YOLOv7- Real-time Object Detection at its Best
This article was published as a part of the Data Science Blogathon.
Introduction
To achieve complete insight into image or video understanding, we should not only focus on classifying different images but also try to estimate the position of objects in each image precisely. This task is mainly referred to as object detection, which normally consists of different subtasks such as face detection, vehicle detection, person detection, etc. As one of the fundamental computer vision problems, object detection algorithms can provide crucial information for semantic understanding of images and videos and are responsible for many industrial applications, such as image classification, face recognition, autonomous driving, and human behavior analysis. Meanwhile, inheriting these capabilities from the family of neural networks and related learning systems, the progress in these fields greatly impacts the computer vision field and its reach towards different horizons. Let’s have a quick comparison.
Focusing on Object detection models, there are many different object detection models which perform well for certain use cases, but the recent release of YOLOv7, where the researcher claimed that it outperforms all known object detectors in both speed and accuracy and has the highest accuracy 56.8% AP among all known real-time object detectors. The proposed YOLOv7 version E6 performed better than transformer-based detectors like SWINL Cascade-Mask R-CNNR-CNN in terms of speed and accuracy. YOLOv7 outperformed YOLOX, YOLOR, Scaled-YOLOv4, YOLOv5, DETR, Deformable DETR, DINO-5scale-R50, and Vit-Adapter-B. In further reading, we will see what made YOLOv7 outperform these models.
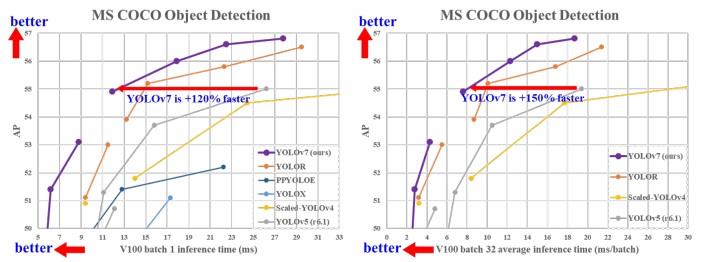
Table of contents
Model Re-parameterization
This technique can significantly increase the performance of the architecture. Model re-parameterization technique merges multiple computational modules into one at the inference stage, thus giving us better inference throughput. It can be regarded as an ensemble technique and can be divided into two categories, i.e., module-level ensemble and model-level ensemble. There are two methods for model-level reparameterization. One is to train multiple identical models with different training data and then average the weights of all the models. The second method is that it performs a weighted average for the weights of models at different iterations. Whereas the Module-level method splits a module into multiple identical or different module branches during training and integrates the branched modules into one during inference.
Model Architecture
Extended efficient layer aggregation networks (E-ELAN)
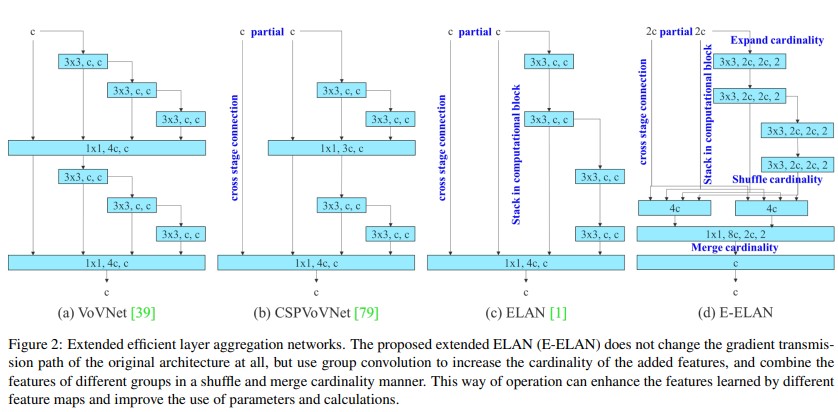
Source: YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object
detectors
Extended efficient layer aggregation networks primarily focus on a model’s number of parameters and computational density. The VovNet (CNN seeks to make DenseNet more efficient by combining all features only once in the last feature map) model and the CSPVoVNet model analyses the influence of the input/output channel ratio and the element-wise operation on the network inference speed. YOLO v7 extended ELAN and called it E-ELAN. The major advantage of ELAN was that by controlling the gradient path, a deeper network can learn and converge more effectively.
