A Beginner’s Introduction to NER (Named Entity Recognition)
Introduction
In the ever-evolving landscape of Natural Language Processing (NLP), one remarkable technology stands out, potentially revolutionizing how machines understand human language. It goes by the name of Named Entity Recognition (NER). This game-changing NLP technique empowers machines not just to comprehend text but also to identify and categorize specific entities within it. From recognizing people’s names to pinpointing locations, organizations, dates, and more, NER paves the way for a deeper understanding of language.
This article will give you a brief idea about Named Entity recognition , a popular method that is used for recognizing entities that are present in a text document. This article is targeted at beginners in the field of NLP. Towards the end of the article, you will see how pre-trained NER models are implemented in practical use cases. Happy learning!
This article was published as a part of the Data Science Blogathon.
Table of contents
What Is Name Entity Recognition NLP?
At its core, Named Entity Recognition, or NER for short, is a subtask of NLP that focuses on identifying and classifying entities within textual data. These entities encompass a diverse range of information, including names of individuals, organizations, locations, dates, numerical values, and more. named entity recognition in python (NER) equips machines with the ability to extract these entities, making it a fundamental tool for diverse applications across various industries.
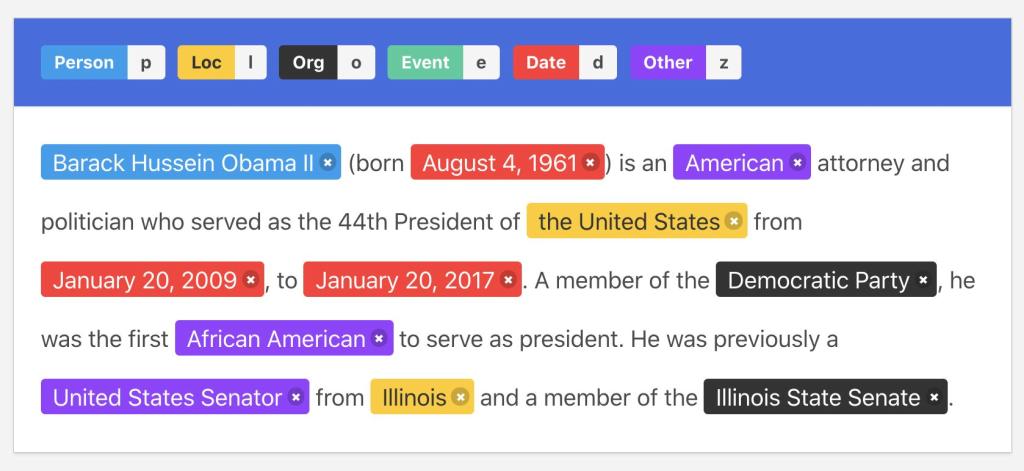
From the above image, you might have gotten some ideas about what an named entity recognition python model does do. The model can find different entities that are present in the text, such as persons, dates, organizations, and locations. Thus NER helps in adding more meaning to the text document. In simple words, you can say that it is doing information extraction.
How Does Named Entity Recognition Work?
NER operates as an information extraction technique, and its functioning can be distilled into several key steps:
- Text Preprocessing
The first step involves preparing the textual data for analysis. This typically includes tasks like tokenization (breaking the text into words or phrases) and part-of-speech tagging.
- Entity Identification
Once the text is preprocessed, NER algorithms scan it to identify sequences of words that correspond to entities. For example, identifying “New York City” as a location or “Apple Inc.” as an organization.
- Entity Classification
After identification, NER categorizes the recognized entities into predefined classes or types. Common categories include Person, Organization, Location, Date, and more.
- Contextual Analysis
NER doesn’t just stop at recognizing and categorizing entities. It also considers the context in which these entities appear, ensuring accurate classification. For instance, “Apple” could refer to the tech giant or the fruit, and NER discerns the correct context.
Use Cases of Name Entity Recognition
Use Cases of Name Entity Recognition
The use cases of Named entity recognition are many. Some of them are:
1. Customer support
Every company has its customer support systems available. Each day, they have to deal with a huge number of customer requests which may range from installation, maintenance, complaint, and troubleshooting of a particular product. NER helps in identifying and understanding the type of request that the customer makes. Further, this helps the company build an automated system that will identify incoming requests using NER and send them to the respective support desk.
