Introduction to Feature Selection methods with an example (or how to select the right variables?)
Introduction
One of the best ways I use to learn machine learning is by benchmarking myself against the best data scientists in competitions. It gives you a lot of insight into how you perform against the best on a level playing field.
Initially, I used to believe that machine learning is going to be all about algorithms – know which one to apply when and you will come on the top. When I got there, I realized that was not the case – the winners were using the same algorithms which a lot of other people were using.
Next, I thought surely these people would have better / superior machines. I discovered that is not the case. I saw competitions being won using a MacBook Air, which is not the best computational machine. Over time, I realized that there are 2 things which distinguish winners from others in most of the cases: Feature Creation and Feature Selection.
In other words, it boils down to creating variables which capture hidden business insights and then making the right choices about which variable to choose for your predictive models! Sadly or thankfully, both these skills require a ton of practice. There is also some art involved in creating new features – some people have a knack of finding trends where other people struggle.
In this article, I will focus on one of the 2 critical parts of getting your models right – feature selection. I will discuss in detail why feature selection plays such a vital role in creating an effective predictive model.
If you are interested in exploring the concepts of feature engineering, feature selection and dimentionality reduction, check out the following comprehensive courses –
Read on!
Table of Contents
- Importance of Feature Selection in Machine Learning
- Filter Methods
- Wrapper Methods
- Embedded Methods
- Difference between Filter and Wrapper methods
- Walkthrough example
1. Importance of Feature Selection in Machine Learning
Machine learning works on a simple rule – if you put garbage in, you will only get garbage to come out. By garbage here, I mean noise in data.
This becomes even more important when the number of features are very large. You need not use every feature at your disposal for creating an algorithm. You can assist your algorithm by feeding in only those features that are really important. I have myself witnessed feature subsets giving better results than complete set of feature for the same algorithm. Or as Rohan Rao puts it – “Sometimes, less is better!”
Not only in the competitions but this can be very useful in industrial applications as well. You not only reduce the training time and the evaluation time, you also have less things to worry about!
Top reasons to use feature selection are:
- It enables the machine learning algorithm to train faster.
- It reduces the complexity of a model and makes it easier to interpret.
- It improves the accuracy of a model if the right subset is chosen.
- It reduces overfitting.
Next, we’ll discuss various methodologies and techniques that you can use to subset your feature space and help your models perform better and efficiently. So, let’s get started.
2. Filter Methods

Filter methods are generally used as a preprocessing step. The selection of features is independent of any machine learning algorithms. Instead, features are selected on the basis of their scores in various statistical tests for their correlation with the outcome variable. The correlation is a subjective term here. For basic guidance, you can refer to the following table for defining correlation co-efficients.

- Pearson’s Correlation: It is used as a measure for quantifying linear dependence between two continuous variables X and Y. Its value varies from -1 to +1. Pearson’s correlation is given as:
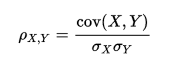
- LDA: Linear discriminant analysis is used to find a linear combination of features that characterizes or separates two or more classes (or levels) of a categorical variable.
- ANOVA: ANOVA stands for Analysis of variance. It is similar to LDA except for the fact that it is operated using one or more categorical independent features and one continuous dependent feature. It provides a statistical test of whether the means of several groups are equal or not.
- Chi-Square: It is a is a statistical test applied to the groups of categorical features to evaluate the likelihood of correlation or association between them using their frequency distribution.
One thing that should be kept in mind is that filter methods do not remove multicollinearity. So, you must deal with multicollinearity of features as well before training models for your data.
3. Wrapper Methods
In wrapper methods, we try to use a subset of features and train a model using them. Based on the inferences that we draw from the previous model, we decide to add or remove features from your subset. The problem is essentially reduced to a search problem. These methods are usually computationally very expensive.
Some common examples of wrapper methods are forward feature selection, backward feature elimination, recursive feature elimination, etc.
- Forward Selection: Forward selection is an iterative method in which we start with having no feature in the model. In each iteration, we keep adding the feature which best improves our model till an addition of a new variable does not improve the performance of the model.
- Backward Elimination: In backward elimination, we start with all the features and removes the least significant feature at each iteration which improves the performance of the model. We repeat this until no improvement is observed on removal of features.
- Recursive Feature elimination: It is a greedy optimization algorithm which aims to find the best performing feature subset. It repeatedly creates models and keeps aside the best or the worst performing feature at each iteration. It constructs the next model with the left features until all the features are exhausted. It then ranks the features based on the order of their elimination.
One of the best ways for implementing feature selection with wrapper methods is to use Boruta package that finds the importance of a feature by creating shadow features.
It works in the following steps:
- Firstly, it adds randomness to the given data set by creating shuffled copies of all features (which are called shadow features).