E-ELAN majorly changes the architecture in the computational block, and the architecture of the transition layer is entirely unchanged. It uses expand, shuffle, and merge techniques which enhances the learning ability of the network without destroying the original gradient path. The strategy here is to use group convolution to expand the channel and number of computational blocks, which applies the same group parameter and channel multiplier to all the computational blocks of a computational layer. Then, the feature map calculated by each computational block is shuffled and then concatenated together. Hence, the number of channels in each group of the feature maps will be equal to the number of channels in the original architecture. Finally, merge these groups of feature maps. E-ELAN also achieved the capability to learn more diverse features.
Model scaling for concatenation-based models
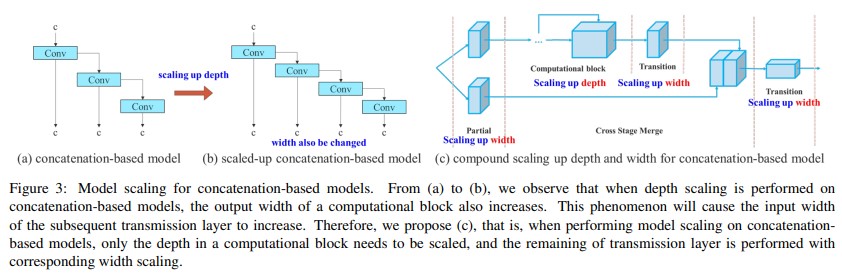
The main motive of model scaling is to regulate a number of the model attributes and generate models comprised of various scales to increase different inference speeds. However, if these methods are applied to the concatenation-based architecture when cutting down or scaling up is performed in-depth, there will be an increase and decrease within the in-degree of a translation layer which is straight away after a concatenation-based computational block.
We can infer that can’t be analyzed different scaling factors separately for a concatenation-based model but must be considered together. Take scaling-up depth as an example, such an action will cause a ratio change between the input channel and output channel of a transition layer, which can cause a decrease in the hardware usage of the model. YOLO v7 compound scaling method can maintain the properties that the model had at the initial design and maintains the optimal structure still, this can be because while scaling the depth factor of a computational block, one should also consider calculating the change of the output channel of that block. Then, perform width factor scaling with the identical amount of change on the transition layers, this maintains the properties that the model had at the initial design and maintains the optimal structure.
Trainable Bag-of-freebies
Planned re-parameterized convolution
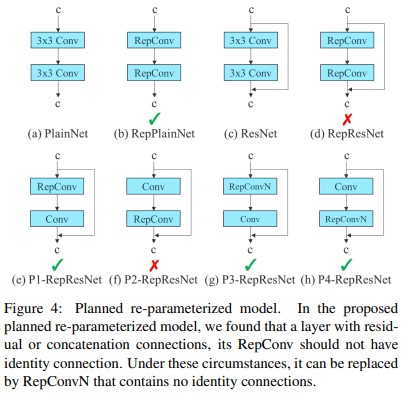
YOLOv7 proposed planned re-parameterized convolution. In this proposed planned re-parameterized model, authors had found that a layer with residual or concatenation connections, its RepConv should not have an identity connection. Under these circumstances, it can be replaced by RepConvN which contains no identity connections.
RepConv combines 3 × 3 convolutions, 1 × 1 convolution, and identity connection in one convolutional layer. After analyzing the combination and corresponding performance of RepConv and different architectures authors used RepConv without identity connection (RepConvN) to design the architecture of planned re-parameterized convolution. According to the paper, when a convolutional layer with residual or concatenation is replaced by re-parameterized convolution, there should be no identity connections.
Coarse for Auxiliary and Fine for Lead Loss
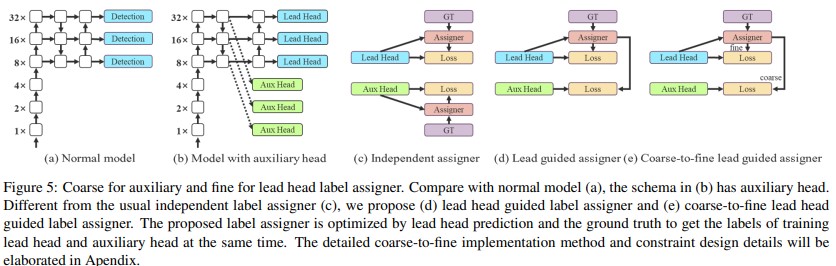
The Deep supervision technique is often used in training deep neural networks. It adds an extra auxiliary head in the middle layers of the network, and the shallow network weights with assistant loss as the guide. Here in yolov7 authors call the head responsible for the final output the lead head, and the head used to assist in the training is called the auxiliary head.