2. Resume Filtering

Do you think that all the resumes that are sent while applying for a particular job role are read by the recruiting team? Well, the fact is that only 25 percent of the resumes are read by people. The rest are filtered out by an automated system.
If you had previously attended a resume-building workshop, the mentor might have emphasized keeping the key skills as a separate section in the resume. Also, they might have advised you to add only the key skills that are related to the required job position. This is because the Named entity recognition in python (NER) model in the automated system might have been custom-trained to identify specific skill sets as entities. If a given resume has a required number of entities present, then it qualifies for the next stage. So, if you were not aware of this process, try to customize your resume accordingly while applying for the respective job.
3. Electronic Health Record (EHR) Entity Recognition
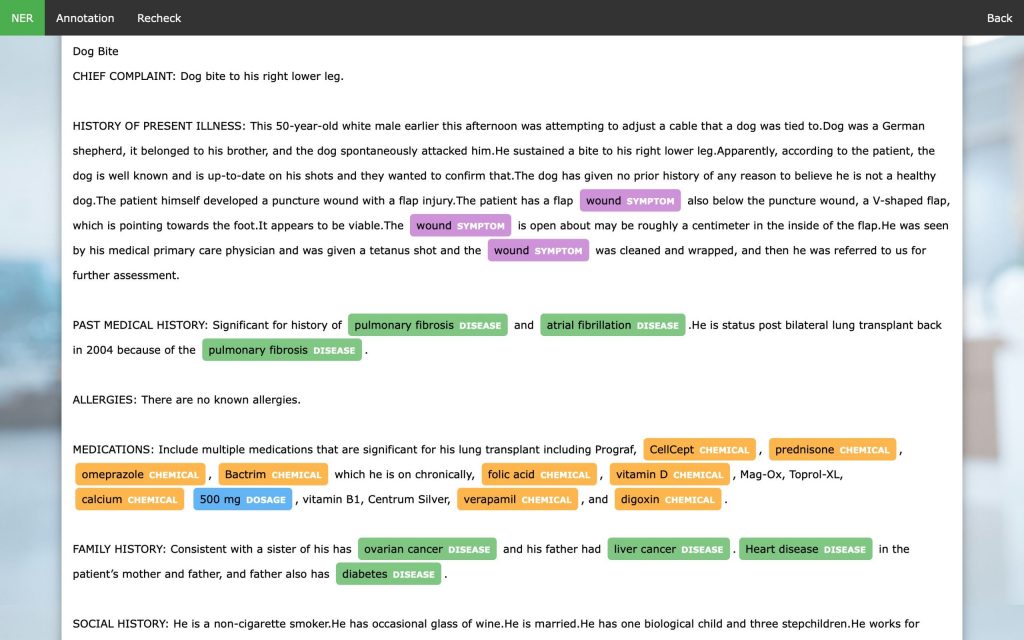
NER models can be used to build strong medical systems that are properly able to identify the symptoms present in the electronic healthcare data of patients and diagnose their disease depending on the symptoms. If you go through the above image, you can understand how perfectly the NER model was able to identify the symptoms, diseases, and chemicals that were present in the healthcare data of a particular person.
Those were some of the applications where NER was used in real-world scenarios. Next, we will check upon different types of NER systems.
Different Types of NER Systems
There are four different NER systems: rule-based, dictionary-based, machine learning (ML) based, and deep learning approaches. Let’s look at them one by one.
Dictionary-based Systems
This is the simplest NER approach. Here we will be having a dictionary that contains a collection of vocabulary. In this approach, basic string matching algorithms are used to check whether the entity is occurring in the given text to the items in the vocabulary. The method has limitations as it is required to update and maintain the dictionary used for the system.
Rule-based Systems
Here, the model uses a pre-defined set of rules for information extraction. Mainly two types of rules are used, Pattern-based rules, which depend upon the morphological pattern of the words used, and context-based rules, which depend upon the context of the word used in the given text document. A simple example for a context-based rule is “If a person’s title is followed by a proper noun, then that proper noun is the name of a person”.
