A Guide to Perform 5 Important Steps of NLP Using Python
This article was published as a part of the Data Science Blogathon
Introduction
Natural Language Processing is a popular machine learning technique used to analyze text content. We see a lot of fancy reports around us and a lot of companies use business intelligence insights to drive their business. Most of these insights and reports are created using structured data. There are still some use cases for unstructured data. These could be in the form of text, tweets, images, etc. NLP focuses on bringing out meaningful insights from these text-based sources.
Some examples of NLP include sentiment analysis. So if you have a company and have newly launched a product, you can analyze the sentiments of the users via their tweets. Even product reviews on your website can be analyzed in the same way.
Challenges of NLP
So what seems to be the challenge here?
- Let us take an example of a review: “The product is extraordinarily bad”
- Extraordinary is usually referred to in a positive way. If we were to use a keyword-based approach and tag it using the word extraordinary, then it would be incorrect. This is where NLP comes in. These situations where oxymorons are used need to be handled carefully.
- Another challenge is in terms of similar words as well as ambiguous meanings.
- Irony and sarcasm is difficult for a machine to understand
Advantages of NLP
Some of the advantages of NLP include:
- Can work with unstructured data.
- More insights on the sentiments of a customer.
- Chatbots and other such AI/ML-based devices/technologies are being improved upon.
Steps involved in NLP

Let us take a look at the basic steps involved in running a simple NLP algorithm using a news article dataset.
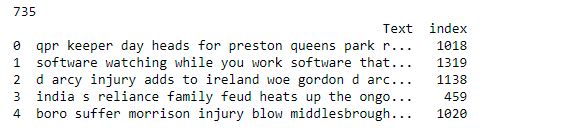
I have imported the required libraries for this data processing using NLP. Post that I have imported the file from my local system. You can see how the file looks like. Each row has a news article containing some text as well as an index value.
import gensim
import numpy
#numpy.numpy.random.bit_generator = numpy.numpy.random._bit_generator
from gensim.utils import simple_preprocess
from gensim.parsing.preprocessing import STOPWORDS
from nltk.stem import WordNetLemmatizer, SnowballStemmer
from nltk.stem.porter import *
import numpy as np
np.random.seed(2018)
import nltk
nltk.download('wordnet')
import pandas as pd
data = pd.read_csv('C:\Users\ktk\Desktop\BBC News Test.csv', error_bad_lines=False);
data
data_text = data[['Text']]
data_text['index'] = data.ArticleId
documents = data_text
Tokenization
This is the first major step to be done to any data. So what does this step do? Imagine you have a 100-word document. You need to split the document into 100 separate words in order to identify the keywords and the major topics. This process is called tokenization. I have used an example where I have imported the data sets and used a gensim library for all the preprocessing steps.
This library has a preprocess function that helps tokenize the keywords. I have used a function called preprocess to help pick out the keywords. Different libraries have different functions for this process.
processed_docs = documents['Text'].map(preprocess) processed_docs[:10]

You can also remove the punctuation in this same step. There are functions for the same as well. Since this particular dataset does not have any punctuation, I have not used the punctuation removal functions.
Stop Word Removal
You have a huge dataset or several articles. In these articles, you will find that a lot of words like, “is”, “was”, “were”, etc are present. These words do not technically add any value to the main topic. These are tagged as stop words. There are a number of stop word removal techniques that can be used to remove these stop words. This will help us to arrive at the topic of focus.
import nltk
from nltk.corpus import stopwords
print(stopwords.words('english'))
stop_words = stopwords.words('english')
output = [w for w in processed_docs if not w in stop_words]
print("n"+str(output[0]))

