Must-Read Top 8 Interview Questions on Apache Flume
Introduction
In this constantly growing technical era, big data is at its peak, with the need for a tool to collect and move this massive data effectively. Apache Flume is one tool that can collect, aggregate, and transfer massive volumes of data from one or more sources to a centralized data source efficiently and reliably.
The data sources are customizable in Apache Flume, that’s why it can ingest any data, including log data, network data, event data, social-media generated data, emails, message queues, etc.
Source: Quora
Moreover, Hadoop and Big Data developers use this tool to get log data from social media websites. Cloudera developed Flume gathers log files from multiple data sources and asynchronously persist in the Hadoop cluster.
In this blog, I discussed eight interview-winning questions that will help you to set a pace for Apache Flume and ace your upcoming interview!
Learning Objectives
Below is what we’ll learn after reading this blog thoroughly:
-
A common understanding of an Apache Flume and its role in the technical era.
-
Knowledge of reliability and failure handling in Apache Flume.
-
An understanding of the data flow process in Flume.
-
An understanding of features and use cases of Apache Flume.
-
Insights into concepts like channel Selectors, Consolidation, and Interceptors in Flume.
Overall, by reading this guide, we will gain a comprehensive understanding of Flume to move the data. We will be equipped with the knowledge and ability to use this technique effectively.
This article was published as a part of the Data Science Blogathon.
Table of Contents
- Explain the concept of data flow in Apache Flume.
- Explain the use cases of Apache Flume.
- Explain the concept of Reliability and Failure Handling in Apache Flume.
- What do you mean by Channel Selectors?
- Explain the concept of Consolidation in Flume.
- Define the usage of Interceptors in Flume.
- How can you use the HDFS “put” command for Data Transfer from Flume to HDFS?
- Explain the features of Flume.
- Conclusion.
Q1. Explain the Concept of Data Flow in Apache Flume.
In flume, we use log servers to generate the events and log data, and the Flume framework transfers that log data into HDFS. The Flume agents were constantly running on the log servers and receiving data from the data generators.

Source: data-flair.training
The role of Flume is like an intermediate node that collects the data in these agents, those nodes are what we call Collectors, and n-number of collectors are available in Flume just like agents. Finally, data will be aggregated and pushed to a centralized store like Hadoop, HBase, Hive, etc. just by using these collectors.
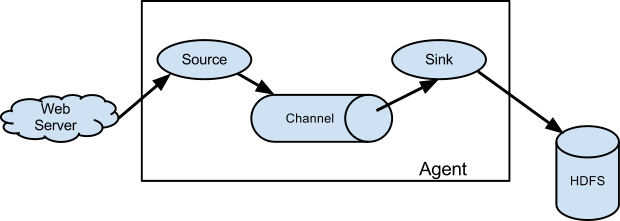
Source: flume.apache.org
Types of Data Flow in Flume:-
-
Multi-hop Flow: In the multi-hop Data flow, multiple agents can be present, and an event may travel through more than one agent before reaching the final destination within Flume.

Source: data-flair.training
-
Fan-out Flow: Fan-out data flow is the condition when the data transfers or flows from one source to multiple channels within Flume.

Source: data-flair.training
-
Fan-in Flow: In contrast with Fan-out flow, Fan-in flow is the transfer of data or data flow in which the data will be transferred from many sources to one channel.

