Meta-Reinforcement Learning in Data Science
This article was published as a part of the Data Science Blogathon.
Introduction
Generally, machine learning can be classified into four types: supervised machine learning, unsupervised machine learning, semi-supervised machine learning, and reinforcement learning. Supervised machine learning is a type of machine learning that is the easiest and less complex type or branch of data science. The article will discuss reinforcement learning and meta-reinforcement learning in data science. This article will help one to understand the basic idea and core intuition behind meta-reinforcement learning and its working mechanism. We will start by revisiting the concept of reinforcement learning and quickly move to meta-reinforcement learning and its core intuition.
Reinforcement Learning
Reinforcement learning is a type of machine learning in which three main things are present: the agent, the environment, and the agent’s actions. Here, the agent is the machine learning model or the algorithm that has yet to be initially trained. The agent is put into the environment. Now the agent will perform actions and according to the actions acted and outcomes, the agent, is awarded some points.
Based on points awarded to the model or the agent, the agent learns to stay and act appropriately in the environment, and this is how the model’s training is done in reinforcement learning.
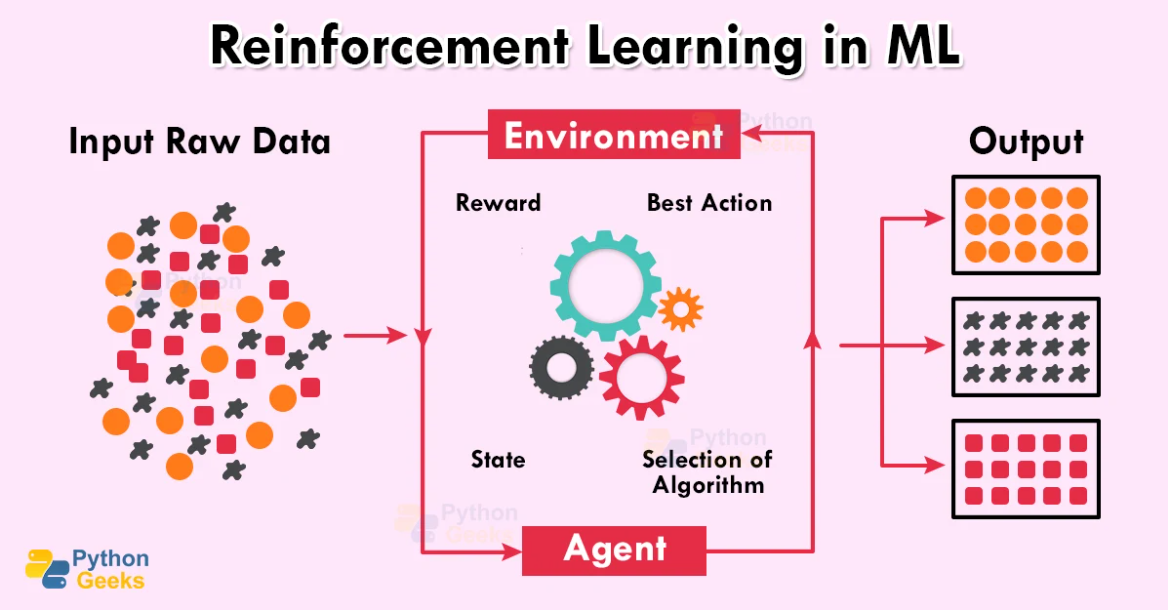
In the above image, we can see that some input data is being fed to the model. Once the data has been provided to the system, the agent will select the best appropriate model according to the environment, the model will train on the same algorithm and the input data and the basis of outcomes from the same, and some points will award the model. Now, the model can easily select the best-fit algorithm by tuning and looking at the points awarded.
Limited Data Scenario
The time complexity of the reinforcement learning models is high as they require lots of time to train the model. The RL model is the type of model that does lots of computations to introduce a successful model, which also requires higher computational powers. Good reinforcement learning models are trained on significant data sizes to achieve better accuracy and results from the model.
But in every case, it is possible to have lots of data and time to train the reinforcement learning model. In such cases, meta-reinforcement learning helps perform such tasks. The meta-reinforcement knowledge is used in this scenario to prepare the same model faster with limited data available.
