Principal Component Analysis Interview Questions
This article was published as a part of the Data Science Blogathon.
Introduction
Principal Component Analysis, or PCA, is a dimensionality-reduction method frequently used to reduce the dimensionality of big data sets by reducing a large collection of variables into a smaller set that retains the majority of the information in the large set.
Reduced dimensionality comes at the expense of accuracy, but the idea of dimensionality reduction is to exchange a little accuracy for simplicity. Because smaller data sets are easier to examine and visualize, and because there are fewer superfluous variables to analyze, analyzing data is easier and faster for machine learning algorithms.
Principal Component Analysis is a critical topic in Machine Learning and can be asked in interviews for Data Engineer, Machine Learning Engineer, and Data Analyst roles. Here are some top Principal Component Analysis interview questions which can be asked in interviews.
Principal Component Analysis Interview Questions
1. What is the curse of dimensionality?
When working with data in greater dimensions, issues arise. As the number of features increases, so does the number of samples, resulting in a complex model. This is known as the curse of dimensionality. Because of the enormous number of features, there is a potential that our model would overfit. As a result, it performs badly on test data because it becomes overly reliant on training data.
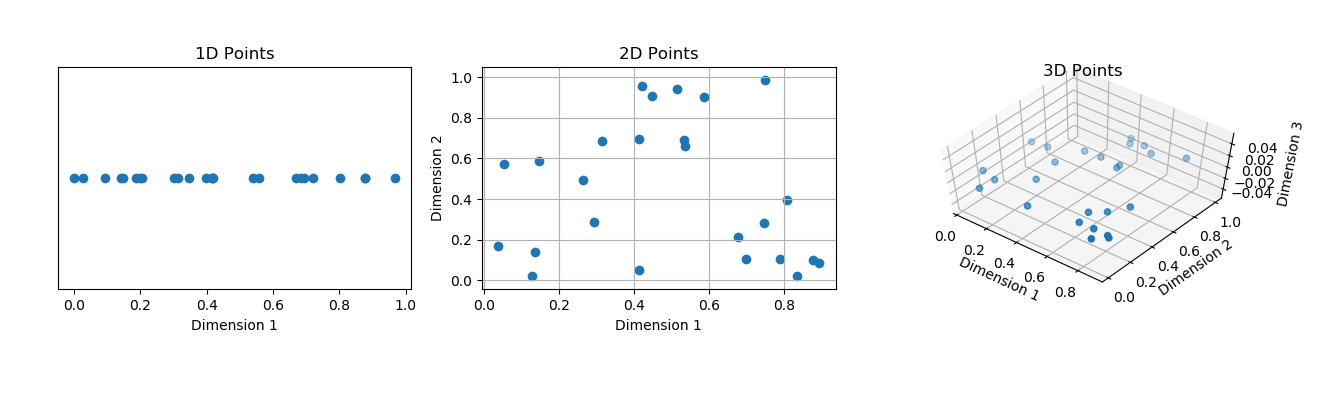
( Source: https://aiaspirant.com/curse-of-dimensionality/)
2. Define Principal Component Analysis (PCA)?
PCA is a well-known dimensionality reduction approach that converts a big set of connected variables into a smaller set of unrelated variables known as principal components. The goal is to eliminate extraneous features while retaining most of the dataset’s variability.
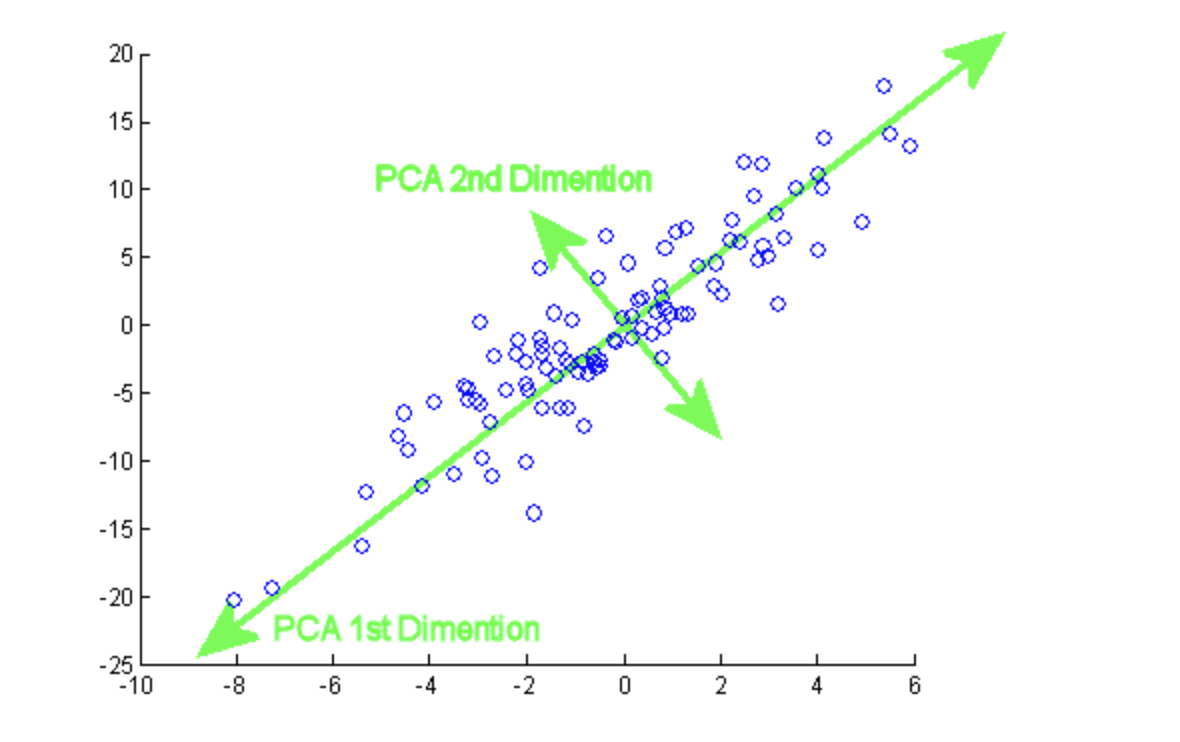
( Source: https://programmathically.com/principal-components-analysis-explained-for-dummies/)
3. Can Principal Component Analysis be used in Feature Selection?
Feature selection is selecting a subset of features from a larger set of features. We obtain the Principal Components axis in Principal Component Analysis, a linear combination of all the original set of feature variables that defines a new set of axes that explain the majority of the variances in the data.