Lead head guided label assigner
It is mainly calculated based on the prediction result of the lead head and the ground truth, which generates a soft label through the optimization process. This set of soft labels will be used as the target training model for both the auxiliary head and lead head. According to the paper, the lead head has a relatively strong learning ability, so the soft label generated from it should be more representative of the distribution and correlation between the source data and the target.
Coarse-to-fine lead head guided label assigner
It uses the predicted result of the lead head and the ground truth to generate a soft label. However, in the process, it generates two different sets of soft labels, that is the coarse label and fine label, where the fine label is the same as the soft label generated by the lead head guided label assigner, and the coarse label is generated by allowing more grids to be treated as a positive target. This mechanism allows the importance of fine and coarse labels to be dynamically adjusted during the training process.
What are the latest features in YOLOv7?
- Enhanced Features: YOLOv7 has upgraded capabilities for faster and more accurate object detection.
- Improved Object Detection: It is better at quickly and accurately recognizing objects in images and videos.
- Versatility: The enhancements make YOLOv7 more robust and suitable for various tasks and applications.
Collectively, these improvements make YOLOv7 a more effective and advanced object detection model.
Training YOLOv7
Now let us train yolov7 on a small public dataset.
I suggest you use Google Colab for training. Create a new notebook and change the runtime type to GPU and execute the below code. This will clone the yolov7 repository and install the necessary modules in the colab environment for training.
# Download YOLOv7 repository and install requirements
!git clone https://github.com/WongKinYiu/yolov7
%cd yolov7
!pip install -r requirements.txt
Then, we will download the dataset and extract it into a folder. Execute the below cell to download and extract the dataset. The dataset is also available here. The dataset contains 7 classes of aquatic animals.
!gdown https://drive.google.com/u/1/uc?id=1pmlMhaOw9oUqIH7OZP8d0dBKVOLqAYcy&export=download !unzip /content/yolov7/data.zip -d dataset
Once the dataset is downloaded, we need to download the YOLOv7 weight file, since training from scratch takes more time, we will finetune already pretrained weight on our dataset. Here we will download yolov7.pt
%cd /content/yolov7
!wget "https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7.pt"
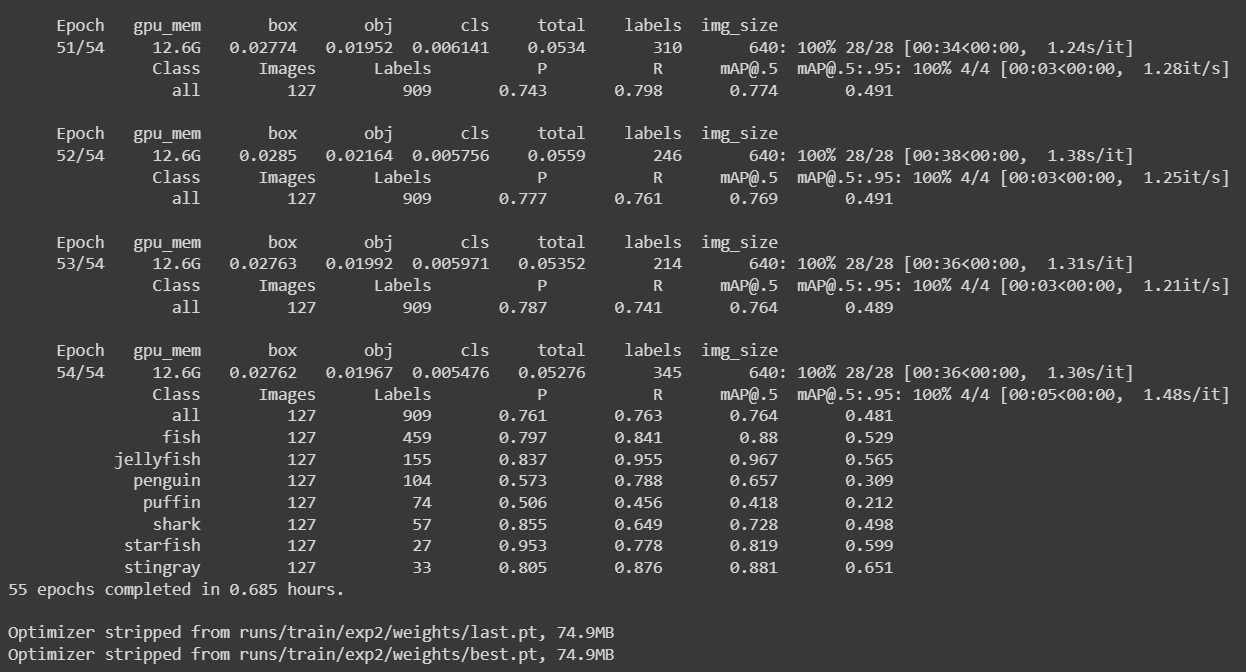
Now we are good to go for the training. We will train the model for 55 epochs with a batch size of 16. For better results, longer training is suggested (more epochs). Make sure the paths are correct in the ‘data.yaml’ file inside the ‘yolov7/dataset’ folder, also make sure paths are correct in the training command and execute the below code. This will start the training.
