Fine-Tuning BERT with Masked Language Modeling
This article was published as a part of the Data Science Blogathon.
Introduction
One of the finest breakthroughs in Natural Language Processing is the development the Transformer model. Anyone interested in taking a deep dive into the architecture of the entire transformer model can refer to this link. From a 10000 feet height, the transformer is an encoder-decoder model with multiple self-attention heads. The rationale behind the transformer model was to develop a state-of-the-art model for performing Neural Machine Translation. However, apart from NLP tasks, for example, Language Translation, other tasks like Sentiment Analysis, Named Entity Recognition, Question-Answering, and Part of Speech Tagging, etc., do not need the entire transformer model but only the encoder or the decoder part.

BERT stands for Bidirectional Encoder Representations from Transformers that replicates the encoder architecture of the transformer model with a deeper encoder stack. The model is named bidirectional because it can simultaneously gather the context of a word from either direction. The researchers at Google Brain have designed the BERT model like a pre-trained model that can be fine-tuned by adding a single model head to solve the various NLP problems. To put more perspective into this, the core BERT model is the same for the two specific NLP tasks, Sentiment Analysis and Named Entity Recognition, but the model head changes for the two tasks. A conceptual diagram for the same is:
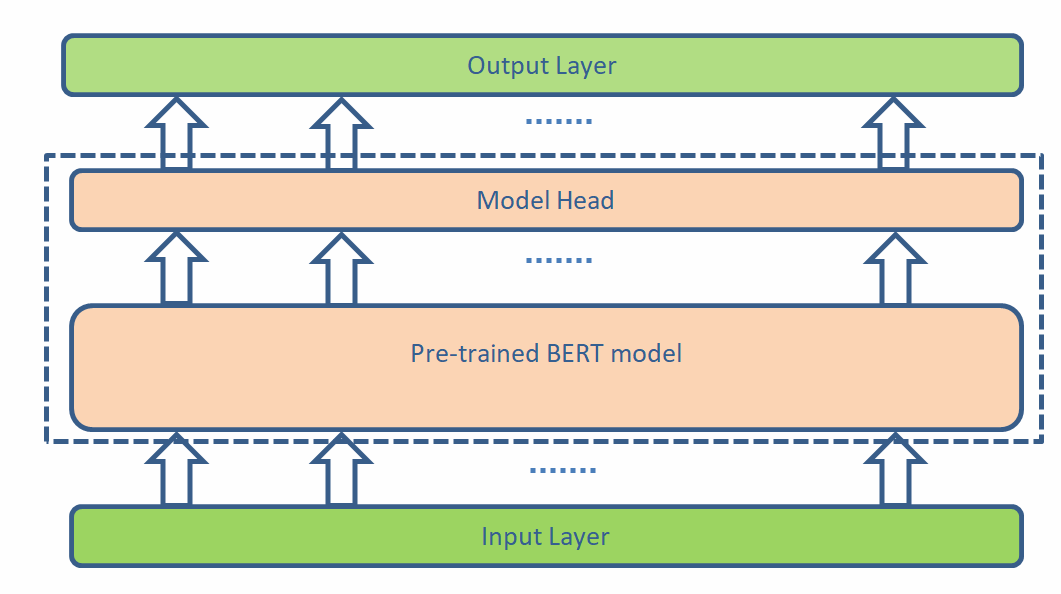
Motivation
Transfer learning is at the very core of the tremendous development in Computer Vision. In transfer learning, a deep Neural Network is pre-trained on a large dataset, for example, the ImageNet dataset, which is then fine-tuned on a task-specific dataset. The benefits of transfer learning are:
- Training requires very little
data. - The training time is less.
- Requires very less computation
power. - The overall carbon footprint of
the world is less.
However, the same was not popular in natural language processing, and people had to design their models, trained from the very ground up, and thus not able to reap the benefits of transfer learning. Developing a pre-trained language model like BERT was a boon to the NLP community resulting in performing several NLP tasks with minimum time and compute.
