Different types of Bias that arise during Data Handling
This article was published as a part of the Data Science Blogathon

Table of Contents
- What is Bias?
- Why does Bias hurt?
- Data Bias may be of many types and forms
- A few of the important aspects to construct an “AI for better” world
- Endnotes
What is Bias?
If you have a vision of making sure that the product you’re currently working on follows all of the written guidelines of “AI for a better world”, then you might have simply encountered a situation where your records are biased.
Biased models, biased statistics, or biased implementation are traditional rules of a Data scientist’s lifestyle. Therefore, first, we need to apprehend and know that bias exists and may take any shape and form.
Sure, bias is a vast term and it could be present during the data collection, set of rules or algorithms, or even at the ML output interpretation stage.
Why does this biasing hurt?
Biasing can cause the disparate entry to the possibilities on the grounds of several human traits which include race, age, or gender, and need to be discouraged before starting to work with the project.
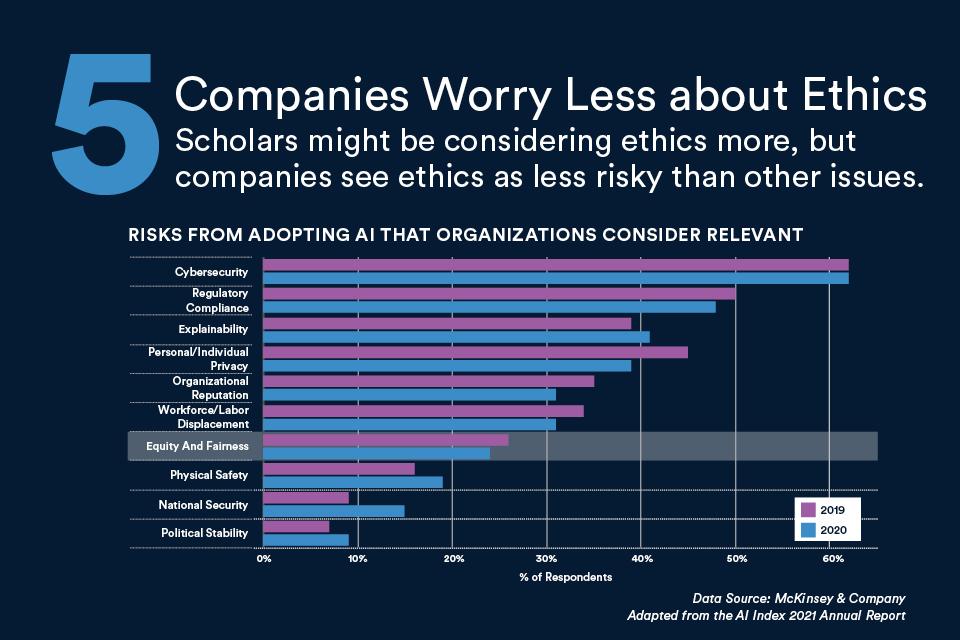
As per the AI index report published by Stanford University and AI/ML companies construe the subsequent dangers as time-honored to the industry and are trying very hard to mitigate such risks as they may be unfavorable and detrimental to their business and humanity in general.
Data bias may be of many types and forms
Structural bias: The data may be biased in simple terms due to the fact it is at the disposal of structural variations. The representation of ladies synonymous with the nurse, cook, the trainer is outwardly emanating from the societal construct. An e-commerce giant tried to construct a recruitment device that picked up the nuances of their current team of workers, which became pointless to mention, biased. A whole lot of attributes together with sports, social activities, achievements, and so forth had been picked by machines that caused a biased tool with a choice toward men.
Data collection: Conceivable motives for the prejudice in data gatherings will be based on time of the day, the age category of people, country of birth, the status of class, and many others. Information fed to the algorithms has to be constantly kept up to date to reflect the real image of the world we are staying in and in turn to predict the future state of our lives in this world of great nations.
Data manipulation: It’s far less complicated to drop the instances and not using a label attached or the ones with missing values. But it’s so much vital to check whether the observations being removed are mainly leading to misrepresented and mishandled data unique to gender, race, nationality, and related attributes.
Algorithm bias: The set of rules or algorithms will analyze what the facts sample suggests it examine. The algorithm both mirrors the widely widespread biases or to our worst fear amplifies them. If the judgments had been biased toward a particular organization of human beings, so does the machine research from the training facts.
The prejudice in the algorithms stems from the data that is both not accurate representation or is sprouting from the existential prejudices. If the facts entered are imbalanced, then we want to make certain that the algorithm still sees adequate instances of minority class to carry out well. There is more than one method to gain information rebalancing, number one is the ones that include artificial data creation, or assigning class weights so that the algorithm places a better penalty on each wrong prediction made on minority class.
Implementation bias: All ML prototypes are constructed on the basic assumptions that the train and take a test dataset must belong to a similar distribution. A version trained on summer season data might have exceptional feature distribution and subsequently will not be an appropriate suit to predict consumer conduct during the winter months.
The model will only do it properly as per our requirement if and only if the brand new data is as much as similar to data observed in the previous data set we used on which the version became efficient. Now not just implementation, however, the interpretation also can be biased. What if we, in our pursuit to analyze the set of rules or algorithm output, attempt to superimpose our beliefs and help our (biased) view.
Even as bias is one of the elements to be mended in our pursuit of a Moral Ethical AI framework, it’s unequivocally no longer trivial to mitigate.

A few of the important aspects to construct an “AI for better” world
- The data collector, code developer, and product manager are typically the individuals who work in the subject and are closer to the data acquisition and modification. Organizations need to sensitize their employees and unfold the focus about the possible reasons for bias and the way to mitigate them.
- Having a professional (AI Ethicist) who’s adept at identifying the resources of bias can help businesses align their vision with the moral framework.
- Creating gold trends in your data labeling process. The gold standard is a set of statistics that reflects the most perfect labeled data for your project. It permits you to compute your group’s annotations for precision.
- Make clear tips for data labeling expectancies so data labelers are steady.
- Use multi-pass annotation for any project wherein data precision can be susceptible to bias. Examples of this include sentiment analysis, content material moderation, and objective identification.
- Enlist the assist of another person with an area similar area of interest to study your accrued and/or annotated records. Consult external expertise outside of your team may see biases that your group has left out.
- A governance team created from people of exclusive groups like privacy, ethics, and compliance, product, and engineering will assist to offer a fresh angle at identifying the conceivably left out biases.
Endnotes
There’s not a single rulebook that can be read and implemented at one go, it is an ever-evolving framework and needs to be updated more frequently. Additionally, it’s far more commendable that the efforts in preserving an impartial, fair, and sincere, and most of all a trustworthy AI framework aren’t sighted as obscure anymore and are accumulating the proper interest and attention internationally.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.








{kind=link}