- Then, it trains a random forest classifier on the extended data set and applies a feature importance measure (the default is Mean Decrease Accuracy) to evaluate the importance of each feature where higher means more important.
- At every iteration, it checks whether a real feature has a higher importance than the best of its shadow features (i.e. whether the feature has a higher Z-score than the maximum Z-score of its shadow features) and constantly removes features which are deemed highly unimportant.
- Finally, the algorithm stops either when all features get confirmed or rejected or it reaches a specified limit of random forest runs.
For more information on the implementation of Boruta package, you can refer to this article :
For the implementation of Boruta in python, refer can refer to this article.
4. Embedded Methods
Embedded methods combine the qualities’ of filter and wrapper methods. It’s implemented by algorithms that have their own built-in feature selection methods.
Some of the most popular examples of these methods are LASSO and RIDGE regression which have inbuilt penalization functions to reduce overfitting.
- Lasso regression performs L1 regularization which adds penalty equivalent to absolute value of the magnitude of coefficients.
- Ridge regression performs L2 regularization which adds penalty equivalent to square of the magnitude of coefficients.
For more details and implementation of LASSO and RIDGE regression, you can refer to this article.
Other examples of embedded methods are Regularized trees, Memetic algorithm, Random multinomial logit.
5. Difference between Filter and Wrapper methods
The main differences between the filter and wrapper methods for feature selection are:
- Filter methods measure the relevance of features by their correlation with dependent variable while wrapper methods measure the usefulness of a subset of feature by actually training a model on it.
- Filter methods are much faster compared to wrapper methods as they do not involve training the models. On the other hand, wrapper methods are computationally very expensive as well.
- Filter methods use statistical methods for evaluation of a subset of features while wrapper methods use cross validation.
- Filter methods might fail to find the best subset of features in many occasions but wrapper methods can always provide the best subset of features.
- Using the subset of features from the wrapper methods make the model more prone to overfitting as compared to using subset of features from the filter methods.
6. Walkthrough example
Let’s use wrapper methods for feature selection and see whether we can improve the accuracy of our model by using an intelligently selected subset of features instead of using every feature at our disposal.
We’ll be using stock prediction data in which we’ll predict whether the stock will go up or down based on 100 predictors in R. This dataset contains 100 independent variables from X1 to X100 representing profile of a stock and one outcome variable Y with two levels : 1 for rise in stock price and -1 for drop in stock price.
To download the dataset, click here.
Let’s start with applying random forest for all the features on the dataset first.
library('Metrics')
library('randomForest')
library('ggplot2')
library('ggthemes')
library('dplyr')
#set random seed
set.seed(101)
#loading dataset
data<-read.csv("train.csv",stringsAsFactors= T)
#checking dimensions of data
dim(data)
## [1] 3000 101
#specifying outcome variable as factor
data$Y<-as.factor(data$Y)
data$Time<-NULL
#dividing the dataset into train and test
train<-data[1:2000,]
test<-data[2001:3000,]
#applying Random Forest
model_rf<-randomForest(Y ~ ., data = train)
preds<-predict(model_rf,test[,-101])
table(preds)
##preds
## -1 1
##453 547
#checking accuracy
auc(preds,test$Y)
##[1] 0.4522703
Now, instead of trying a large number of possible subsets through say forward selection or backward elimination, we’ll keep it simple by using the top 20 features only to build a Random forest. Let’s find out if it can improve the accuracy of our model.
Let’s look at the feature importance:
importance(model_rf)
#MeanDecreaseGini
##x1 8.815363
##x2 10.920485
##x3 9.607715
##x4 10.308006
##x5 9.645401
##x6 11.409772
##x7 10.896794
##x8 9.694667
##x9 9.636996
##x10 8.609218
…
…
##x87 8.730480
##x88 9.734735
##x89 10.884997
##x90 10.684744
##x91 9.496665
##x92 9.978600
##x93 10.479482
##x94 9.922332
##x95 8.640581
##x96 9.368352
##x97 7.014134
##x98 10.640761
##x99 8.837624
##x100 9.914497
Applying Random forest for most important 20 features only
model_rf<-randomForest(Y ~ X55+X11+X15+X64+X30
+X37+X58+X2+X7+X89
+X31+X66+X40+X12+X90
+X29+X98+X24+X75+X56,
data = train)
preds<-predict(model_rf,test[,-101])
table(preds)
##preds
##-1 1
##218 782
#checking accuracy
auc(preds,test$Y)
##[1] 0.4767592
So, by just using 20 most important features, we have improved the accuracy from 0.452 to 0.476. This is just an example of how feature selection makes a difference. Not only we have improved the accuracy but by using just 20 predictors instead of 100, we have also:
- increased the interpretability of the model.
- reduced the complexity of the model.
- reduced the training time of the model.