Detailed Architecture of BERT Model
As mentioned earlier, BERT is multiple layers of Transformer encoders stacked one over the other. Depending upon the number of encoder layers, the number of self-attention heads, and the hidden vector size, BERT is categorized into two types: BERTBASE and BERTLARGE. The following table gives a numerical comparison between the two:

Below is the pictorial representation of a BERTBASE model used for the Masked Language Modeling task:
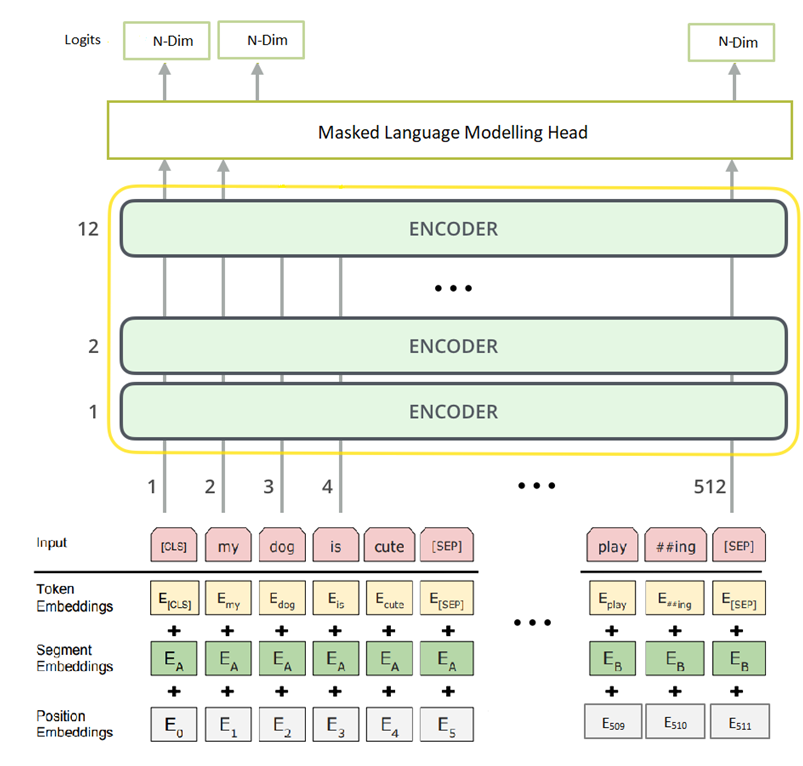
The input to the model consists of three parts:
- Positional Embedding takes the index number of the input token.
- Segment Embedding tells the sentence number in the sequence of sentences.
- Token Embedding holds the set of Tokens for the words given by the
tokenizer.
All the embeddings are added and fed into the BERT model. As shown above, BERTBASE can ingest a maximum number of 512 tokens. Input to the model traverses sequentially through a stack of 12 encoder layers (L=12), where each has 12 self-attention heads (A=12) and outputs the same number of tokens as in the input, and has a Dimension of 768. In the final layer, a model head for MLM is stacked over the BERT core model and outputs the same number of tokens as in the input. And the Dimension for all the tokens is changed to the size of the input vocabulary given by N. Finally, a softmax function applied to the output logits gives the predicted token by the model.
Tokenizer
A WordPiece tokenizer tokenizes the input text. The tokenizer has a vocabulary of size 30000. The first token (at index position 0) given by the tokenizer at the input is a Special token given by [CLS] called the Classification token. For Classification tasks like Sentiment Analysis etc., we use the final hidden state of the last encoder layer corresponding to the [CLS] token. We use a separator token given by [SEP] for indicating two different sentences. And for masking a word, the token [MASK] is used by the tokenizer. Apart from these Special tokens, others are the regular ones. The output of the tokenizer has three parts:
- input_ids: These are the actual tokens for the input string.
- attention_mask: These are a set of binary tokens indicating which
tokens are the actual input tokens and which are the padding tokens. - token_type_ids: These are binary tokens specifying whether the token
belongs to the first sentence or the second one in a sequence of two
sentences.
If all of these seem confusing, do not worry, I will clear the air in the code section. For now, grasp as much as you can.
Pre-training the BERT Model
As the objective behind BERT is transfer learning, pre-training remains at the heart of the entire discussion. In the original research paper, the core BERT model is trained on two self-supervised learning tasks with two model heads as given below:
- Masked Language Model: In this pre-training approach, some input tokens are masked with the [MASK] token. Then the model is trained to predict the masked Tokens by gathering the context from the surrounding Tokens. The researchers, in their experiments, found the best results by masking around 15% of the input tokens at random.
- Next Sentence Prediction: This is a binary classification task in which we use the output token corresponding to the [CLS] token for modeling. The objective is to predict whether the second sentence is the next sentence. For training the model, we manually create the dataset, such that 50% of the time, we give the actual sentence as the next sentence with a target label of 1, and 50% of the time, the second sentence is a random sentence with a target label of 0
Finally, the overall loss of the pre-training model is the mean of the two tasks mentioned above.
Fine-tuning the BERT Model
In the previous sections, we have got a gist of the architecture of a vanilla BERT model. Here we will fine-tune an already pre-trained BERT model using masked language modeling.
