Amazon S3: Everything You Need to Know
This article was published as a part of the Data Science Blogathon.

Source: https://www.stratospherix.com/
Introduction
Amazon Web Services (AWS) is a cloud computing platform offering a wide range of services coming under domains like networking, storage, computing, security, databases, machine learning, etc.
AWS has seven types of storage services which include Elastic Block Storage (EBS), Amazon FSx for Lustre, Elastic File System (EFS), Amazon S3 Glacier, Simple Storage Service (S3), Amazon FSx for Windows File Server, and AWS Storage Gateway
Amazon Simple Storage Service, commonly called Amazon S3, is the most popular and one of the first services introduced by AWS. It stores data of any type or size and supports all file formats. Amazon S3 helps in content distribution, performing analytics on data, backup, and recovery for cloud-based applications.
What is Amazon S3?
Amazon S3 is an efficient cloud storage service with high security, reliability, and scalability focusing on object-based storage.
S3 is a flexible, cost-effective data storage with REST and SOAP interfaces. It can be integrated with other AWS services like Amazon RDS, EC2, Cloud Front, etc. Amazon S3 has a web-based user interface that helps store and retrieve data from anywhere on the internet.
How Does Amazon S3 Work?
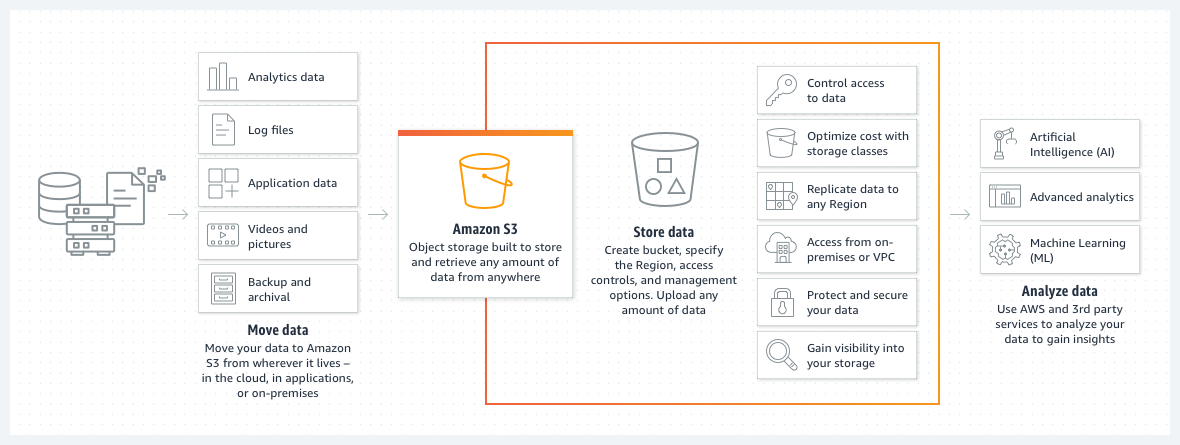
Source: https://aws.amazon.com/s3/
S3 has the following components :
- Buckets
- Objects
Buckets:
It is the top-level element of S3 and can be thought of as an object container, where the object denotes basic storage unit. In other words, the bucket is a logical container storing data in Amazon S3 buckets. They can be addressed in the following ways:
- Canonical form
http://s3.amazonaws.com/bucketname - Virtual hosting form
http://bucketname.com/ - Subdomain form
http://bucketname.s3.amazon.com
Buckets can be managed in the following ways:
- AWS SDK (Software Development Kit)
- Amazon S3 REST API
Features of Bucket:
- It does not support nesting, meaning a bucket can’t contain another.
- Users can choose the location of their choice for the creation of a bucket.
- Users can create policies and permissions which restrict access to buckets.
- Bucket creation is possible through PUT request to http://s3.amazonaws.com along with the bucket name.
- Bucket deletion is possible through a DELETE request.
- The bucket can be deleted only when it contains no objects, meaning it should be empty.
Objects:
It represents the basic data storage element in S3 buckets. The object has the following components:
- Key: It is the unique identifier that identifies each object in a bucket. Key denotes the name of the object. It is the string that indicates a hierarchy of directories. Using the key, it is possible to retrieve objects in the bucket
- Value: It is the actual content that needs to be stored. It is made up of a sequence of bytes.
- Metadata: It is the data about data that are being stored. It denotes a set of name-value pairs that stores data about an object.
- Version ID: It is the system-generated string that uniquely identifies a specific version of an object
- Access control list: It controls access to objects or files stored in S3 by granting permissions.
