Custom Named Entity Recognition using spaCy v3
This article was published as a part of the Data Science Blogathon.
Introduction to Named Entity Recognition
A named entity is a ‘real-world object’ that is assigned a name, for example, person, organization, or location. For more details, check my previous article on fine tune Bert for NER.
All in all, NER can be summarized as follows
- Information Extraction
- Detect and classify the named entities in unstructured data
Objective
Learn how to use Spacy for the Named Entity Recognition task
Prerequisites
- Working knowledge of Python
- Basic knowledge of Spacy
spaCy
Natural Language Processing (NLP) has lots of use cases and spaCy has a large contribution to the adoption of NLP in the industry as a free, open-source python library. It is designed to handle a large volume of text data and to draw insights by understanding text, also it is suited for production use. It can be used to build Information Extraction(IE) or Natural language understanding(NLU) systems or to pre-process text for deep learning.
Features
spaCy supports tokenization, part of speech(POS) tagging, dependency parsing, and many others as follows
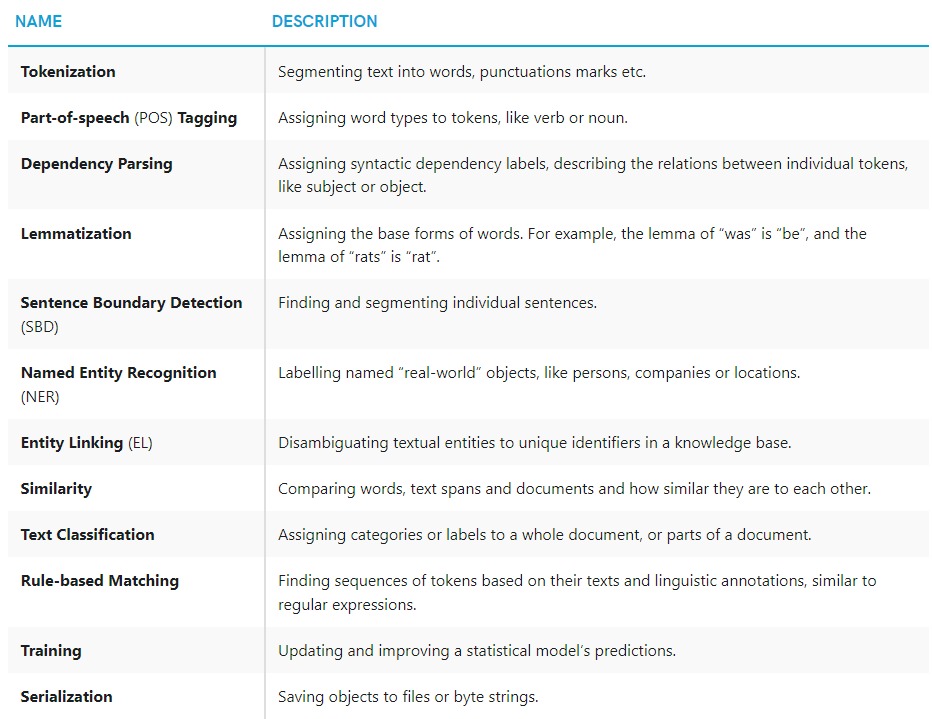
Source: spaCy 101: Everything you need to know · spaCy Usage Documentation
spaCy has pre-trained models for a ton of use cases, for Named Entity Recognition, a pre-trained model can recognize various types of named entities in a text, as models are statistical and extremely dependent on the trained examples, it doesn’t work for every kind of entity and might require some model tuning depending on the use-case in hand.
Now let’s see an example in action.
First, we need to import spacy and load an English model, `en_core_web_sm`
The naming convention for the model has language notation (eg. `en` for English), denoting on which language it was trained followed by three components,
- Type: Model capabilities (`core` for a general-purpose model with vocabulary, syntax, entities, and word vectors, or `depent` for only vocabulary, syntax, and entities.
- Genre: Type of text the model is trained on (web or news)
- Size: Model size indicator (sm:small, md:medium, or lg:large)
`en_core_web_sm` is an English language multi-task Convolutional Neural Network(CNN) trained on OntoNotes. Assigns context-specific token vectors, POS tags, dependency parse, and named entities.
For more details on models, check out the spaCy models page.
