Non-Generalization and Generalization of Machine learning Models
This article was published as a part of the Data Science Blogathon.
Introduction
The generalization of machine learning models is the ability of a model to classify or forecast new data. When we train a model on a dataset, and the model is provided with new data absent from the trained set, it may perform well. Such a model is generalizable. It doesn’t have to act on all data types but with similar domains or datasets.
.png) Generalized learning
Generalized learningTwo models may have learned separately from two problem areas and independently while employing the same variable and constraint behavior.
Initially, generalization results from lapses in the model building or mere coincidence. It is considered an advantage in today’s models and should be maximized and controlled. A generalized model can save production costs by retraining a new model from scratch. If a model can carry out the prediction, it was developed to do it efficiently; being able to predict another problem is a benefit anyone would want. Making a model generalizable should be something every engineer and researcher considers.
What are Unseen Data?
It is important to have an understanding of what unseen data is. Unseen data is data new to the model that was not part of the training. Models perform better on observations they have seen before. For more benefit, we should try to have models that will be able to perform even on unseen data.
Benefits of Generalization
Sometimes generalization can be a process to improve performance. In deep learning, models can analyze and understand patterns present in datasets. They are also liable to overfitting. Using generalization techniques, this overfitting can be managed so that the model is not too strict. It can assist in deep learning to predict a pattern that has not been seen before. Generalization represents how a model can make proper predictions on new data after being trained on the training set.
Deep learning clearly shows the benefit of using Generalization. It becomes an intricate ability because we do not want to train models to cram images so that when we bring an image that is not in the cramped memory, it flops. We want trained models to do well if we bring an image that is outside the common set.
An accuracy of 100% may mean all images were crammed well. Bring a picture outside, and the model fails. A good model would be able to deal with pictures more generally. Generalization techniques should ensure that are no overfitting in the training of deep learning models.
Various approaches can be categorized under data-centric and model-centric generalization techniques. They ensure the model is trained to generalize the validation dataset and find patterns from the training data.
Elements for Generalization of Models
Since generalization is more of an advantage, it is necessary to see some of the factors that can influence it in the design cycle of models.
Nature of the Algorithm/Model centric approach
All models have different behaviors. How they treat data and how they optimize their performance is different. Decision Trees are non-parametric, making them prone to overfitting. To address generalization in models, the nature of the algorithm should be considered intentionally. Sometimes how models perform comes with high complexity. When they are complex, overfitting becomes easy. A balance can be created using model regularization to achieve generalization and avoid overfitting. For deep networks, changing network structure by reducing the number of weights or network parameters i.e, the values of weights, could do the trick.
The Nature of Dataset
The other side is the dataset being used for training. Sometimes datasets are too unified. They hold little difference from each other. The dataset of bicycles may be so unified that it cant be used to detect motorcycles. In order to achieve a generalized machine learning model, the dataset should contain diversity. Different possible samples should be added to provide a high range. This helps models to be trained with the generalization best achieved. During training, we can use cross-validation techniques e.g, K-fold. This is needful to see the sense of our model even while targeting generalization.
Non-Generalization of Models
It is seen that models do not require generalization. Models should just do what they are strictly expected to do. This may or may not be the best. I may want my model trained on images of motorcycles to be able to identify all similar vehicles, including bicycles and even wheelchairs. This may be very robust. In another application, this may not be good. We may want our model trained with motorcycles to strictly identify motorcycles. It should not identify bicycles. Maybe we want to count motorcycles in the parking lot without bicycles.
Using the above factors that affect generalization, we can decide and have control over when we want or don’t need generalization. Though generalization can contain risks. As such if the means are available, non-generalization should be highly optimized. If the means are available, a new model should be developed for bicycles and another for wheelchairs. In cases when there are fewer resources like time and dataset, the generalization technique can then be utilized.
Non-Generalization/Generalization and Overfitting of Models
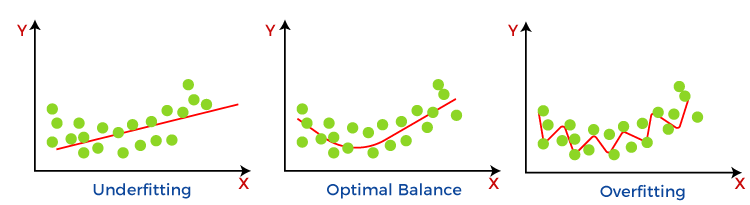
Non-Generalization is most closely related to overfitting conditions. When a model is non-generalizable it could associate with overfitting. If overfitting is settled, generalization becomes more achievable. We do not want an overfitted model. A model that has learned the training dataset and knows nothing else. It performs on the training dataset but does not perform well on new inputs. Another case is an Underfit Model. This will be a model that does not understand the problem and acts poorly on a training dataset and does not perform on new inputs. We don’t want this too. Another scenario is the Good Fit Model. This is like a normal graph in machine learning. The model appropriately learns the training dataset and generalizes it to new inputs.
A good fit is what we need to target when we want a model that can be generalized.
Effect of Bias and Variance on Generalization
Other factors that have an effect Generalization of models are variance and bias. A model will analyze data, find patterns in the data and make predictions. During the training process, it learns the patterns in the dataset and uses them during testing to make predictions which are measured for accuracy. In the prediction process, a contrast between the predicted values and actual values is Errors due to bias. A high-bias model can not perform generalization.
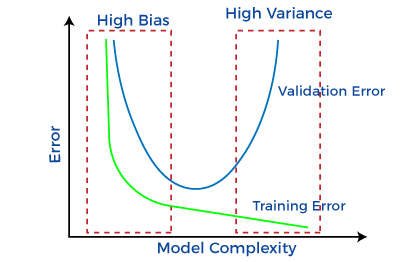
Variance tells how much a variable is different from its expected value. We make a random variable and compare it with what we expect from it. It is expected for models not to vary too much comparatively. The model should be able to understand the hidden mapping between inputs and output. A low variance shows a little deviation in the prediction, while a high variance shows a large deviation in the prediction of the target function.
A model showing a high variance does not generalize with an unseen dataset. This means in developing models that can generalize well, the variance level has to be treated to be low.
Conclusion
We have gained insight into the concept of generalization, which describes a model’s response to fresh, never-before-seen data derived from the same distribution as the model’s initial data set. We saw the opposite, which is non-generalization. The dataset and the algorithm are factors that affect the ability of generalization. We developed a sense of overfitting and how it relates to the topic of discus. Simply said, variance is the model prediction’s ability to vary, or how much the ML function may change based on the input data set. Models with many features and a high level of complexity are the source of variation. High-bias models will have minimal variance. And lastly, models with a low bias will have a high variance which will not generalize.
key Takeaways;
- Generalization of machine learning models is defined as the ability of a model to classify or forecast new data.
- Initially, generalization comes as a result of lapses in the model building or mere coincidence. In today’s models, it is considered an advantage and should be maximized and controlled.
- Unseen data is data new to the model that was not part of the training. Models perform better on observations they have seen before. For more benefit, we should try to have models that can perform even on unseen data.
- Using generalization techniques, such as regularization, overfitting can be managed so that the model is not too strict.
- The nature of the algorithm/Model centric approach and The nature of the dataset are two factors for generalization.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.