Amazon S3 Storage Classes
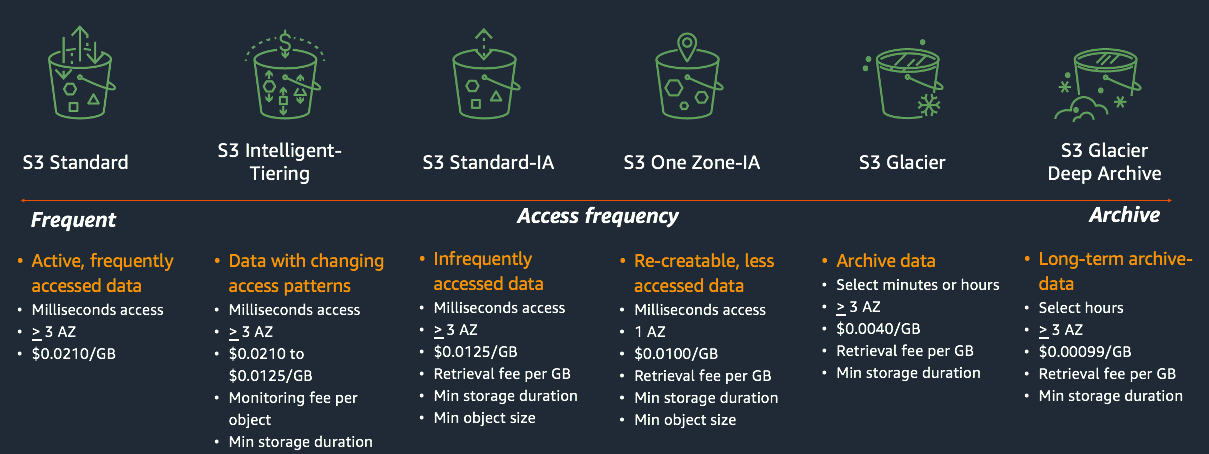
Source: https://catalog.us-east-1.prod.workshops.aws/
The different S3 storage classes are:
- S3 Standard
- S3 Standard-IA
- S3 Intelligent-Tiering
- S3 One Zone-IA
- S3 Glacier
- S3 Glacier Deep Archive
S3 Standard:
It is the default and the most expensive storage, class. It supports cloud migration processes to other classes, website hosting, and big data analytics. This is the best option when frequent data access is necessary.
S3 Standard-IA (Infrequent access):
It is good for backups, long-term storage, and disaster recovery-based use cases. It has a lower price for data and it is used when data is rarely accessed.
S3 Intelligent-Tiering:
It delivers automatic cost savings by moving data to the most cost-effective access tier, without having an impact on performance. In other words, it moves data between the Infrequent Access Tier and Frequent Access Tier.
S3 One Zone-Infrequent Access (S3 One Zone-IA):
It is good for data that is used infrequently but requires rapid access. It is helpful in secondary backup storage.
S3 Glacier:
This service stores data as archives where data access is infrequent. It provides low-cost and long-life archive storage. Also, it uses server-side encryptions to encrypt all data.
S3 Glacier Deep Archive:
It is the lowest-cost storage class and provides long-term data retention where data access is infrequent. Also, it has a minimum storage period of 90 days. It has 99.9% availability over a given year.
Why Amazon S3?
- Amazon S3 automatically creates multiple data replicas, so it is never lost.
- High security involves encryption features and access management tools that prevent unauthorized access.
- Able to store large files of a size limit of 5 TB.
- Less cost because of the pay-as-you-go model. Users have to pay depending on the amount of storage and time they use on S3.
- Easy to manage because the resources can be managed through GUI (Graphical User Interface), CLI (Command Line Interface), and API (Application Program Interface).
- S3 keeps multiple copies of a file to track changes over time, thus supporting versioning.
- Objects can be created on the location of the user’s choice.
- Highly durable hence data loss is much lesser. S3 provides object durability of “99.99999999999%”
Amazon S3 Use Cases
Some of the use cases of amazon S3 include:
Static Website Hosting:
Amazon S3 helps in hosting static websites. Hence users can use their domain. Serverless Web Applications can be developed using S3 and by using generated URLs, users can access the application.
Backup & Recovery:
Amazon S3 helps create backups and archive critical data by supporting Cross Region Replication. Due to versioning, which stores multiple versions of each file, it is easy to recover the files.
Low-cost data archiving:
It is possible to move data archives to certain levels of AWS S3 services like Glacier storage classes, which is one of the cheap and durable archiving solutions for compliance purposes; thus, data can be retained for a longer time
Security and Compliance:
Amazon S3 provides multiple levels of security, including Data Access Security, Identity and Access Management (IAM) policies, Access Control Lists (ACLs), etc. It supports compliance features for HIPAA/HITECH, Data Protection Directive, FedRAMP, and others.
Conclusion
Amazon S3 is an efficient object-based storage service used with REST and SOAP interfaces. Organizations can use this service for storing data relating to any business, such as web or mobile applications, analytics, backup, etc. Some companies using S3 are Siemens, Invista, Bristol Meyers Squibb, etc.
Key Takeaways:
- Amazon S3 (Simple Storage Service) is an online file storage service by AWS.
- S3 is fully scalable, efficient, fast, and reliable.
- Basic storage units of Amazon S3 are called objects organized into buckets.
- Different S3 storage classes comprise S3 Standard, S3 Standard-IA, S3 Intelligent-Tiering, S3 One Zone-IA, S3 Glacier, and S3 Glacier Deep Archive.
- The areas where S3 proved useful include static website hosting, backup & recovery, low-cost data archiving, security and compliance.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.







