Three R Libraries for Automated EDA
Introduction
With the increasing use of technology, data accumulation is faster than ever due to connected smart devices. These devices continuously collect and transmit data that can be processed, transformed, and stored for later use. This collected data, known as big data, holds valuable insights which can be harnessed across different industries to solve real-world problems. However, this data can be structured or semi-structured but, sometimes, is highly unstructured in its original format. Raw data processing is often challenging, prone to manual errors, time-consuming, and expensive due to high-end resources. Hence, companies look for automated solutions which can process large amounts of data in significantly less time.
This article was published as a part of the Data Science Blogathon.
Table of contents
What is Exploratory Data Analysis?
The most crucial step in data processing is data exploration using Exploratory Data Analysis (EDA). Different steps are performed to prepare and format the raw data depending on the end goal (regression or classification). This process involves evaluating the available data in all possible directions to identify the correlations between different features and the target. It also involves identifying and handling any inconsistencies in the data, like redundancies, missing values, or outliers. Most organizations employ Python and R programming to process their acquired data. Thus, several open-source packages have been developed to automate the EDA process in these two programming languages. These libraries are helpful for data scientists to perform EDA faster and spend more time on model development tasks. R beginners can also use these libraries as they are easy to use and can help them quickly understand the dataset with a few code lines.
