Guide for Tokenization in a Nutshell – Tools, Types
Introduction
Text is all we need. Everything we speak, write carries a huge amount of information. The topic name of the article, tone of the article everything adds a piece of information that we can interpret and extract the insights from them. Processing text and extracting the important information from the text is text processing. Doing data analysis by extracting information from the text
using different libraries and tools.
There are different ways to pre-process the text.
- Cleaning the text
- Removing stop words
- Tokenizing
- Stemming/Lemmatization
Converting a sequence of text (paragraphs) into a sequence of sentences or sequence of words this whole process is called tokenization. Tokenization can be separate words, characters, sentences, or paragraphs.
One of the important steps to be performed in the NLP pipeline. It transforms unstructured textual text into a proper format of data. One of the basic and first steps to perform while working with text data.
Let’s see in the form of a chart.
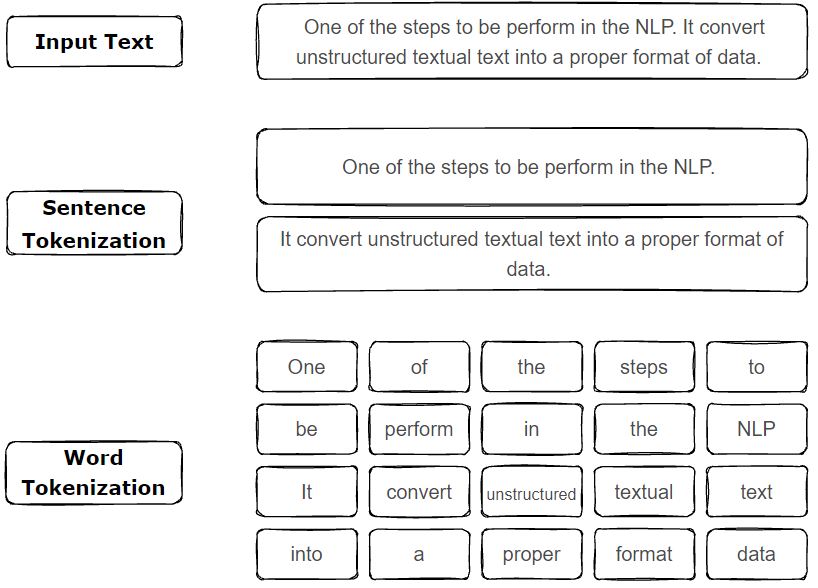
Image Reference: Author
Why Tokenization is important?
Tokenization is the first and foremost step in the NLP pipeline. A tokenizer will break the data into small chunks for easy interpretation.
Different Techniques For Tokenization
There are multiple ways for tokenization on a given textual data. We can choose any method based on the language, library, and purpose of modeling. We can do the tokenization by the different libraries like NLP, spacy, Textblob, Keras, and Genism.
Tokenization with python in-build method / White Space
Let’s start with the basic python in-build method. We can use the split() method to split the string and return the list where each word is a list item. This method is also known as White space tokenization. By default split() method uses space as a separator, but we have the option to format it.
Let’s see an example for word-level tokenization.
sentence = "Hello, this is a learning platform."
tokens = sentence.split()
print("Python In-build Tokenization:n", tokens)
#Output
Python In-build Tokenization:
['Hello,', 'this', 'is', 'a', 'learning', 'platform.']
The build-in split() method works perfectly fine but there is one fault it doesn’t consider punctuation as a separate token like in “Hello,” the word Hello and ‘,’ is not separated.
Note: The python in-build split() method does not consider punctuations as a separate token.
Sentence Tokenization
We are using the python in-build function split() method for sentence tokenization. Let’s see an example for sentence level tokenization using comma ‘,’ as a separator. Here the text will be split when a comma(,) is encountered in the text.
If we want to tokenize the sentence when the dot(.) is encountered. This is what we normally use.
sentence = "This is a learning platform. Which provides knowledge of DS"
tokens = sentence.split('. ')
print(tokens)
# Output
['This is a learning platform', 'Which provides knowledge of DS']
Tokenization with RegEx
A regular expression is a sequence of characters that defines a specific pattern. With the help of Regex, we can find the specified string and perform word tokenization sentence tokenization, or character tokenization.
Let’s see an example where we will tokenize the tokens.
import re
sentence = "This is! a learning platform! Which provides knowledge of DS"
tokens = re.findall("[w]+", sentence)
print(tokens)
# Output
['This', 'is', 'a', 'learning', 'platform', 'Which', 'provides', 'knowledge', 'of', 'DS']
Tokenization with NLTK
Natural Language Toolkit (NLTK) is a python library for natural language processing (NLP). NLTK has a module for word tokenization and sentence tokenization.