I have used stop word function present in the NLTK library. The first list contains the list of stop words considered by the system. The second list contains the list of words after the stop words have been removed.
We will be left with only the keywords once the stop words are removed. This step is important for any NLP processing.
Stemming
Stemming means cutting out the other parts of a word and keeping only the stem (i.e. the important part of the word). In English, we add prefixes and suffixes to a word to form different words/tense forms of the same word.
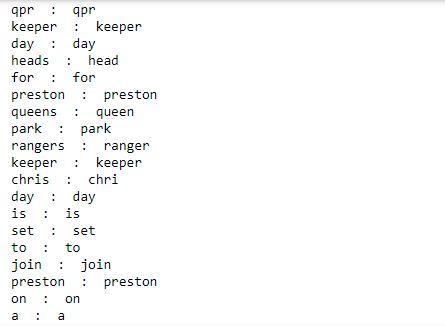
For example, the root word stem can take the form of stemming or stems. The stemming process will remove the suffix to give out the word – stem. I have performed both the stemming as well as the lemmatization process explained in the next step together. The code snippet for both is attached together in the next step. I have attached an example for stemming in the code below. You can notice that the word “queens” has been stemmed to “queen“.
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenize
ps = PorterStemmer()
a = doc_sample.split(' ')
for w in a:
print(w, " : ", ps.stem(w))
Another example is the word ecosystem. The root word for this is “eco” while the derived word is “ecosystem“. You do not need to be a grammar expert to perform stemming. Python has libraries that support the stemming process.
Lemmatization
Lemmatization is similar to stemming but is different in a complex way. Stemming simply cuts out the prefix or the suffix without thinking whether the remaining root word makes sense or not. Lemmatization on the other hand looks at the stemmed word to check whether it makes sense or not.
For example, the word “care” when stemmed will give out “car” but when lemmatized will give out “care”. The root word care is called a lemma.
So why is lemmatization very important?
Lemmatization helps in the disambiguation of words. It brings out the actual meaning of the word. So if you have multiple words which share a similar meaning, lemmatization can help sort this out. Hence, this is a very important step for your NLP process.
def lemmatize_stemming(text): snow_stemmer = SnowballStemmer(language='english') return snow_stemmer.stem(WordNetLemmatizer().lemmatize(text, pos='v')) def preprocess(text): result = [] for token in gensim.utils.simple_preprocess(text): if token not in gensim.parsing.preprocessing.STOPWORDS and len(token) > 3: result.append(lemmatize_stemming(token)) return result
doc_sample = documents[documents['index'] == 1018].values[0][0]
print('original document: ')
words = []
for word in doc_sample.split(' '):
words.append(word)
print(words)
print('nn tokenized and lemmatized document: ')
print(preprocess(doc_sample))

You can see the steps used to stem and lemmatize the same news article document. Here, I have used a snowball stemmer for this process.
Modelling
Modeling your text is very important if you want to find out the core idea of the text. I the case of supervised machine learning, we use logistic regression or linear regression, etc to model the data. In those cases, we have the output variable which we use to train the model. In this case, since we do not have the output variable, we rely on unsupervised techniques.
There are a lot of good algorithms to help model the text data. Two of the most commonly used are the SVD (Singular Value decomposition) and LDA (latent Dirichlet allocation). These are widely used across the industry and are pretty simple to understand and implement.
LDA is a probabilities algorithm that focuses on iteratively assigning the probability of a word belonging to a topic. I have used LDA here to identify the possible topics for an article.
lda_model = gensim.models.LdaMulticore(bow_corpus, num_topics=10, id2word=dictionary, passes=2, workers=2)

Here, you can see the probabilities being listed out for each article. Each keyword has a value that states the likeliness of the word being the keyword.
Conclusion
What I have listed out are some of the key steps in NLP. NLP is a dimension onto itself. To fully understand the magnitude of it, we need to first understand how deep any language can be. Since, NLP focuses on text data based on language, irony, sarcasm, comedy, trauma, horror, and many more such things need to be considered.
On a parting note, I wish to bring to your attention that the possibilities using NLP are limitless. The industry has realized the value of the text data of late and has started exploring more on this. Even the automated chatbots which pass the turning test have some amount of NLP embedded in them.

About the Author
Hi there! This is Aishwarya Murali, currently working in the analytics division of Karnataka Bank’s – Digital Centre of Excellence in Bangalore. Some of my interesting projects include ML-based scorecards for loan journey automation, customer segmentation, and improving the market share via selective profiling of customers using some machine learning analytics.
I have a master’s in computer applications and have done certification in Business Analytics from IIM-K. Currently, I am working on R&D innovations at my workplace.
You can connect with me at
https://www.linkedin.com/in/aishwarya-murali-b710a978/
You can also mail me at
Image source – https://www.forbes.com/sites/bernardmarr/2020/09/11/4-simple-ways-businesses-can-use-natural-language-processing/?sh=58bdfe13a5f3
https://www.kdnuggets.com/2018/03/5-things-sentiment-analysis-classification.html
Benefits of Natural Language Processing for the Supply Chain