Machine Learning-based Systems
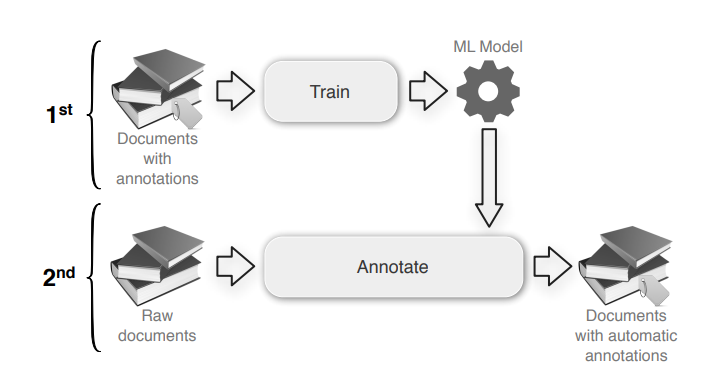
The ML-based systems use statistical-based models for detecting the entity names. These models try to make a feature-based representation of the observed data. By this approach, a lot of limitations of dictionary and rule-based approaches are solved by recognizing an existing entity name, even with small spelling variations.
There are mainly two phases when we use an ML-based solution for NER. The first phase involves training the ML model on the annotated documents. The time taken for the model to train will vary depending on the complexity of the model that we are building. In the next phase, the trained model can be used to annotate the raw documents.
Deep Learning Approaches
In recent years, deep learning-based models are being used for building state-of-the-art systems for NER. There are many advantages of using DL techniques over the previously discussed approaches. Using the DL approach, the input data is mapped to a non-linear representation. This approach helps to learn complex relations that are present in the input data. Another advantage is that we can avoid a lot of time and resources spent on feature engineering, which is required for the other traditional approaches.
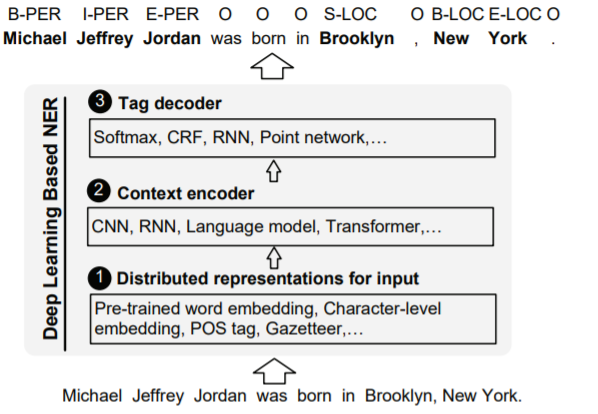
Next, we will try out some tools for NER extraction.
What is the Purpose of Named Entity Recognition?
Named Entity Recognition (NER) in Python efficiently identifies and categorizes named entities such as people, places, and organizations in text data. It streamlines tasks like information extraction and analysis, enhancing accuracy and efficiency in natural language processing applications.
Tools for NER Extraction
Standford NER Tagger
It is one of the standard tools that is used for Named Entity Recognition. Mainly there are three types of models for identifying the named entities. They are:
- Three-class model: recognizes the organizations, persons, and locations.
- Four-class model: recognizes persons, organizations, locations, and miscellaneous entities.
- Seven-class model: recognizes persons, organizations, locations, money, time, percentages, and dates.
Let’s try NER extraction using the four-class model.
