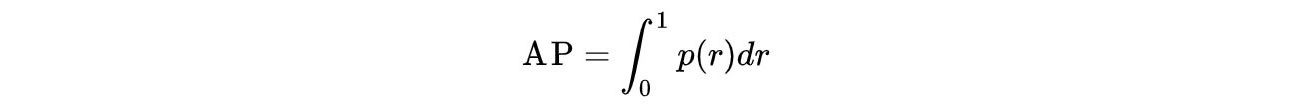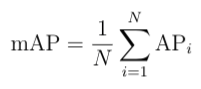Artificial neurons are utilized in deep neural networks for object detection. These artificial neurons are similar to humans composed of neurons. Thus, object detection refers to the detection and localization of objects in an image that belongs to a predefined set of classes. People can easily detect and identify the objects present in the image. The human visual system is fast and accurate and can perform complex tasks such as identifying multiple objects and detecting obstacles with little awareness. With the accessibility of large amounts of data, High-Speed GPUs, and optimized algorithms, we can now simply train computers to identify, classify and detect the multiple categories of objects within an image with high precision and accuracy. Commonly, object detection can be classified into two categories,
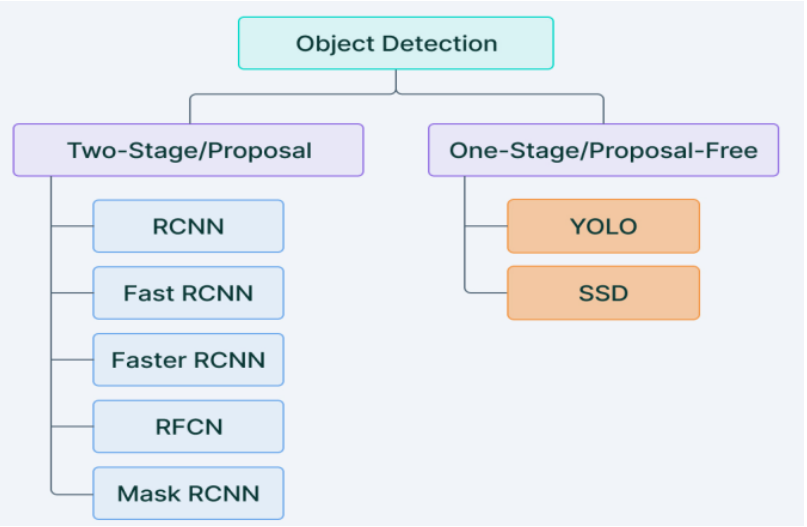
1. Two-stage detector
Where detection is complete in two steps, the first step uses regional design networks to create areas of interest with a high probability of being an object. The second step is object detection, which performs the final classification and regression of the bounding box of the objects. RCNN, Fast RCNN, SPPNET, Faster RCNN, etc., are some of the two-stage detectors.
2. One-stage detector
where object detection is a simple regression problem that takes input and learns
probability classes and bounding box coordinates. YOLO, YOLO v2, SSD, RetinaNet, etc., fall under one phase detector. Object detection is an advanced form of imaging classification where a neural network predicts objects in an image and draws attention to them in the form of bounding boxes.
Our analysis mainly aims to compare the operational performance and accuracy of the YOLO and MobileNet SSD object detection techniques in various aspects and highlight some of the notable features that make this study stand out.
What exactly is YOLO?
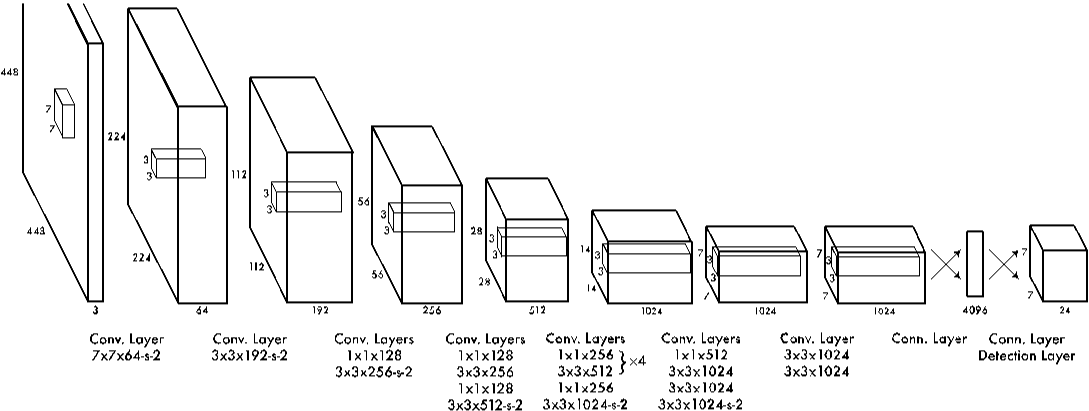
The term YOLO is defined as You Only Look Once. The YOLO algorithm performs real-time object detection using a convolutional neural network (CNN). As the name suggests, the object detection algorithm only needs a single forward propagation through the neural network. This means that the prediction in the whole frame is made in a single algorithm run. CNN is used to predict different probability classes and boundary fields simultaneously.