As a result, while Principal Component Analysis performs well in many practical scenarios, it does not result in building a model dependent on a small collection of the original characteristics. Hence, Principal Component Analysis is not a feature selection technique.
4. How to select the first principal component axis?
The first principal component axis is chosen to explain most of the data’s variance and is closest to all “N” observations.
5. What does a Principal Component Analysis’s major component represent?
It denotes a line or axis along which the data fluctuates the most and the line closest to all n observations. The linear combination of observable variables results in an axis or set of axes that explain/explains the majority of the variability in the dataset.
It is the eigenvector of the first main component in mathematics. The eigenvalue for PC1 is the sum of the squared distances, and the singular value for PC1 is the square root of the eigenvalue.
6. What are the disadvantages of dimension reduction?
The reduction process can be computationally demanding. The converted independent variables can be difficult to interpret. As we limit the number of features, some information is lost, and the algorithms’ performance suffers.
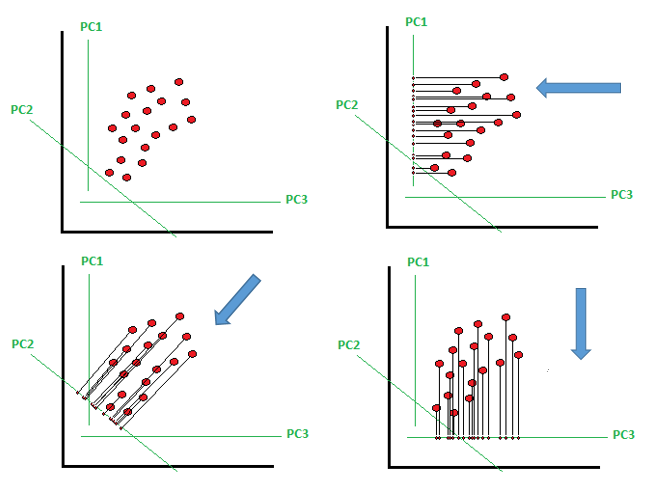
( Source: https://pub.towardsai.net/principal-component-analysis-in-dimensionality-reduction-with-python-1a613006d531?gi=8a01fe2cf8ce)
7. Why do we standardize before using Principal Component Analysis?
We standardize because we must assign equal weights to all variables; otherwise, we may receive misleading recommendations. If all variables are not on the same scale, we must normalize.
8. What happens when the eigenvalues are nearly equal?
PCA cannot choose the primary components if all eigenvalues are roughly equal. This is because all of the major components become equal.
9. What happens if the PCA components are not rotated?
If we do not rotate the components, the effect of PCA will be diminished. Then we must choose additional components to explain the variance in the training data.
10. Can we implement Principal Component Analysis for Regression?
Yes, we can use principle components to set up regression. PCA performs effectively when the first few principal components are sufficient to capture the majority of the variation in the predictors and the relationship with the response. The only disadvantage of this approach is that when using a PCA, the new reduced set of features would be modeled while ignoring the response variable Y. While these features may do a good overall job of explaining variation in X, the model will perform poorly if these variables do not explain variation in Y.
11. Can PCA be used on Large Datasets?
The PCA object is quite useful. However, it has several limits when dealing with huge datasets. The most significant drawback is that PCA only permits batch processing, which implies that all data must fit in the main memory.
IncrementalPCA is a better option for large datasets since it uses a different type of processing and allows for partial calculations that almost identically match the findings of PCA while processing the data in a minibatch method.
12. How is PCA used to detect anomalies?
Principal component analysis (PCA) is a statistical approach that divides a data matrix into vectors known as principal components. The main components can be utilized for a variety of purposes. PCA components’ application checks a set of data items for anomalies using reconstruction error. In a nutshell, the concept deconstructs the source data matrix into its major components and then rebuild the original data using only the first few principal components. The rebuilt data will be comparable but not identical to the original data. Anomaly items are reconstructed data items that deviate the most from their matching original items.
Conclusion
We checked some important Interview questions based on Principal component analysis (PCA). These will help you in clearing interviews of Machine Learning and Data Science. To sum up:
- We know that huge datasets are more frequent, and it is often challenging to comprehend them. Principal Component Analysis decreases the dimensionality of such datasets while increasing interpretability and minimizing information loss. It incrementally maximizes variance by introducing new uncorrelated variables.
- PCA is primarily used to reduce dimensionality in many AI applications such as computer vision, image compression, etc.
- If the data has a high dimension, it can also be used to uncover hidden patterns. Finance, data mining, psychology, and other fields employ PCA.
PCA often seeks the lower-dimensional surface onto which to project the high-dimensional data. This is why PCA is beneficial and practical.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Prateek is a final year engineering student from Institute of Engineering and Management, Kolkata. He likes to code, study about analytics and Data Science and watch Science Fiction movies. His favourite Sci-Fi franchise is Star Wars. He is also an active Kaggler and part of many student communities in College.