1. Downloading the StanfordNER zip file using the following commands
!pip3 install nltk==3.2.4
!wget http://nlp.stanford.edu/software/stanford-ner-2015-04-20.zip
!unzip stanford-ner-2015-04-20.zip2. Loading the model
from nltk.tag.stanford import StanfordNERTagger
jar = "stanford-ner-2015-04-20/stanford-ner-3.5.2.jar"
model = "stanford-ner-2015-04-20/classifiers/"
st_4class = StanfordNERTagger(model + "english.conll.4class.distsim.crf.ser.gz", jar, encoding='utf8')3. While testing the model, I had taken a news extract from the Indian Express newspaper
example_document = '''Deepak Jasani, Head of retail research, HDFC Securities, said: “Investors will look to the European Central Bank later Thursday for reassurance that surging prices are just transitory, and not about to spiral out of control. In addition to the ECB policy meeting, investors are awaiting a report later Thursday on US economic growth, which is likely to show a cooling recovery, as well as weekly jobs data.”.'''4. Providing the news article to the model
st_4class.tag(example_document.split())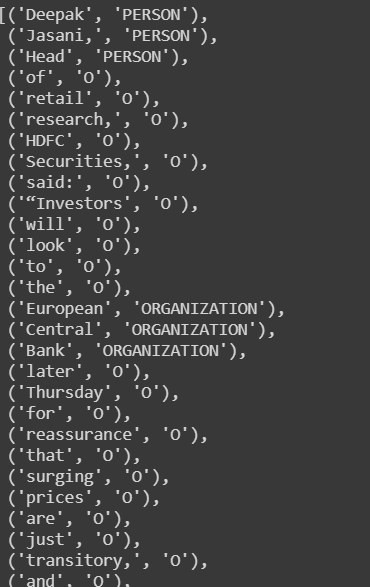
Spacy Pipelines for NER
Spacy mainly has three English pipelines optimized for CPU for Named Entity Recognition. They are:
- en_core_web_sm
- en_core_web_md
- en_core_web_lg
The above models are listed in ascending order according to their size, where SM, MD, and LG denote small, medium, and large models, respectively. Let us try out NER using the small model.
1. First, let us download the model
import spacy
import spacy.cli
spacy.cli.download("en_core_web_sm")2. Loading the model
sp_sm = spacy.load('en_core_web_sm')3. Creating a function to output the recognized entities by the model.
def spacy_large_ner(document):
return {(ent.text.strip(), ent.label_) for ent in sp_lg(document).ents}
spacy_large_ner(example_document)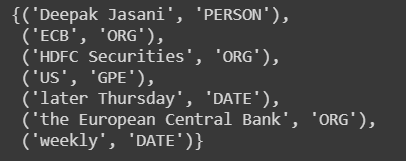
Here GPE means Geopolitical Entity.
Conclusion
This article has briefly covered the basics of Named Entity Recognition and its use cases. You can also try out the above-implemented pre-trained model with different examples. Further, as a next learning step, you can try to build custom NER models for your specific domain purposes. Many pre-trained state-of-the-art NER models are available; you can fine-tune them for your usage. Spacy is a good library for building and using custom NER models. Please check out the documentation of Spacy that I have provided in the reference. Also, remember that named entity recognition python is not limited to the English language. The BERT-based multilingual models can be used for NER tasks in different languages.
This article is just the beginning to data extraction. If you are interested in learning more about Named Entity Recognition and other data extraction tools and techniques, do consider enrolling in our BlackBelt Plus program. This certified AI & ML program is aimed to help you master various data extraction and visualization techniques, expand your skills, and enhance your proficiency in data analytics.
Frequently Asked Questions
Ans. Named Entity Recognition (NER) is an NLP technique that identifies and classifies named entities in text, like names of people, places, organizations, dates, monetary values, etc. For example, in “Apple Inc. was founded by Steve Jobs in Cupertino,” NER would identify “Apple Inc.” as an organization and “Steve Jobs” as a person.
Ans. The purpose of Named Entity Recognition (NER) is to identify and classify named entities within text. It helps extract and understand important information from text data for purposes such as information retrieval, document summarization, question answering, sentiment analysis, machine translation, language modeling, etc.
Ans. Some commonly used techniques of NER include rule-based NER, statistical NER, machine learning-based NER, deep learning-based NER, BERT-based models, and hybrid approaches.
Ans. The four main types of NER are dictionary-based, rule-based, machine learning-based, and deep learning-based.
A named entity is a special word or phrase that represents something with a name, like a person, place, organization, date, or number. For instance, “New York City” is a named entity for a place, “Microsoft” for a company, and “2024” for a date.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.