%cd /content/yolov7 !python train.py --batch 16 --cfg cfg/training/yolov7.yaml --epochs 55 --data /content/yolov7/dataset/data.yaml --weights 'yolov7.pt' --device 0
Source: Author
Once the training is completed, the best weight is saved at the mentioned path, usually inside the ‘runs’ folder. Once we get the weight file, we can be ready for evaluation and inferencing.
Now for testing run the below piece of code. This will perform inference on the test folder. Make sure that the weight is set to trained weights and here we will be using the confidence threshold of 0.5, you can train more and play around with the parameters for better performance.
# Run evaluation
!python detect.py --weights runs/train/exp/weights/best.pt --conf 0.5 --source /content/yolov7/dataset/test/imagesTo view the inference images, run the below code. This will display the output images one by one.
# display inference on ALL test images
import glob
from IPython.display import Image, display
i = 0
limit = 10000 # max images to print
for imageName in glob.glob('/content/yolov7/runs/detect/exp/*.jpg'): #assuming JPG
if i < limit:
display(Image(filename=imageName))
print("n")
i = i + 1

Source: Author (output from the custom-trained model)
The Notebook is also available here.
Summary
YOLOv7 Architecture
· Extended Efficient Layer Aggregation Network (E-ELAN)
E-ELAN mainly concentrates on the computational density and parameters of the model architecture. The major advantage of ELAN was that by controlling the gradient path, a deeper network can learn and converge more effectively.
· Model Scaling for Concatenation based Models
The model scaling method for concatenation-based models is performed by scaling depth in a computational block and width scaling in the remaining transmission layers.
Trainable Bag of Freebies
· Planned re-parameterized convolution
In Planned re-parameterized models, a layer with residual or concatenation connections, its RepConv should not have an identity connection, It can be replaced by a RepConvN layer that contains no identity connections.
· Coarse for auxiliary and fine for lead loss
This label assigner is optimized by lead head predictions and ground truth labels to get the labels of the training lead head and auxiliary head at the same time.
Conclusion
Key takeaways
– This is the in-depth analysis of YOLOv7 architecture and the custom training procedure.
– We can use this model for detection as well as tracking.
– The same can be used to count the objects in frames.
Yolov7 is the new state-of-the-art real-time object detection model. You can use it for different industrial applications. Also, you can optimize the model, that is, converting the model to ONNX, TensorRT, etc, which will increase the throughput and run the edge devices. In this blog, we discussed only the basic step for training YoloV7.
Thank you, and Happy Learning.😄
Frequently Asked Questions
YOLOv7 is a newer version with improvements over YOLOv6, offering better features and performance.
The main part, or backbone, of YOLOv7, is the core component that helps it understand images more effectively.
Yes, YOLO is faster than TensorFlow for recognizing objects in images or videos.
YOLOv7 has advantages such as quick and accurate object recognition, making it valuable for various tasks.
Reference: https://arxiv.org/abs/2207.02696
My LinkedIn
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am an enthusiastic AI developer, I love playing with different problems and building solutions.