Importing the libraries
from transformers import BertTokenizer, TFBertForMaskedLM import tensorflow as tf import os import numpy as np import re import matplotlib.pyplot as plt
Loading the pre-trained BERT model
We are importing a pre-trained BERT tokenizer and a BERT model with an MLM head from the Hugging Face repository.
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = TFBertForMaskedLM.from_pretrained('bert-base-uncased')
As we can see, the Wordpiece tokenizer used for fine-tuning is BertTokenizer. The model used is TFBertForMaskedLM, a BERT model with an MLM head that can accept only Tensorflow tensors. In both of them, the check-point used is bert-base-uncased. Let’s look at the model summary:
model.summary() Layer (type) Output Shape Param # ================================================================= bert (TFBertMainLayer) multiple 108891648 mlm___cls (TFBertMLMHead) multiple 24459834
=================================================================
From the summary, we can see that there are two blocks of layers, one is the core BERT layer and the other is the MLM model head layer.
Dataset
The dataset that we will use for fine-tuning the BERT-MLM model is the textbook named The Hunger Games. The same can be downloaded using this link. Let’s read the text from a local directory:
with open('The Hunger Games.txt','r') as f:
file = f.read().split(".")
We are taking a single sentence ending in a full stop as input to the model. As we are not training on NSP, we are not taking a set of two sentences. A closer look at the text file will reveal that it contains a lot of punctuations and other non-ASCII characters which, do not add much value to the model and hence are cleaned.
def clean_text(line):
line = re.sub(r'-+',' ',line)
line = re.sub(r'[^a-zA-Z, ]+'," ",line)
line = re.sub(r'[ ]+'," ",line)
line += "."
return line
Also, it is observed that certain sentences are small, and masking a few tokens would remove a significant amount of context from the sentence. Hence, sentences less than 20 words are removed from the corpus.
text_lst = []
len_lst = []
for line in file:
if len(line.split(" ")) >=20:
line = clean_text(line)
text_lst.append(line)
len_lst.append(len(line.split(" ")))
The code above the list text_lst, holds all the sentences with a length greater than or equal to 20, and the list len_lst holds all the sentences’ length’. We can check the number of sentences available after filtering with the code len(text_lst) which comes out as 1567 and we can also check the longest sentence with the code max(len_lst) which is 87.
Tokenizing the data
The input is a list of sentences that can not be fed directly into any deep learning model because what a machine can understand is numbers and not texts. Therefore, we are tokenizing the text into some numbers, as shown in the below lines of code.
inputs = tokenizer(text_lst,max_length=100,truncation=True,padding='max_length',return_tensors='tf') print(inputs.keys()) >> dict_keys(['input_ids', 'token_type_ids', 'attention_mask'])
In the tokenizer method, text_lst is the text corpus, max_length suggests the maximum number of allowable input tokens (the maximum is 512 for BERT base), and truncation set to True indicates that if the input size is more than the max_length, then the token from index number equal to max_length would be truncated i.e., for our example input tokens from index 100 would be dropped, padding set to True indicates the input length shorter than the max_length are padded, with padding token 0 and lastly, return_tensors indicates in what format do we want the output tensor and tf suggests that we expect tensorflow tensor. The tokenizer here returns three fields, as we have mentioned earlier.
Now if we look at the “inputs” with the code print(inputs), we can see that the input_ids tensor is of shape 1567×100, and each row starts with the token 101, which is the id for the Special token [CLS] and ends with 0 which is the padding token indicating that the sentence length is less than 100. Also, there is a Special token 102, the [SEP] token, which is not visible, indicating the end of a sentence. Secondly, the token_type_ids are all 0 as there is only a single sentence as input. Finally, the attention_mask has ones at locations for the actual input tokens and zeros for the padding tokens.