This article will discuss three AutoEDA R libraries with their respective code to perform EDA. These R packages accomplish several EDA tasks for efficiently summarizing data into tables and preparing detailed HTML reports to speed up the process of exploration of a new dataset.
AutoEDA Packages in R
Now, let us explore all three Automated Exploratory Data Analysis packages. We will use the Motor Trend Car Road Tests dataset ‘mtcars’ from the available built-in R datasets. To load and view this dataset, we will use –
#load dataset
df = mtcars
head(df)dataMaid
The dataMaid package creates a report in different formats, such as PDF, DOCX, or HTML. The generated report checks and neatly simply summarizes the dataset. It is a good tool for checking errors in the dataset.
We will install, import, and run the dataMaid package using the following command:
# Install package
install.packages("dataMaid")
# Import library
library(dataMaid)
# Create report
makeDataReport(df, output = "html", replace = TRUE)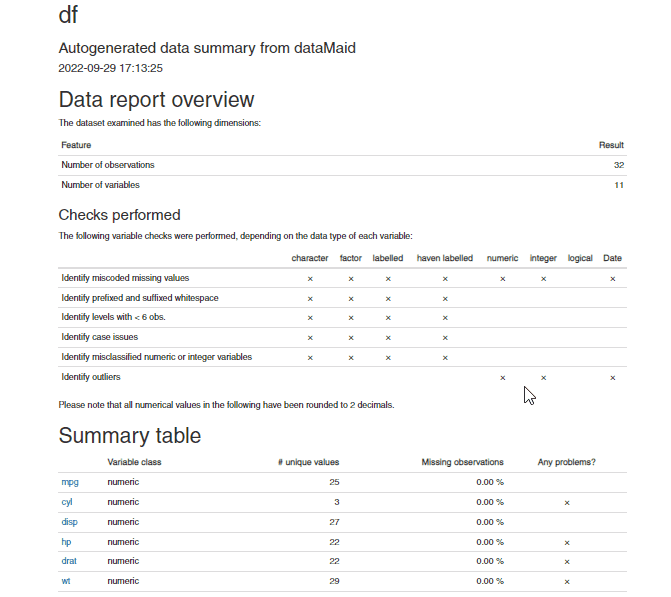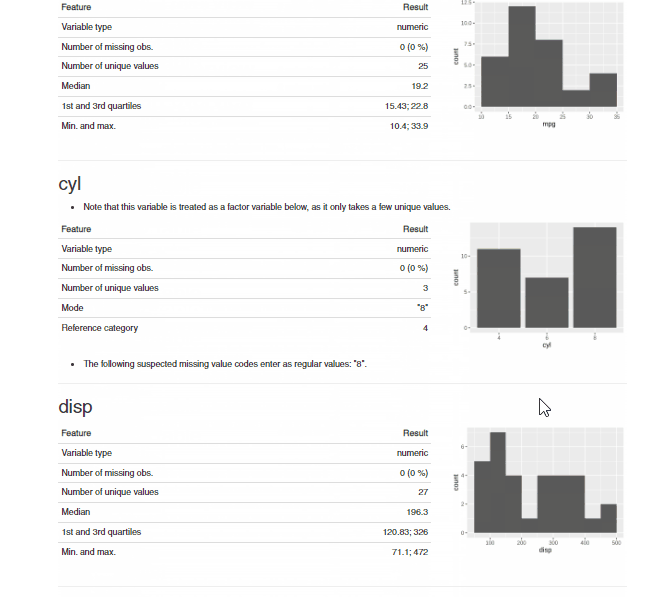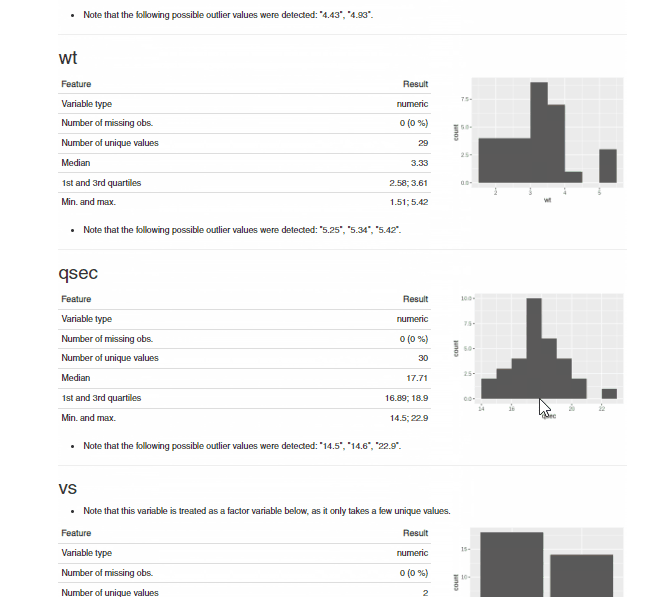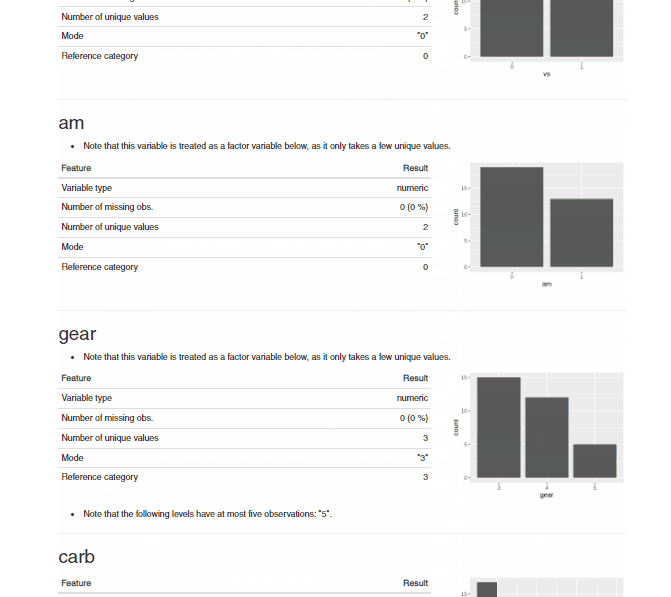
From the above .gif for the .html report generated by the dataMaid package, we can see that all the discrepancies in the dataset are summarized variable by variable in the generated report. Thus, it is easier to understand the data quality and decide on the next steps required for data cleaning.
The dataMaid package documentation can be explored for additional details.
DataExplorer
This is one of the most commonly used AutoEDA packages in R. With DataExplorer, we can simplify the EDA process and report generation. This library automatically scans the dataset for variables, performs data profiling, and provides many useful functions to create various charts on both discrete and continuous features in the dataset.
