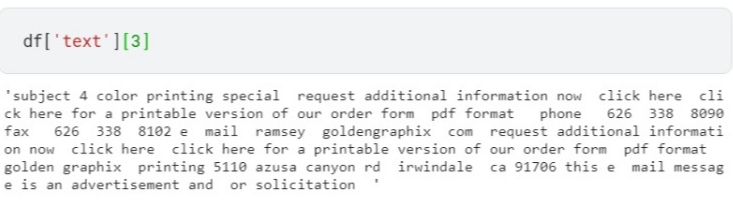
#remove words and digits data['text'] = data['text'].apply(lambda x: re.sub('W*dw*','',x))
now observe the changes in the mail.

5) Remove Stopwords
Stopwords are the most commonly occurring words in a text which do not provide any valuable information. stopwords like they, there, this, where, etc are some of the stopwords. NLTK library is a common library that is used to remove stopwords and include approximately 180 stopwords which it removes. If we want to add any new word to a set of words then it is easy using the add method.
In our example, we want to remove the subject words from every mail so we will add them to stopwords and HTTP to remove web links.
#remove stopwords
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
stop_words.add('subject')
stop_words.add('http')
def remove_stopwords(text):
return " ".join([word for word in str(text).split() if word not in stop_words])
data['text'] = data['text'].apply(lambda x: remove_stopwords(x))
Now the email text will be smaller because all stopwords will be removed.

here we have implemented a custom function that will split each word from the text and check whether it is a stopword or not. If not then pass as it is in string and if stopword then removes it.
6) Rephrase text
we may need to modify some text or change the pattern to a particular string which makes it easy to identify like we can match the pattern of email ids and change it to string like email address. In our example, we will modify the URL address and email address.
#email-id
df['text'] = df['text'].apply(lambda x: re.sub('b[w-.]+?@w+?.w{2,4}b', 'emailadd',x))
#url
df['text'] = df['text'].apply(lambda x:re.sub('(http[s]?S+)|(w+.[A-Za-z]{2,4}S*)', 'urladd', x))
you may not see any change in mails because we have already removed HTTP and punctuations before, But if you use the technique before applying the above preprocessing techniques, we can see the changes.
If you want to remove the URL then you can simply change the text to an empty string and it will replace fine. And you may also have different patterns which you need to look at and take care of. I think now you are capable to recognize the power of the regular expression library. isn’t it?
7) Stemming and Lemmatization
Stemming is a process to reduce the word to its root stem for example run, running, runs, runed derived from the same word as run. basically stemming do is remove the prefix or suffix from word like ing, s, es, etc. NLTK library is used to stem the words. The stemming technique is not used for production purposes because it is not so efficient technique and most of the time it stems the unwanted words. So, to solve the problem another technique came into the market as Lemmatization. there are various types of stemming algorithms like porter stemmer, snowball stemmer. Porter stemmer is widely used present in the NLTK library.
#stemming
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
def stem_words(text):
return " ".join([stemmer.stem(word) for word in text.split()])
df["text"] = df["text"].apply(lambda x: stem_words(x))

we can see the words in the text are stemmed and some of the words it has stemmed which is not required, that’s only the disadvantage of this.
Lemmatization
Lemmatization is similar to stemming, used to stem the words into root word but differs in working. Actually, Lemmatization is a systematic way to reduce the words into their lemma by matching them with a language dictionary.
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
def lemmatize_words(text):
return " ".join([lemmatizer.lemmatize(word) for word in text.split()])
df["text"] = df["text"].apply(lambda text: lemmatize_words(text))

Now observe the difference between both the techniques, it has only stemmed those words which are really required as per Language dictionary.
8) Remove Extra Spaces
Most of the time text data contain extra spaces or while performing the above preprocessing techniques more than one space is left between the text so we need to control this problem. regular expression library performs well to solve this problem.
df["text"] = df["text"].apply(lambda text: re.sub(' +', ' ', x)

These are the most important text preprocessing techniques that are mostly used while dealing with NLP problems.
EndNote
we have covered the most used text preprocessing techniques with hands-on practice. I hope that it was easy to catch each technique and the article will help in your NLP project to clean text. You can also develop a simple function with all techniques to preprocess text. Sometimes you may need some more techniques to clean text like dealing with emojis, emoticons, or simply with HTML tags which are also easy to perform with a regular expression and NLTK library.
The spacy library is required to analyze and understand the text data in a better way after preprocessing using regular expression and NLTK because spacy contains some advanced techniques. If you have any queries please comment down in the comment box.
If you like my article, please look at my other articles. link
About the Author
Raghav Agrawal
I am pursuing my bachelor’s in computer science. I am very fond of Data science and big data. I love to work with data and learn new technologies. Please feel free to connect with me on Linkedin.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
I am a final year undergraduate who loves to learn and write about technology. I am a passionate learner, and a data science enthusiast. I am learning and working in data science field from past 2 years, and aspire to grow as Big data architect.