Now, we can pass the text to spacy object, nlp
To get detected entities, we need to iterate the ents property of the doc

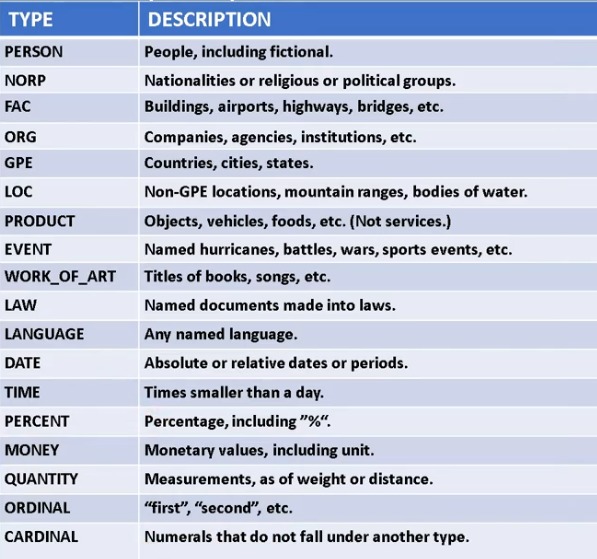
The entities detected by spaCy models are as follows
We can even visualize the output using displacy as follows
from spacy import displacy displacy.render(doc, style="ent", jupyter=True)
We need to set the `jupyter` parameter to True if we are running in the jupyter notebook or google colab.

Now, let’s understand the entire pipeline in detail
When we use `nlp` (spacy model object) on a text, spaCy first tokenizes the text to produce a `Doc` object, which is then processed in the next stages in the pipeline. The pipeline used by the default models consists of a tagger stage, a parser stage, and an entity recognizer(ner) stage. Each pipeline component processed the `Doc` object and then passed it on to the next component/stage.
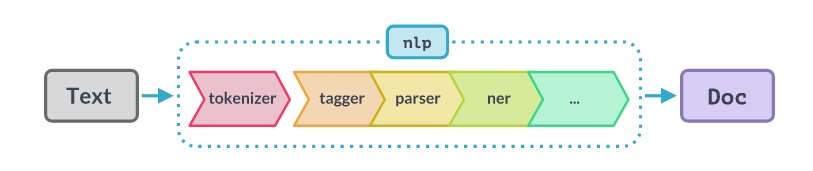
Source: Language Processing Pipelines · spaCy Usage Documentation
Custom Train spaCy v3 NER Pipeline
To train a spaCy NER pipeline, we need to follow 5 steps:
- Training Data Preparation, examples and their labels
- Conversion of data to .spacy format
- Creating the config file for training the model
- Filling the config file with required parameters
- Run the Training
In spaCy, a model is trained in an iterative process, in which the model’s predictions are compared against the labels(ground truth) in order to compute the gradient of the loss. The gradient of the loss is then used to update the model weights through the backpropagation algorithm. The gradients indicate how much the weight values should be adjusted so that the model’s predictions become more similar or closer to the provided labels over time.

Source: Training Pipelines & Models · spaCy Usage Documentation
Data Preparation
For data preparation, I have used the NER annotation tool
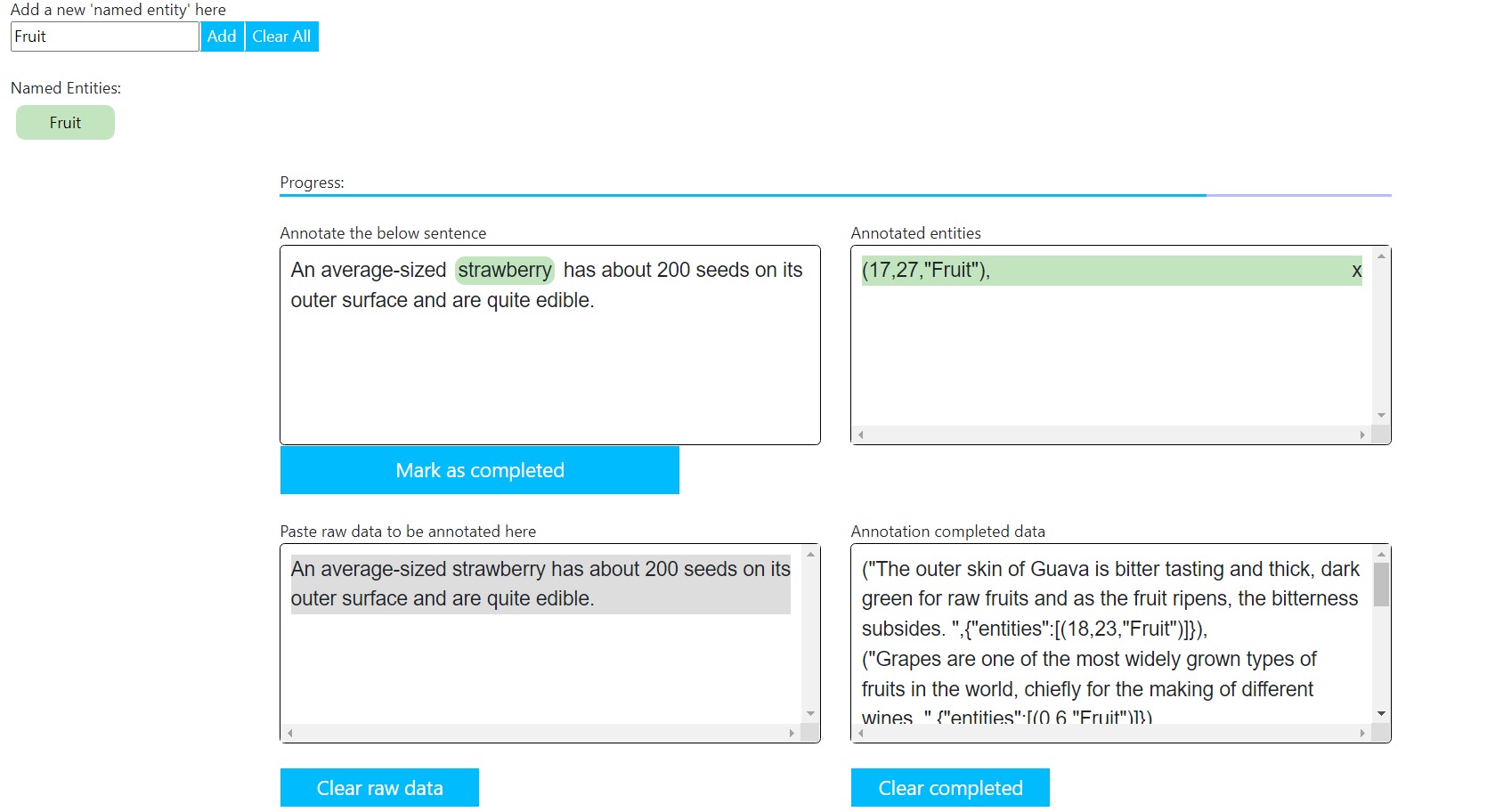