Let us look at the code we need to install and use the DataExplorer library:
# Installing the package
install.packages("DataExplorer")
# Importing the library
library(DataExplorer)
create_report(mtcars)
data()The DataExplorer library generates a complete HTML report in the working directory for the EDA on the dataset using the create_report function. This function also accepts additional arguments to customize the EDA report. The report HTML file, when opened with a browser, looks like the following –
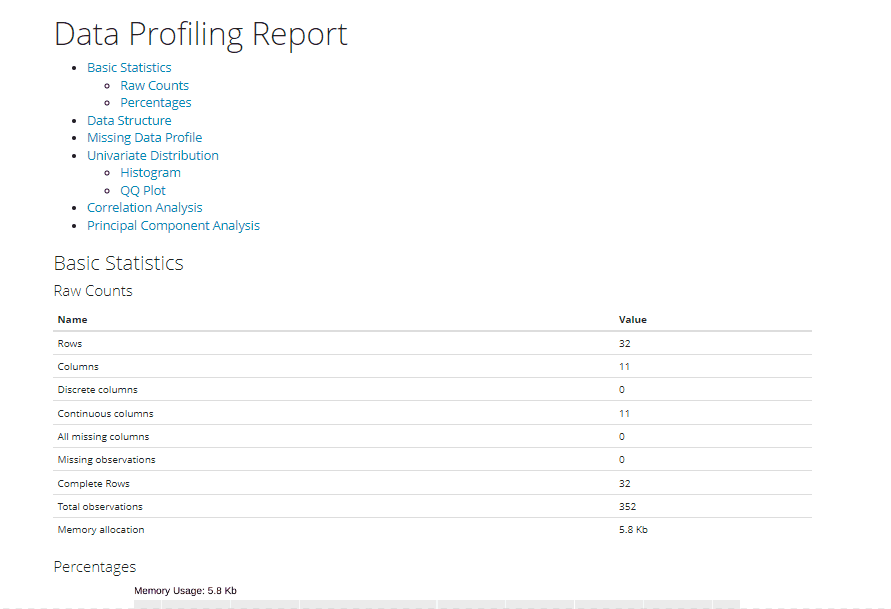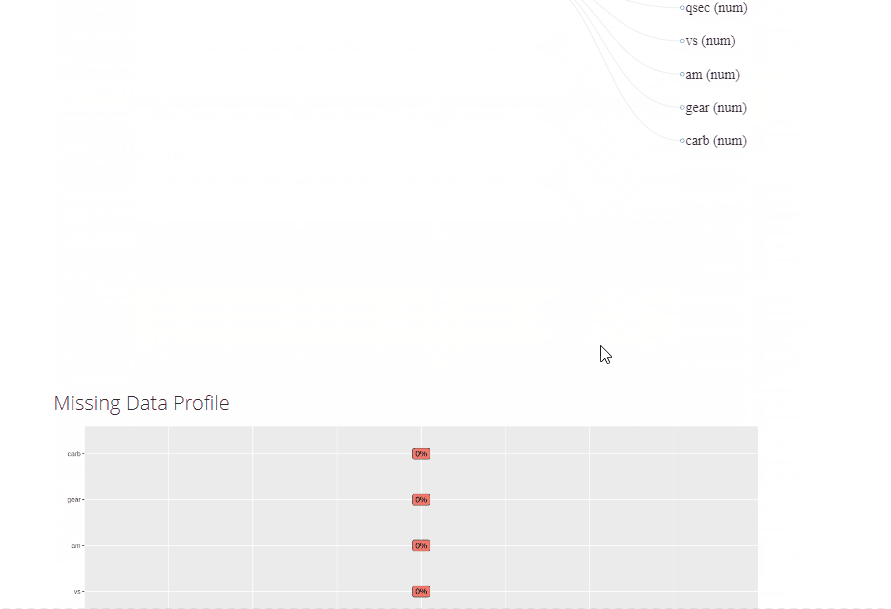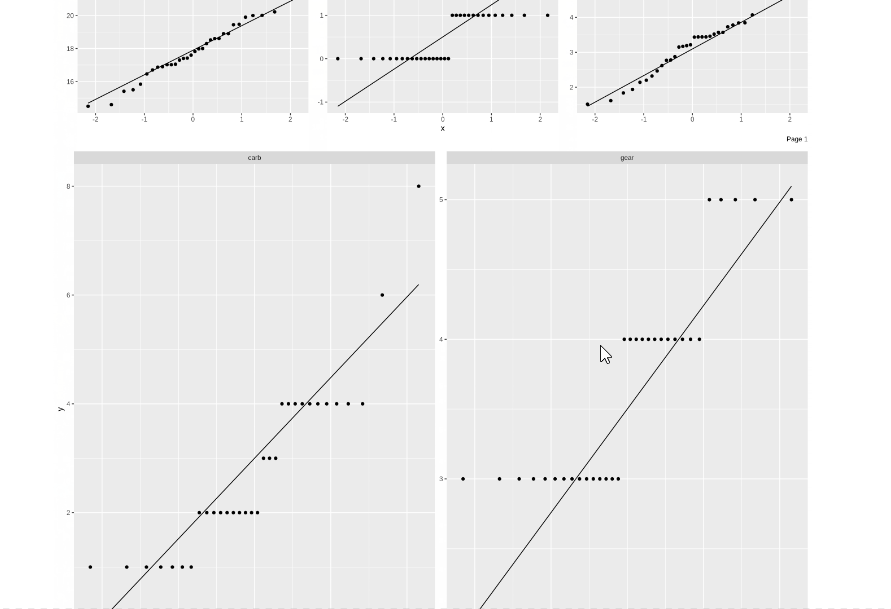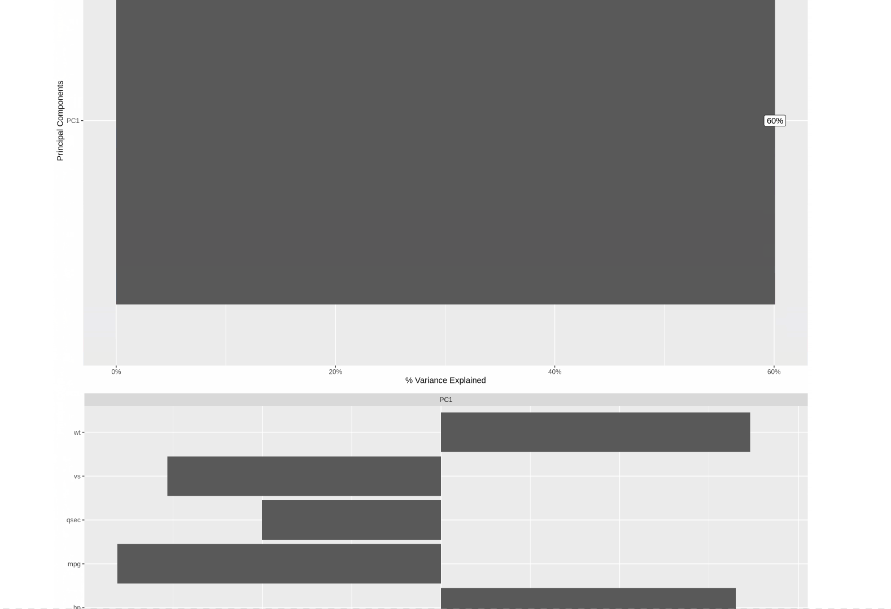
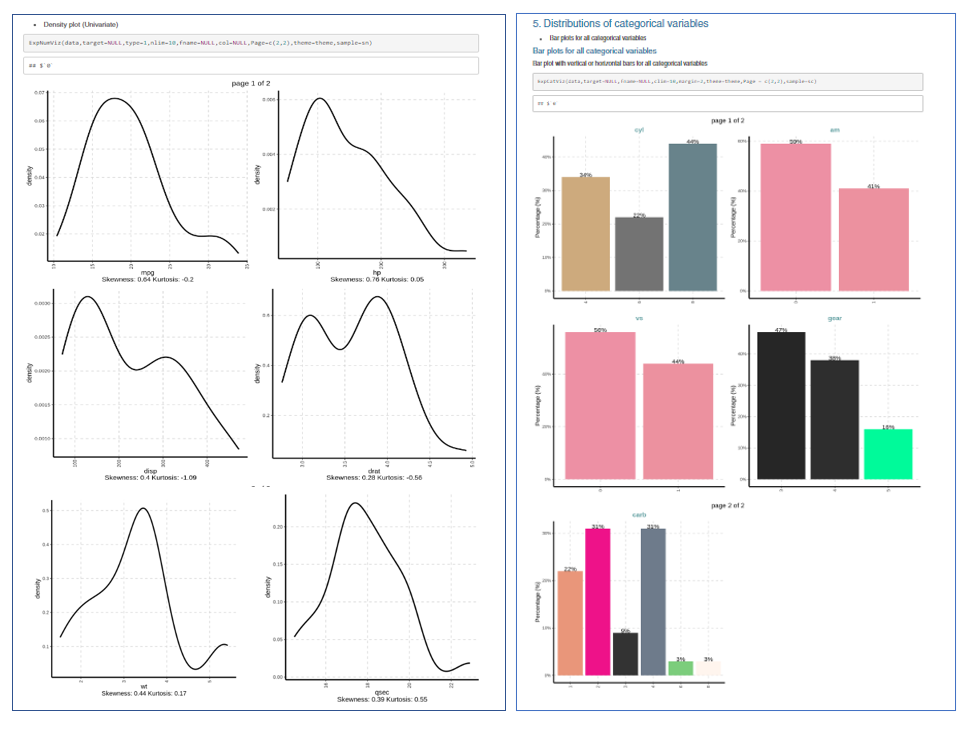