The main features of YOLO are speed, high accuracy, and learning ability.
Speed – This algorithm has improved speed for real-time object detection.
High Accuracy – This technique gives accurate outcomes with minimal background errors.
Learning Ability – The excellent learning ability of this algorithm allows it to learn object representations and apply them in object detection.
How does YOLO work?
The operation of the YOLO algorithm can be explained using three techniques as follows:
1. Residual blocks:
First, the image is divided into different grids. Each grid has dimension S x S. The process of converting the input image to grids is shown in the following figure. Each grid cell will detect objects that appear in it.
2. Bounding box regression:
A bounding box is an outline that highlights an object in an image with some attributes such as width (bw), height (bh), and class (such as person, car, traffic light, etc.), which is represented by the letter C. The center of the bounding box (bx, would). YOLO uses single bounding box regression to predict objects’ height, width, center, and class.
3. Intersection over Union (IOU):
Intersection over Union (IOU) is a tool in object detection that explains how boxes overlap. YOLO uses IOUs to surround perfect output boxes for objects perfectly. Each cell in the grid is responsible for predicting bounding boxes and their confidence scores. If the predicted bounding box is the same as the actual box, then the IOU equals 1. This technique can eliminate bounding boxes that do not equal the actual box.
In the image above, between the two bounding boxes, the blue box represents the predicted box, while the green box represents the actual box. YOLO algorithms ensure that two bounding boxes are equal.
History of YOLO
YOLO was first introduced by Joseph Redmon, a graduate of the University of Washington, in 2016. It was a milestone in object detection research due to its ability to detect objects in real-time with higher accuracy. The main implementation of Redmons YOLO is based on Darknet, which is a very flexible research framework written in low-level languages and has developed a number of superior real-time object detectors in the field of computer vision: YOLO, YOLOv2, YOLOv3, and YOLOv4.
YOLOv2: YOLOv2 was released in 2017, and its architecture made several iterative improvements over YOLO, including BatchNorm, higher resolution, and anchor boxes.
YOLOv3: Released in 2018, YOLOv3 builds on previous models by adding objectivity scores to bounding box prediction, adding connectivity to backbone layers, and predicting at three separate levels to improve performance on smaller objects.
YOLOv4: YOLOv4 was released in April 2020 by Alexey Bochkovskiy, which introduced improvements such as improved feature aggregation, “free bag” (with augmentations), bug activation, and more.
YOLOv5: Released in June 2020 by Glenn Jocher, YOLOv5 differs from all previous versions as it is a PyTorch implementation rather than a fork from the original Darknet. Like the YOLO v4, the YOLO v5 has a CSP spine and a PA-NET neck. Major improvements include mosaic data expansion and auto-learning bounding box anchoring.
PP-YOLO: Released in August 2020 by Baidu based on YOLO v3. The main goal of PP-YOLO is to implement an object detector with relatively balanced efficiency and effectiveness that can be directly used in current application scenarios rather than designing a new detection model.
Scaled YOLOv4: Released November 2020 by Chien-Yao Wang, Alexey Bochkovsky, and Hong-Yuan Mark Liao. The model uses Cross Stage Partial networks to increase the network size while maintaining YOLOv4 accuracy and speed.
PP-YOLOv2: Again authored by the Baidu team and released in April 2021, it made minor modifications to PP-YOLO for better performance, including adding error activation features and a path aggregation network.
What is MobilenetSSD?
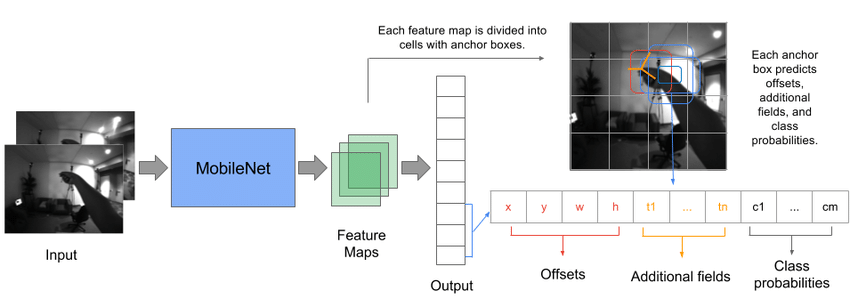
Convolutional neural networks are used to develop a model that consists of multiple layers for classifying given objects into one of the defined classes. These objects are detected using higher resolution feature maps made possible by recent advances in deep learning with image processing. Mobilenet SSD is an object detection model that computes the output bounding box and object class from the input image. This Single Shot Detector (SSD) object detection model uses Mobilenet as a backbone and can achieve fast object detection optimized for mobile devices.
The term SSD stands for Single Shot Detector. The SSD technique is based on a forward convolutional network that generates a collection of fixed-size bounding boxes and a score for the presence of object class instances in those boxes, which come behind by a non-maximal suppression step to create the final detections. Fields contain offset values (cx,cy,w,h) from the default field. The score contains confidence values for the presence of each of the object categories, with a value of 0 reserved for the background.