In the interface, we need to define the entity type and paste the raw data we need to annotate and select the word for the required entity and click `Mark as completed`. Once done with the samples, copy the annotated data.
Sample:
("An average-sized strawberry has about 200 seeds on its outer surface and are quite edible.",{"entities":[(17,27,"Fruit")]})
Conversion to .spacy format
In Google colab, spacy is pre-installed, and if we want to run it locally then we need to install the spacy package using the following command in a notebook
!pip install -U spacy
To convert data to spacy format, we need to create a DocBin object which will store our data. We will iterate through our data and add the example and the entity label to the DocBin object and save the object to .spacy file
db = DocBin() # create a DocBin object
for text, annot in tqdm(train): # data in previous format
doc = nlp.make_doc(text) # create doc object from text
ents = []
for start, end, label in annot["entities"]: # add character indexes
span = doc.char_span(start, end, label=label, alignment_mode="contract")
if span is None:
print("Skipping entity")
else:
ents.append(span)
doc.ents = ents # label the text with the ents
db.add(doc)
db.to_disk("./train.spacy") # save the docbin object
Create Config file
To create a config file we need to go to the spacy training quickstart guide.
On the Config page, select `ner` as components and hardware based on system availability, and also we can select to optimize for efficiency (faster inference, smaller model, lower memory consumption) or higher accuracy (potentially larger and slower model), It will impact the choice of the architecture, pretrained weights, and the hyperparameters.
Once completed, download the config file by clicking the download button on the bottom right side.
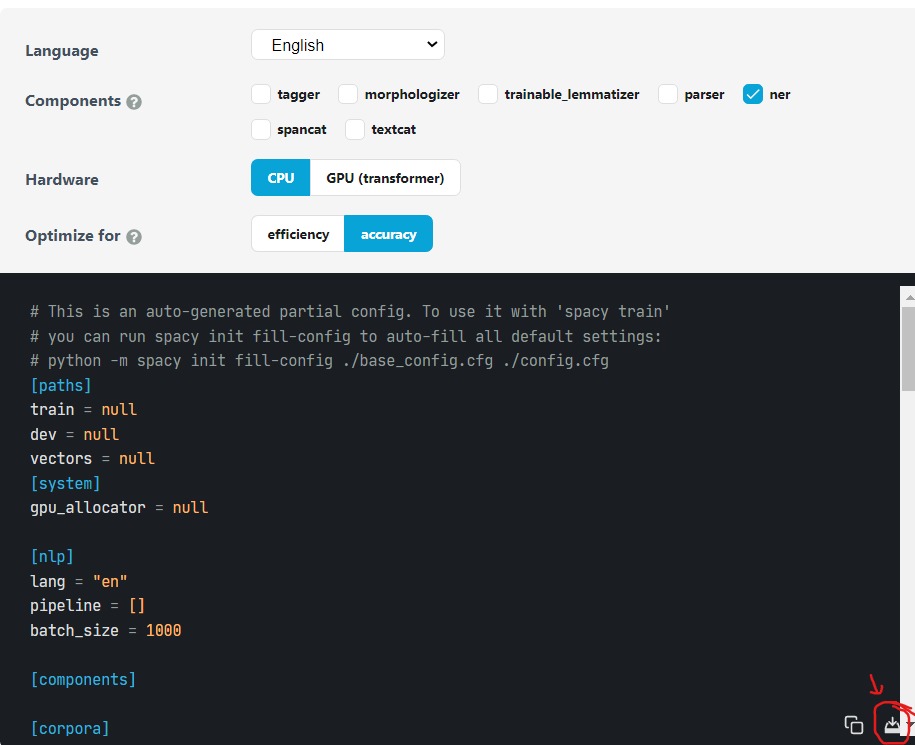
Source: Training Pipelines & Models · spaCy Usage Documentation
After we have saved the config file to `base_config.cfg`, we can fill the remaining fields.