Adding labels
The objective of a masked language model is to predict the masked words by gathering context from the surrounding words. In other words, we can say that we need to reconstruct the original sentence at the output from the masked sentence at the input. Therefore the target labels are the actual input_ids from the tokenizer. Hence we add the target labels to the dataset as follows:
inputs['labels'] = inputs['input_ids'] inputs.keys() >> dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'labels'])
Masking input tokens
In the original research paper, 15% of the input tokens were masked, of which 80% were replaced with [MASK] tokens, 10% were replaced with random tokens, and another 10% were left as is. However, in our fine-tuning task, we are replacing 15% of the input tokens except for the special ones with only [MASK] i.e., we will not replace token numbers 101,102, and 0 with mask token 103. In the following lines of codes, the same logic is implemented:
inp_ids = []
lbs = []
idx = 0
for inp in inputs.input_ids.numpy():
actual_tokens = list(set(range(100)) -
set(np.where((inp == 101) | (inp == 102)
| (inp == 0))[0].tolist()))
#We need to select 15% random tokens from the given list
num_of_token_to_mask = int(len(actual_tokens)*0.15)
token_to_mask = np.random.choice(np.array(actual_tokens),
size=num_of_token_to_mask,
replace=False).tolist()
#Now we have the indices where we need to mask the tokens
inp[token_to_mask] = 103
inp_ids.append(inp)
idx += 1
inp_ids = tf.convert_to_tensor(inp_ids)
inputs['input_ids'] = inp_ids
The code inputs can verify the random replacements with [MASK] tokens.input_ids
Training the model
Now that we are ready with the input and output data, we can proceed to fine-tune the BERT model using MLM. We are using tensorflow background for training with keras. We are using an Adam optimizer with a learning rate of 0.0001 and the loss function is SparseCategoricalCrossentropy with from_logits set to True as the output given by the model is not normalized with a softmax function. Also, we have taken a batch size of 8 which may vary depending upon the hardware set-up and we will run the model for 10 epochs and observe the loss against each epoch.
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.0001),loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)) history = model.fit([inputs.input_ids,inputs.attention_mask],inputs.labels,verbose=1,batch_size=8,epochs=10)
After training, let’s plot the loss vs. epoch curve as follows
losses = history.history['loss']
fig = plt.figure(figsize=(5,5))
ax1 = fig.add_subplot(111)
ax1.plot(range(len(losses)),losses)
ax1.set_xlabel("Epochs")
ax1.set_ylabel("Loss")
ax1.set_title("Epoch vs Loss")
plt.grid()
plt.show()
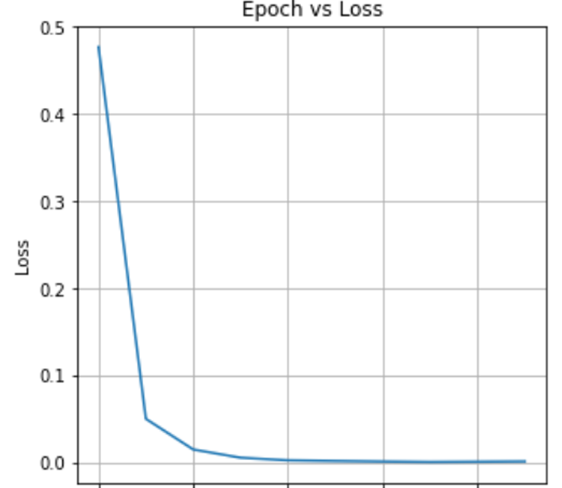
As we can see, the loss is constantly decreasing, which indicates that the model is converging. By the 6th epoch, the loss is not decreasing, which means that the model has fully converged and is ready for inference.
Testing with a query point
Now that the model is fine-tuned with our data let’s test the model with a query point.
query = "Good morning [MASK], have a [MASK] day" inp = tokenizer(query,return_tensors='tf') mask_loc = np.where(inp.input_ids.numpy()[0] == 103)[0].tolist() out = model(inp).logits[0].numpy() predicted_tokens = np.argmax(out[mask_loc],axis=1).tolist() tokenizer.decode(predicted_tokens) #outputs >>'everybody good'
The query point in the above lines of code is a string with two mask tokens. After tokenizing the query text, we feed the tokenized inputs to the model for predicting the mask tokens. And as we can see, the two mask tokens predicted by the model are everybody and good and as such, the suggested text by the model is “Good morning everybody”, have a good day which seems a reasonable prediction.
Conclusion
Training a BERT model for many of us is an enigma, given that there is no clear documentation about the same. The original research paper only scratches the surface of the training process. From our discussion so far on BERT, we have seen the following points in detail:
- The basic block diagram of BERT for MLM.
- The motivation behind developing the BERT model.
- The detailed architecture for training the BERT model.
- Tokenizer for training the model.
- The two self-supervised tasks used for pre-training the BERT model.
- A detailed code walk-through for fine-tuning the model using an MLM head.
I hope this article gives a solid foundation on both pre-training and fine-tuning the BERT model using the masked language model head. If you have any doubts, please comment on your concerns below. Also, in a future article, I intend to fine-tune a BERT model with a next sentence prediction model head.
Thanks for reading!!!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.








Thanks for the interesting article. I need to store and save the fine-tuned model to use it at other times. What should I do?