SSD represents multi-reference and multi-resolution detection techniques. Multi-reference techniques define a set of anchor boxes of different sizes and aspect ratios at different locations in the image and then predict a detection box based on these references. Multi-resolution techniques enable object detection at multiple scales and at different network layers. The SSD network implements an algorithm for detecting multiple object classes in images by generating a confidence score related to the presence of any object category in each default field. It also makes adjustments in the boxes to better fit the shapes of the objects. This network is suitable for real-time applications because it does not resample functions for bounding box hypotheses.
MobileNet
MobileNet is a class of well-organized models called for mobile and embedded vision applications. This class of models is based on a simplified architecture that uses depth-separable convolutions to build lightweight deep neural networks. It decomposes standard convolution into depth convolution and a 1×1 convolution known as point convolution. Deep convolution applies one filter to each input channel in the case of MobileNets. The point convolution then generates a 1×1 convolution to combine the outputs of the depth convolution. A standard convolution has one step for both filtering and combining the inputs into a new set of outputs. But the depth-separable convolution splits it into two layers, a separate layer for filtering and a separate layer for combining. This factorization drastically reduces the computation and model size.
Various metrics have been proposed to measure object localization accuracy. Intersection over Union (IoU), also called the Jaccard index, is commonly used to evaluate the accuracy of detections. It can be calculated as the overlap between the predicted detection and its corresponding ground truth divided by the connection area between the predicted detection and the ground truth. The mean IoU for an image is calculated by taking the IoU of each class and averaging it for binary or multi-class detection problems. This can be applied to all images of the test dataset to have an average IoU value. Another related detection metric is the F1-score (the Dice Coefficient), which is calculated as twice the overlap area divided by the total number of pixels in the detected and ground truth regions. This measure can be represented by the Precision and Recall metrics. It can also be applied to all the target objects present in the image, and we can calculate the average F1 score for all the images of the test dataset. This means that when comparing two models using IoU if the first model is better than the second using this metric, it will also be better to use the F1 score. Taking the average score from the set of detections in the images, the IoU metric tends to penalize quantitatively individual inaccurate detections more than the F1 score, even though both can predict that a given object instance is poorly detected.
Standard metrics commonly used to analyze object detection accuracy and speed include recall, precision, F1 score (F1), mean average accuracy (MAP), and frames per second (FPS). In the target detection process, precision is defined as the ratio of correctly predicted values to the number of all predicted values, and recall is the ratio of the number of accurately found desired results to all predicted values in the sample set. Average Accuracy (AP) is the accuracy across all elements of a pill category as defined in the formula below:
Numerically, MAP is the average value of the sum of APs across all categories, which is used to evaluate the model’s overall performance.
FPS is an indicator commonly used to evaluate the detection speed of a model. The number of frames that can be processed per second is called FPS.
Both detectors can produce acceptable results for different object sizes, lighting conditions, image perspective, partial occlusion, complex backgrounds, and multiple objects in the scene. One of the main strengths of the SSD model is the near elimination of FP cases, which is advantageous in analytics-related applications. On the other hand, YOLOv3 provides better average results. YOLO has problems locating objects correctly, but SSD is faster than the previous progressive for one-shot detectors.
Speed and accuracy are the determining factors for smooth operation for real-time purposes. Variants of YOLO (especially up to YOLOv3) provide excellent accuracy but require computationally intensive hardware. For such devices, this model,
the speed requirement would suffice. MobileNet-SSD V2 also provides a somewhat similar speed to YOLOv5, but lacks accuracy. An SSD might be a better choice when we tend to square measurable to run it on video, so the trade-off between the truth is extremely modest. YOLO is better when accuracy is a consideration rather than going fast. Thus, any of the models can be selected depending on the requirements of different applications.
Conclusion
Real-time detection and tracking of objects on video streams is a key topic for tracking systems in many field applications. The aim of our article is to perform a comparative study of two object recognition systems using CNN to identify objects in images.
Key Takeaways:
We studied and analyzed the YOLO object detection model and the MobileNet SSD model for performance evaluation in different scenarios. Each of the compared models has its unique features and is successful in its respective applications.
YOLO provides better accuracy compared to MobileNet SSD, which provides a faster detection speed.
MobileNet SSD or SSD, a multi-class one-time detector that is faster than previous progressive one-time detectors (YOLO) and significantly correct, indeed as correct as slower techniques that perform express region designs and pooling (including the faster R-CNNs)
MobileNet SSD can be used when the object size is small and the performance dips a touch.
YOLO is used when the object size is small.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
A verification link has been sent to your email id
If you have not recieved the link please goto
Sign Up page again
Loading...
Please enter the OTP that is sent to your registered email id
Loading...
Please enter the OTP that is sent to your email id
Loading...
Please enter your registered email id
This email id is not registered with us. Please enter your registered email id.
Don't have an account yet?Register here
Loading...
Please enter the OTP that is sent your registered email id
Loading...
Please create the new password here
We use cookies on Analytics Vidhya websites to deliver our services, analyze web traffic, and improve your experience on the site. By using Analytics Vidhya, you agree to our Privacy Policy and Terms of Use.Accept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.