Fill remaining fields
To fill the remaining fields, use the following command (use ‘!’ if running in notebook or colab)
!python -m spacy init fill-config base_config.cfg config.cfg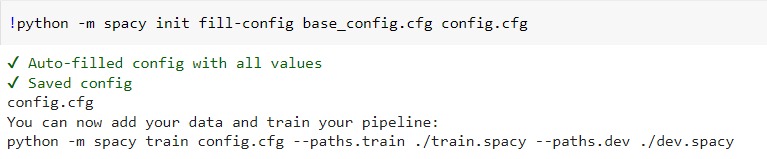
The command will create a `config.cfg` file, that we will use for training our NER pipeline.
The config file contains several parameters needed for training such as learning rate, optimizer, max_steps, and many others. Try to change according to the needed configuration and knowledge.
Training
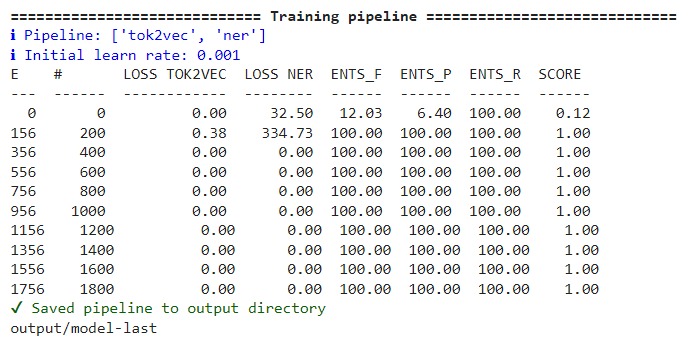
To train the custom pipeline, run the following command
!python -m spacy train config.cfg --output ./output --paths.train ./train.spacy --paths.dev ./train.spacy
As we have not created a validation set we will use the training file as validation, however, for a larger dataset, we should create a separate validation set to validate our model performance.
In Google colab, `en_core_web_sm` is already installed and if are running it locally then we can install it using the following command in the notebook
!python -m spacy download en_core_web_sm
If the above command throws error due to `en_core_web_lg` vector, then open the `config.cfg` file and change the vectors parameter to `en_core_web_sm`.
[paths] train = null dev = null vectors = "en_core_web_sm" init_tok2vec = null
If we want to use the large model, we can download it using the following command
!python -m spacy download en_core_web_lg
Once the pipeline is trained, it will store the best model in the output directory which we can load to test on other examples.
Load Trained model
To load the model, we need to use spacy.load(path)
nlp1 = spacy.load(r"./output/model-best") #load the best model
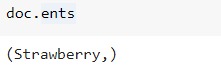
Let’s test it out on some text,
doc = nlp1("Strawberry is a luscious, red fruit grown on plants belonging to the Rose or Rosaceae family.") # input sample text
doc.ents
We can visualize the results using displacy, we can provide the custom color dictionary for the entities we want and assign it as options
colors = {'Fruit': "#85C1E9"}
options = {"ents": ['Fruit'], "colors": colors}
spacy.displacy.render(doc, style="ent", jupyter=True, options=options)

Conclusion to Named Entity Recognition
Isn’t it cool, that we have trained our custom Named Entity Recognition pipeline using spacy v3 with much ease?
You can try it out with your own annotated dataset and invent something new.
The notebook can be found on GitHub.
Hope you liked my article on spaCy Named Entity Recognition? Share your feedback and suggestions in the comment below. Connect with me on Linkedin.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.








Hi Deepak, Could you please explain if we need a test dataset at all given we can already see the different performance metrics of the model trained by the end of training? If yes, how will that be used?
Cool, another great tool is Textraction.ai: