Understanding Word Embeddings and Building your First RNN Model
This article was published as a part of the Data Science Blogathon.
Introduction
Deep learning is one of the hottest fields in the past decade, with applications in industry and research. However, even though it’s easy to delve into the topic, many people are confused by the terminology and end up only implementing neural network models that do not match their expectations. In this article, I will go over what recurrent neural networks (RNNs) and word embeddings are and a step-by-step guide to building your first RNN model for text classification tasks and challenges.

RNNs are one of the most important concepts in machine learning. They’re used across a wide range of problems, including text classification, language detection, translation tasks, author identification, and question answering, to name a few.
Let’s deep dive into RNNs and a step-by-step guide to building your first RNN model for text data.
Table of contents
Deep Learning for Text Data
Deep learning for natural-language processing is pattern recognition applied to text, words, and paragraphs in much similar way that computer vision is pattern recognition applied to pixels. In a true sense, deep learning models map the statistical structure of text data which is sufficient to solve many simple textual tasks and problems. Deep-learning models don’t take input as text like other models they only work with numeric tensors.
Three techniques are used to vectorize the text data:
- Segment text into words and convert word into a vector
- Segment text into characters and transform each character into a vector
- Extract n-grams of words, and transform each n-gram into a vector.
If you want to build a text model, the first thing you need to do is convert the text into a vector. There are many ways one can convert text to vector depending on what models one uses along with time or resource utilization.
Keras has a built-in method for converting text into vectors(Word embedding layer) which we will use in this article.
Here is a visual depiction of the deep neural network model for NLP tasks
source: https://www.dulnvxiers.gq/products.aspx?cname=glove+nlp&cid=41
Understanding Word-embeddings
A word embedding is a learned representation for text where words that have the same meaning and save similar representation
Courtesy: Machinelearningmastery.com
- This approach to representing words and documents may be considered one of the key breakthroughs of deep learning on challenging NLP problems
- Word embeddings are alternative to one-hot encoding along with dimensionality reduction.
One-hot word vectors — Sparse, High-dimensional and Hard-coded
Word embeddings — Dense, Lower-Dimensional and Learned from the data
- Keras library has embeddings layer which does word representation of given text corpus
tf.keras.layers.Embedding( input_dim, output_dim, embeddings_initializer=’uniform’, embeddings_regularizer=None, activity_regularizer=None, embeddings_constraint=None, mask_zero=False, input_length=None, **kwargs)
Key Arguments:
- input_dim — the size of vocabulary or length of the word index
- output_dim — Output dimension of word representation
- input_length — max input sequence length of the document
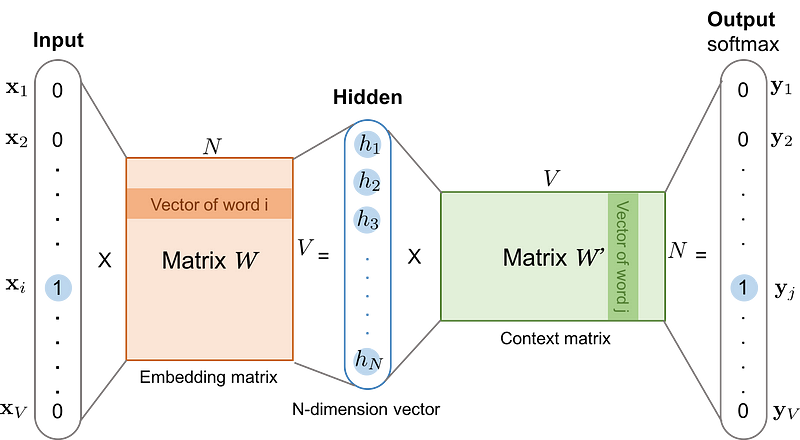
Here is the visual depiction of word embedding or also known as word2vec representation
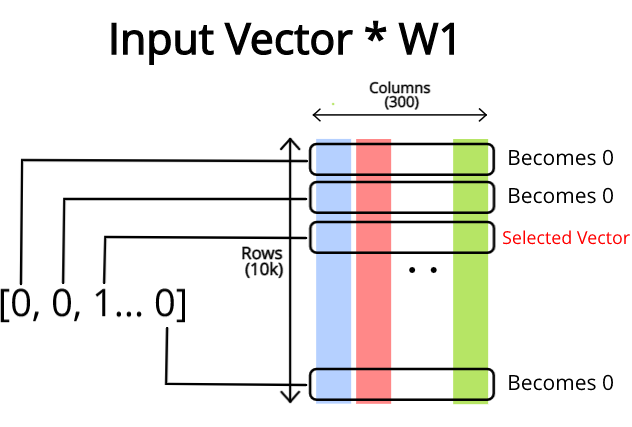
source: medium.com/deepleaningdemystified
Recurrent Neural Network (RNN): Demystified
- A major difference between densely connected neural networks and recurrent neural network is that fully connected networks have no memory in units of each layer. At the same time, recurrent neural networks store the state of the previous timestep or sequence while assigning weights to the current input.
- In RNNs, we process inputs word by word or eye saccade but eye saccade – while keeping memories of what came before in each cell. This gives a fluid representation of sequences and allows the neural networks to capture the context of the sequence rather than an absolute representation of words.
“Recurrent neural network processes sequences by iterating through the sequence elements and maintaining a
statecontaining information relative to what it has seen so far. In effect, an RNN is a type of neural network that has an internal loop.”
Courtesy: 6.2 Understanding recurrent neural networks, deep learning using python by Chollet
Below is the visual depiction of how recurrent neural networks learn the context of words about the target word

source: machineab.blogspot.com
Here is a simple depiction of RNN architecture with rolled and unrolled RNN.
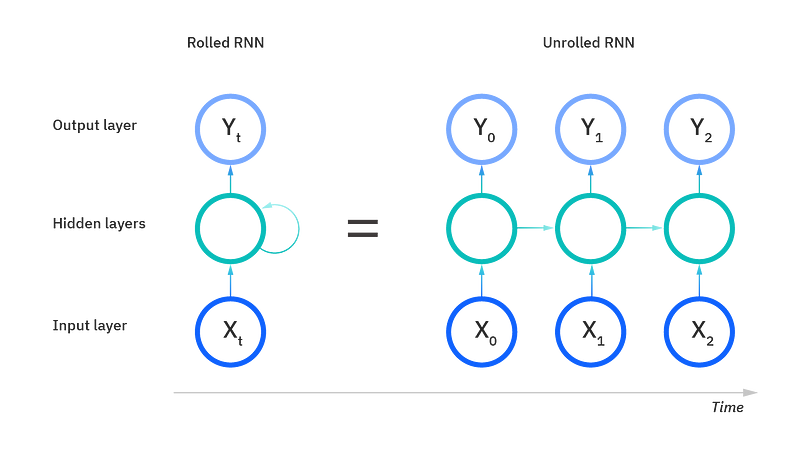
source: ibm.com
Building your First RNN Model for Text Classification Tasks
Now we will look at the step-by-step guide to building your first RNN model for the text classification task of the news descriptions classification project
So let’s get started:
Step 1: load the dataset using pandas ‘read_json()’ method as the dataset is in json file format
df = pd.read_json('../input/news-category-dataset/News_Category_Dataset_v2.json', lines=True)
Step 2: Pre-process the dataset to combine the ‘headline’ and ‘short_description’ of the dataset.
Python Code:
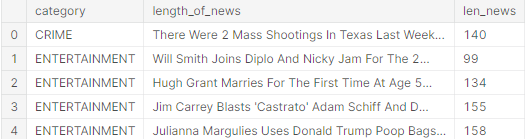
the output of the above code block
Step 3: Clean the text data to move forward with tokenization and vectorization of text inputs before we feed vectorized text data to the RNN model.
# clean the text data using regex and data cleaning function
def datacleaning(text):
whitespace = re.compile(r"s+")
user = re.compile(r"(?i)@[a-z0-9_]+")
text = whitespace.sub(' ', text)
text = user.sub('', text)
text = re.sub(r"[[^()]*]","", text)
text = re.sub("d+", "", text)
text = re.sub(r'[^ws]','',text)
text = re.sub(r"(?:@S*|#S*|http(?=.*://)S*)", "", text)
text = text.lower()
# removing stop-words
text = [word for word in text.split() if word not in list(STOPWORDS)]
# word lemmatization
sentence = []
for word in text:
lemmatizer = WordNetLemmatizer()
sentence.append(lemmatizer.lemmatize(word,'v'))
return ' '.join(sentence)Step 4: Tokenization and vectorization of text data to create a word index of the sentences and split the dataset into train and test datasets.