First, we are going to download the library
!pip install --user -U nltkNow, let’s see an example for word tokenizer in NLTK
from nltk.tokenize import word_tokenize sentence = "This is a *learning platform.s!. Which provides #knowledge of DS" tokens = word_tokenize(sentence) print(tokens) # Output ['This', 'is', 'a', '*', 'learning', 'platform.s', '!', '.', 'Which', 'provides', '#', 'knowledge', 'of', 'DS']
Note: While working with word tokenizers from NLTK, punctuations are also considered as separate tokens.
Now, let’s see an example for sentence tokenizer in NLTK
from nltk.tokenize import sent_tokenize sentence = "This is a *learning platform.s!. Which provides #knowledge of DS" tokens = sent_tokenize(sentence) print(tokens) # Output ['This is a *learning platform.s!.', 'Which provides #knowledge of DS']
Punctuation based tokenizer
The punctuation-based tokenizer splits the given text based on punctuation and whitespace.
from nltk.tokenize import wordpunct_tokenize sentence = "This is a *learning platform.s!. Which provides #knowledge of DS" tokens = wordpunct_tokenize(sentence) print(tokens) # Output ['This', 'is', 'a', '*', 'learning', 'platform', '.', 's', '!.', 'Which', 'provides', '#', 'knowledge', 'of', 'DS']
The punctuation-based tokenizer will split the words having punctuations in them too like platform.s is the whole word but using punctuation tokenizer the word will convert into ‘platform’, ‘.’, ‘s’.
Treebank word Tokenizer
The problem which we had in the punctuation tokenizer of splitting the words into an incorrect format like doesn’t into doesn, ‘, and t but now the problem is solved. Treebank tokenizer contains rules for English contractions.
You can find all the rules for the treebank tokenizer here.
from nltk.tokenize import TreebankWordTokenizer sentence = "When you think you can't do, do that" tokens = TreebankWordTokenizer().tokenize(sentence) print(tokens) # Output ['When', 'you', 'think', 'you', 'ca', "n't", 'do', ',', 'do', 'that']
Textblob Tokenizer
The textblob is an open-source python library for text processing. Textblob is faster than NLTK, it is simple to use and has callable functions. We can use it for simple application usage. We can perform different operations on the textual data with Textblob like
- Sentiment Analysis
- Classification of Textual Data
- Noun Phrase Extraction
- Translation
Importin the necessary library to start with Textblob, as textblob will require certain features of NLTK library.
Importing using pip, run the following command
!pip install textblob
Importing using anaconda prompt, run the following command
pip install -U textblob
Now if you want to download the necessary corpora, you can run the below command and download the corpora as peruse.
python -m textblob.download_corpora
Importing the required library
from textblob import TextBlob
Before going into the NLP task let’s understand some of the basic terms:
- Corpus: Corpus is a large collection of language data. We use corpora for training different models like Sentiment Analysis, Classification, etc.
- Token: Token is also known as a word it is the output of tokenization.
Textblob Word Tokenizer
To tokenized at the word level, we will be using the word attribute.
It will return a list of words objects. While working with word tokenizer textblob removes the punctuations from the text.
from textblob import TextBlob sentence = "This is a *learning platform.s!. Which provides #knowledge of DS" token = TextBlob(sentence) print(token.words) # Output ['This', 'is', 'a', 'learning', 'platform.s', 'Which', 'provides', 'knowledge', 'of', 'DS']
Textblob Sentence Tokenizer
To tokenize at the sentence level, we will use the sentence attribute. It will return a list of sentence objects.
Let’s start by installing TextBlob and the NLTK corpora:
from textblob import TextBlob
token = TextBlob(sentence)
print(token.sentences)
# Output
[Sentence("This is a *learning platform.s!."), Sentence("Which provides #knowledge of DS")]
EndNote
After going through the article you will be able to implement different types of tokenization with the help of libraries and tools.
We saw what is tokenization and what are the benefits of tokenization which is the first and foremost step in the NLP pipeline. We also saw what are the different libraries used for tokenization and how to do tokenization at word and sentence levels.
References
All the images are created by: Author
Reference for treebank tokenizer: here
Author’s Contact
You can contact me through the below-mentioned social media platforms.
LinkedIn | Kaggle | Tableau | Medium | Analytics Vidhya
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
A student who is learning and sharing with a storyteller to make your life easy.