From the above .gif image of the report, we can see that the table of contents indicates a comprehensive report covering most of the tasks performed during EDA generated with just one line of code. Here are some sample plots from the report at a glance-
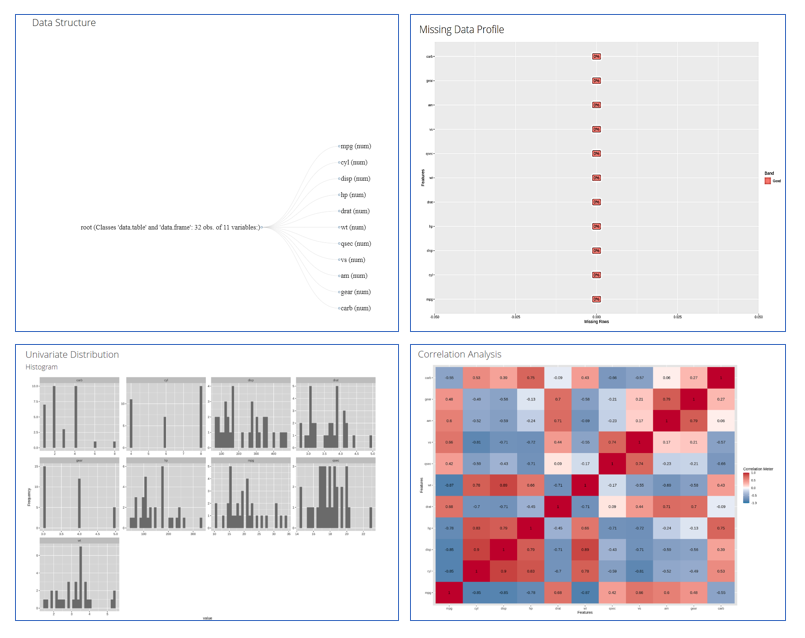
You can also refer to the package documentation on the CRAN-R website for additional details
SmartEDA
The next AutoEDA library is SmartEDA which is a powerful package for automating most EDA tasks through functions for Descriptive statistics, Data visualization, Custom tables, and HTML reports.
Similar to the previous DataExplorer package, the SmartEDA library also allows us to generate a complete HTML report using the ExpReport function. Let us install and import the package as well as run the ExpReport function to perform the EDA, as shown below.
# Install package
install.packages("SmartEDA")
# Import library
library(SmartEDA)
ExpReport(df,op_file='smartEDA.html')This ExpReport function accepts several arguments to customize the report for Template, op_file,op_dir, label, theme, etc.
Here, we will use the ‘op_file’ function to name the report.html file. This report file is available with the specified name in the working directory and can be opened with a browser. The snippet of the .html report shown below provides information on how well the SmartEDA package has summarized the ‘mtcars’ dataset.