# one hot encoding using keras tokenizer and pad sequencing
X = final_df2['length_of_news']
encoder = LabelEncoder()
y = encoder.fit_transform(final_df2['category'])
print("shape of input data: ", X.shape)
print("shape of target variable: ", y.shape)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)
tokenizer = Tokenizer(num_words=100000, oov_token='')
tokenizer.fit_on_texts(X_train) # build the word index
# padding X_train text input data
train_seq = tokenizer.texts_to_sequences(X_train) # converts strinfs into integer lists
train_padseq = pad_sequences(train_seq, maxlen=20) # pads the integer lists to 2D integer tensor
# padding X_test text input data
test_seq = tokenizer.texts_to_sequences(X_test)
test_padseq = pad_sequences(test_seq, maxlen=20)
word_index = tokenizer.word_index
max_words = 150000 # total number of words to consider in embedding layer
total_words = len(word_index)
maxlen = 130 # max length of sequence
y_train = to_categorical(y_train, num_classes=41)
y_test = to_categorical(y_test, num_classes=41)
print("Length of word index:", total_words)----------------------------[output]--------------------------------
shape of input data: (184853,) shape of target variable: (184853,) Length of word index: 174991
Step 5: Now as we have ‘train’ and ‘test’ data prepared, we can build an RNN model using the ‘Embedding()’ and ‘SimpleRNN()’ layers of Kera’s library.
# basline model using embedding layers and simpleRNN
model = Sequential()
model.add(Embedding(total_words, 70, input_length=maxlen))
model.add(Bidirectional(SimpleRNN(64, dropout=0.1, recurrent_dropout=0.20, activation='tanh', return_sequences=True)))
model.add(Bidirectional(SimpleRNN(64, dropout=0.1, recurrent_dropout=0.30, activation='tanh', return_sequences=True)))
model.add(SimpleRNN(32, activation='tanh'))
model.add(Dropout(0.2))
model.add(Dense(41, activation='softmax'))
model.summary()----------------------------[output]--------------------------------
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding (Embedding) (None, 130, 70) 12249370 _________________________________________________________________ bidirectional (Bidirectional (None, 130, 128) 17280 _________________________________________________________________ bidirectional_1 (Bidirection (None, 130, 128) 24704 _________________________________________________________________ simple_rnn_2 (SimpleRNN) (None, 32) 5152 _________________________________________________________________ dropout (Dropout) (None, 32) 0 _________________________________________________________________ dense (Dense) (None, 41) 1353 ================================================================= Total params: 12,297,859 Trainable params: 12,297,859 Non-trainable params: 0 _________________________________________________________________
Step 6: Compile the model with the ‘rmsprop’ optimizer and ‘accuracy’ as validation metrics followed by fitting the model to the ‘X_train’ and ‘y_train’ data. you can evaluate the model using the ‘model.evaluate()’ method on test data. Congrats! you have just built your first model using word embedding and RNN layers.
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy']
)
# SETUP A EARLY STOPPING CALL and model check point API
earlystopping = keras.callbacks.EarlyStopping(monitor='accuracy',
patience=5,
verbose=1,
mode='min'
)
checkpointer = ModelCheckpoint(filepath='bestvalue',moniter='val_loss', verbose=0, save_best_only=True)
callback_list = [checkpointer, earlystopping]# fit model to the data
history = model.fit(train_padseq, y_train,
batch_size=128,
epochs=15,
validation_split=0.2
)
# evalute the model
test_loss, test_acc = model.evaluate(test_padseq, y_test, verbose=0)
print("test loss and accuracy:", test_loss, test_acc)Conclusion
With the advent of Deep Learning methods and techniques, NLP-related tasks have been approached using RNN and 1-D CNN (for extending the concept of classification based on character sequences to sequences of words). This article will briefly describe the basic idea of RNN (recurrent neural network), Wordembeddings, and their implementation in python. The code of this model can be easily used to build other complex networks.
Key takeaways:
- Word embeddings are representations of word tokens that eventually can be trained along with a model to find optimal weights that fit the task at hand.
- Recurrent neural networks are widely used in text data classification tasks and can be implemented using the Keras library of python.
- Using a step-by-step guide for building an RNN model to classify text data at hand, you build the model for any text classification problem.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.








Really informative article.
Great job in introducing Recurrent neural networks. Keep on moving.
Well Explained Article for RNN Model Thanks For sharing with fresher like me who wanted to be a Part of Data Science 🙏
Very informative blog, Have got an exceptionally great practical introduction about RNN
This is a very informative article with tutorials that promote intense learning development for one, and I am grateful that @Avikumart_ introduced me to it.
Very informative work
Really informative 👍👍