Source: data-flair.training
Q2. Explain the Use Cases of Apache Flume.
Although several uses cases of Apache Flume are there in the market, and few of them are:
-
Apache Flume had a high usage in applications where we want to acquire data from various sources and store it in the Hadoop system.
-
Apache Flume plays a significant role in applications where we require to handle high-velocity and high-volume data in a Hadoop system.
-
Apache flume facilitates reliable data delivery to the desired destination or HDFS.
-
Apache Flume is proven a scalable solution when the velocity and volume of data increase by adding more machines.
-
Flume can configure the various components of the architecture without incurring any downtime.
Q3. Explain the Concept of Reliability and Failure Handling in Apache Flume.
To commit the transaction at the end of the sending agent, it is mandatory to receive the success indication from the receiving agent.
This process ensures the guaranteed delivery of semantics because the receiving agent only returns a success indication if its transaction commits successfully.
Q4. What do you mean by Channel Selectors?
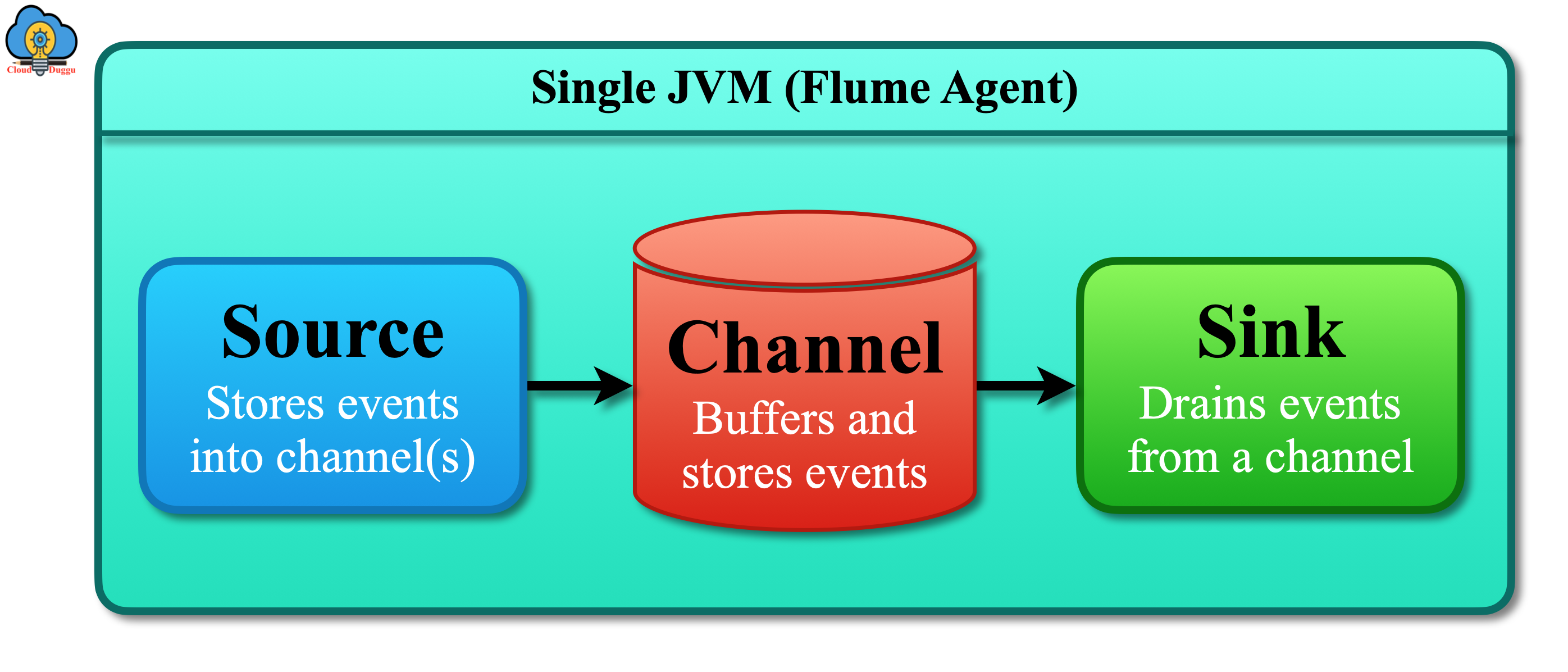
Source: www.cloudduggu.com
Basically, we have two different types of channel selectors:
-
Default channel selectors:− Default channel selector is the replicating selector which is capable of replicating all the events in each channel.
-
Multiplexing channel selectors:− Multiplexing channel selectors are the selectors that choose the channel to send an event based on the address in the event’s header.
Q5. Explain the Concept of Consolidation in Apache Flume.
Consolidation, often known as the beauty of Flume, collects data from multiple sources and flume agents. A flume source can collect the entire flow of data from multiple sources and flows through channels and sink. At last, transfer this data to the Hadoop or the target destinations.

Source: hadoopdpnotes
Q6. Define the Usage of Interceptors in Apache Flume.
Generally, the basic usage of interceptors is to either modify/change or drop events in flight. Flume can use interceptors to decide the type of data that should be allowed to pass through to the channel. Flume is also capable of binding interceptors, and the developer can choose the criteria based on which an interceptor can either modify or drop events.
The list of interceptors that you may be easily available includes Timestamp Interceptor, Host Interceptor, Static interceptor, and Regex filtering interceptor.
Q7. How can you use HDFS “put” Command for Data Transfer from Flume to HDFS?
The major challenge data enthusiast face in handling the log data is transferring the logs produced by multiple servers to the Hadoop environment. Hadoop Distributed File System(HDFS) offers several commands to read data from Hadoop and insert data into it. With the help of the HDFS put command, we can transfer the data from Apache Flume.
Syntax:-
$ Hadoop fs –put / /
In the above syntax, the source path means the path of the required file, and the destination path is the path in HDFS where to save the file.
Q8. Explain the Features of Flume.
Flume can be considered a very strong data tool due to its special features, which are-1. Apache Flume is a horizontally scalable tool that supports huge sources, channels, and sinks.
2. Apache Flume enables us to gather data from multiple web servers in real-time and batch mode. It also facilitates us with contextual routing.
3. Flume can handle the read-write rates; for example, if the read rate exceeds the write rate, Flume offers a steady flow of data between read and write operations.
4. The gathering of data carried by Flume data between sources and sinks. It can either be scheduled or event-driven. Now, Flume offers its query processing engine, which facilitates the easy transformation of each new batch of data before moving it to the intended sink.
Conclusion
This blog covers some of the frequently asked Apache Flume interview questions that could be asked in data science and big data developer interviews. Using these interview questions as a reference, you can better understand the concept of Apache Flume and start formulating effective answers for upcoming interviews. The key takeaways from this Flume blog are:-
-
Apache Flume is one of the strongest tools that can be used to collect and transfer massive volumes of data from multiple sources to a centralized data source.
-
It is highly useful in applications where we want to transfer data from various sources, and we’re more concerned with the scalability and reliability of data.
-
We have discussed the concept of consolidation, interceptors, and channel selectors.
-
At last, we end this blog by discussing some of the important features of Apache Flume.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.