Meta-Reinforcement Learning
Meta-reinforcement learning is a type of reinforcement learning used to train reinforcement learning models with limited data and time. This approach is mainly used to train the models where there is no vast data available related to the problem statement, and there is a need to prepare a model as fast as possible.
In this approach, the initial state of the structure of the model is used the most. Here the basic or the fewer stages of the model agent is used to train the agent, and later depending upon this knowledge of the agent, the future steps are performed automatically.
For Example, in the case of neural networks, the basic structure or the initial structure of the neural networks is studied. Now to train the model further, the knowledge gained from the initial steps and the resources available with the same task are used to train and prepare the further model with limited data.

In the above image, we can see that the agent acts according to the environment and is awarded by its actions. Here the agent observes the environment and tunes the parameters according to it. The main difference here is the agent takes care of the previous rewards and observations and uses that particular information to perform the next step.
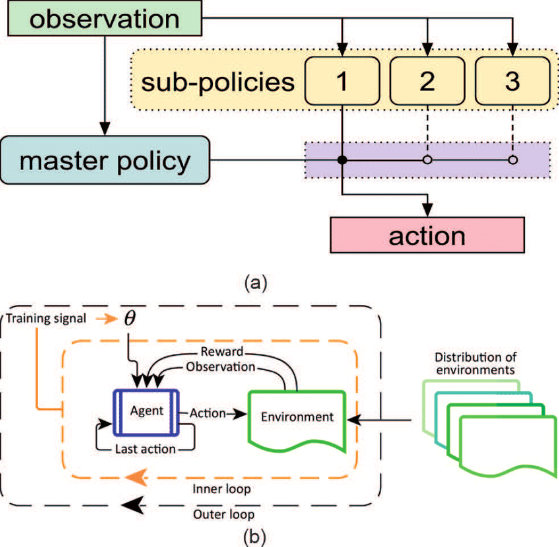
In the above Image, we can see an agent and the environment. The agent takes action in the background and is awarded according to its activities. This process takes place multiple times, and the agent takes care of the previous observations and rewards, and the policies are being made to act according to the environment in the next step. This will help the model to perform the task very efficiently with limited data and without taking much time for training.
Reinforcement vs. Meta-Reinforcement Learning
According to the reinforcement model’s structure, both techniques are the same, but there is a slight difference between them in the working mechanism of the model. In reinforcement learning, the model takes actions in the environment and is awarded by the outcomes to form particular activities. Here the data or the observations from the previous steps are not used to perform the following action.
In meta-reinforcement learning, the agent acts according to the environment and takes action. The agent observes the setting for the particular steps and is rewarded according to the outcomes. Noe, in the next step, the agent again acts in the environments, but here, the agent will also remember the observations and rewards from the previous step.
This is the main difference between these two which makes meta-reinforcement learning work faster and more efficiently. The knowledge gained from the previous steps is recorded and helps perform the following steps, which helps to train the model even with limited data.
Conclusion
In this article, we discussed the reinforcement and meta-reinforcement learning techniques with their basic idea, core intuition, and working mechanism. The knowledge about this technique will; help one to understand the concept of the RL algorithms better and allow one to answer the complex interview questions related to it very efficiently.
Some Key Takeaways from this article are:
1. Reinforcement learning is a branch of data science that deals with the agent, environment, and its actions and observations.
2. In regular Reinforcement algorithms, the data or the observations from the previous step are not used to perform the next task.
3. In meta-reinforcement learning, the previous step’s observations and rewards are recorded and included in the next epoch of the agent’s actions.
4. Meta-Reinforcement learning can be beneficial for performing tasks where only a limited amount of data is available, and the study needs to be completed quickly without taking more time.
Want to Contact the Author?
Follow Parth Shukla @AnalyticsVidhya, LinkedIn, Twitter, and Medium for more content.
Contact Parth Shukla @Parth Shukla | Portfolio or Parth Shukla | Email to contact me.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
UG (PE) @PDEU | 25+ Published Articles on Data Science | Data Science Intern & Freelancer | Amazon ML Summer School '22 | AI/ML/DL Enthusiast | Reach Out @portfolio.parthshukla.live