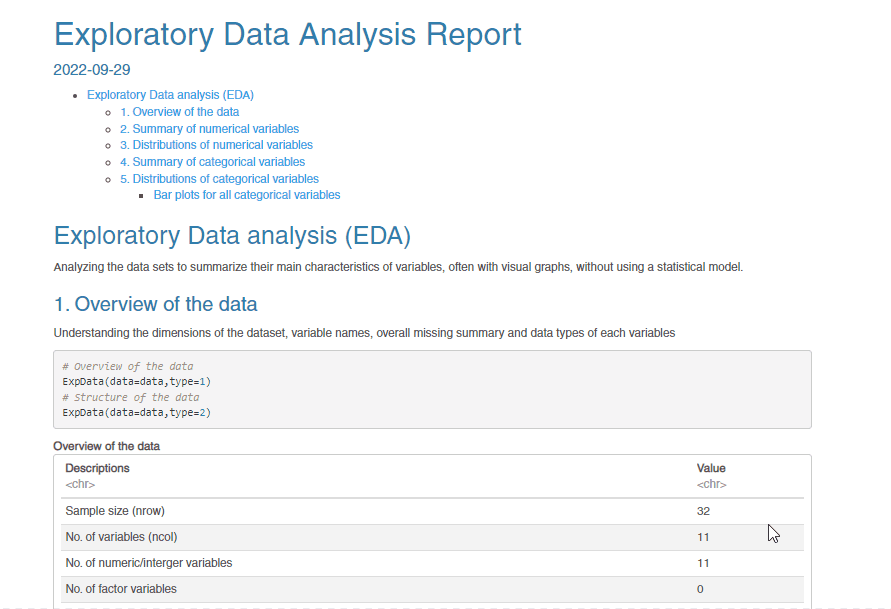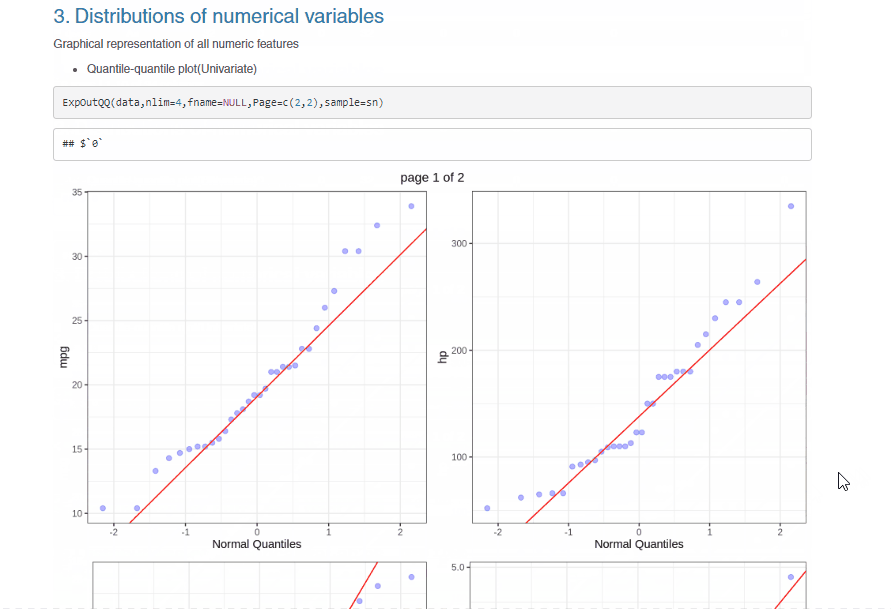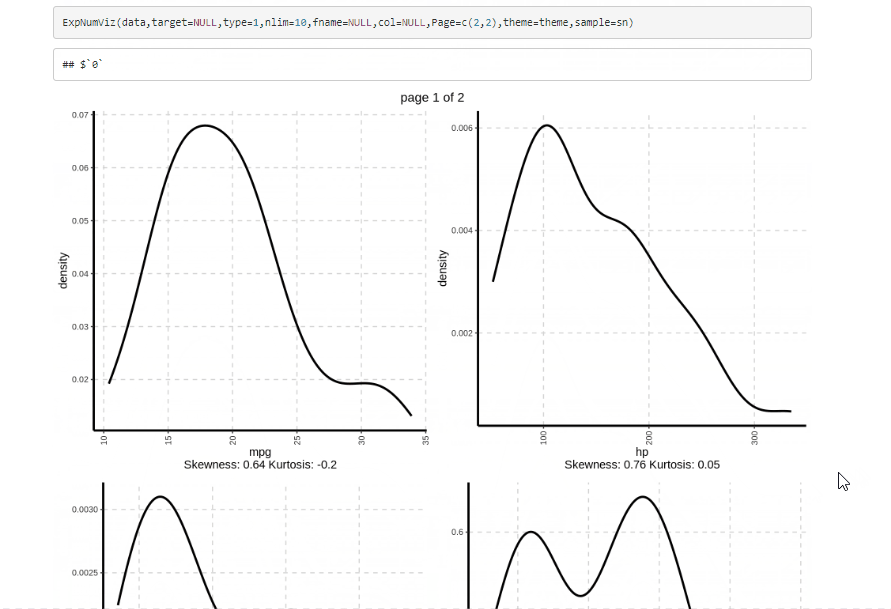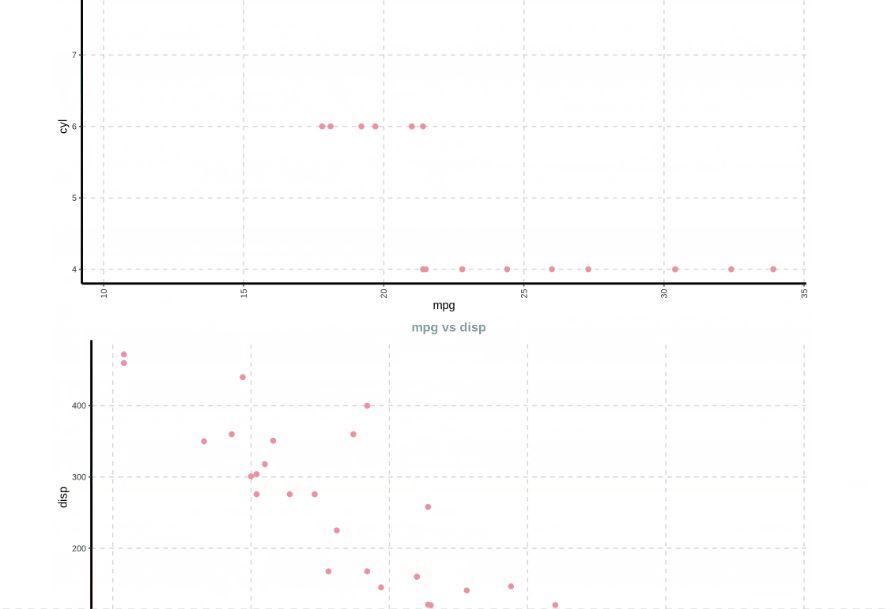
Here are a few sample plots from the report –
From the .html report, we can see that it contains several plots generated with just one line of code and these plots are useful in understanding the dataset better. The documentation for SmartEDA can be found here.
Conclusion
In this article, we explored three different AutoEDA R packages. Overall, these R packages are similar in that they provide a big picture and help to improve the general understanding of the dataset. Note that the summary in these reports may also be done manually. Depending on different purposes, you can choose the appropriate package to apply. E.g., the DataMaid package is good at identifying errors in the data. In contrast, the DataExplorer library gives detailed information on the dataset through plots on feature importance, correlation matrix, missing data plots, etc. On the other hand, the SmartEDA package is an excellent tool for understanding the dataset’s multivariate relationships.
Here are some key takeaways from the article –
- Manual data processing of big data requires a lot of time, money, and effort.
- Companies prefer automating data processing tasks for faster model building and deployment.
- Automated EDA helps expedite the data analysis; hence, several open-source packages in Python and R are available to automate EDA.
- All three R packages- DataMaid, DataExplorer, and SmartEDA, are highly effective in performing EDA on a given dataset and can be considered for implementation by data scientists in an organization.
- As these libraries require a few lines of code for performing EDA, even R beginners can try out the libraries mentioned in this article to improve their skills.
I hope you liked the article. Try any of these AutoEDA packages to quickly uncover interesting insights with a few code lines for your next R project.
Frequently Asked Questions
A. Common packages for Exploratory Data Analysis (EDA) in R include dplyr, ggplot2, tidyr, and summarytools. These packages offer tools for data manipulation, visualization, and summary statistics.
A. EDA packages refer to libraries or sets of functions in programming languages like R that facilitate Exploratory Data Analysis. These packages provide tools for visualizing, summarizing, and understanding data patterns.
A. EDA in R programming stands for Exploratory Data Analysis. The data analysis approach involves summarizing and visualizing data to understand its key characteristics, uncover patterns, and identify anomalies.
A. Libraries commonly used for EDA in R include dplyr for data manipulation, ggplot2 for data visualization, tidyr for data tidying, and summarytools for generating summary statistics. These libraries collectively support comprehensive data exploration.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.