End Notes
I believe that his article has given you a good idea of how you can perform feature selection to get the best out of your models. These are the broad categories that are commonly used for feature selection. I believe you will be convinced about the potential uplift in your model that you can unlock using feature selection and added benefits of feature selection.
Did you enjoy reading this article? Do share your views in the comment section below.
You can test your skills and knowledge. Check out Live Competitions and compete with best Data Scientists from all over the world.
Saurav is a Data Science enthusiast, currently in the final year of his graduation at MAIT, New Delhi. He loves to use machine learning and analytics to solve complex data problems.








Thanks for the nice Article. 1. How does feature selection reduce overfitting? 2. How is feature importance normalized ? ( Pearson correlation gives value between -1 and 1 , LDA could have a different range )
Hi Arun. Glad you liked the article. 1. Using only the relevant features for creating your model helps you reduce the noise which comes from irrelevant features which might lower the bias but will increase the variance and thus over-fit your training set. In other words, selecting only the relevant set of features makes your model generalized. 2. Yeah, that an might pose a problem to put the importance of different filter methods onto the same scale. What can be done in this case is to choose a threshold for every test and pick out the top x% of features based on the results separately. Hope it helps.
Great article ! What is the best practice for feature selection when there are missing values in dataset ? Are there feature selection methods when there are missing values ?
Hey Mileta. Thanks! The term "best" that you have used in your question is subjective the data that you behold and the problem statement that you are looking at. There are algorithms like GBM which can deal with missing values internally in its R implementation. Although, I'll suggest you to impute the missing values first and then go for feature selection. You might find the following resources useful for missing value imputation: https://www.analyticsvidhya.com/blog/2016/03/tutorial-powerful-packages-imputing-missing-values/ https://www.analyticsvidhya.com/blog/2016/01/12-pandas-techniques-python-data-manipulation/
Great article...,.Good way to revise as well...for people who might have lost touch...
Hey Preeti. Glad you liked it!
Excellent article!...loved the easy way of using Feature Selection. Thank you, keep posting.
Hey Amit. Glad you liked it.
What a nice article! I was really very confused in feature selection but after reading your article I get a hang of it.
Hey Aditya. Thanks, happy I could help.
Great article saurav. Nicely written. Good to see that you had mentioned lasso and ridge regression methods. One thing I would add here for both methods you need to standardize the features otherwise both will penalize you more. More in ridge as the error terms are squared. thanks again. Keep it up.
Hey Ramesh. Thanks. Great tip!
Great article. Very helpful. Thank you very much for sharing. I'd only suggest you add set.seed(101) again before training the model with the 20 selected features in order to improve reproducibility of your example, as the seed is changed every time the randomForest function is executed.
Hey Ali. Glad you liked the article. Thanks for your suggestion.
Great article Saurav. ( I commented from my cell, but did not make it here so far!) Great that you mentioned lasso and ridge regression. I would like to add here that features have to be standardized for both. The penalty would be high otherwise, more in the case of Ridge as the error terms are squared in it. Keep it up. Enjoyed reading yours.
Very interesting, but I use Python not R. Any help with similar Python code? Peace & Regards, DLvK
Hey. Thanks. The links for implementation of Boruta in python as well as Losso and Ridge regression are already in the article.
Hi, superb article Just for fun I have tried to run the Boruta function on the train date from the example at the end of the article and the result was quite unexpected as described below: Boruta.data <- Boruta(Y ~ ., data = train, doTrace = 2, ntree = 500) Boruta.data #Boruta performed 31 iterations in 6.45847 mins. #No attributes deemed important. #100 attributes confirmed unimportant: X1, X10, X100, X11, X12 and 95 more. Does it mean that we are reaching here the limit of feature selection using Boruta and is the reason of such limit being the unobvious dominance of any feature of the dataset?
Hi Laurent. Since it is stock prediction data, the signal to noise ratio is very low and hence you might have got the results you got.
Fantastic article. Nicely explained. You mentioned at the beginning of the articles about the importance of Feature Selection as well as Feature Creation. This article deals primarily with Feature Selection. What are your thoughts on feature creation? Feature creation seems to be more of a trial and error process. Is it something which will come only with experience/domain knowledge or are their structured processes to help in feature creation? Any package/tool which can help with feature creation itself?
Hey Akrisrivastava. Feature creation is mostly based on domain knowledge and imagination. I believe a more relevant question might be to ask for packages that might help you with data manipulation and implementing your thoughts. I'm R there are plenty, but if I'll have to name one, its dplyr by Hadley wickham. You can find details of it in this article: https://www.analyticsvidhya.com/blog/2015/12/faster-data-manipulation-7-packages/
Very nice Article! Thank you!! Could please give some insight on the variable selection or subset creation for not a normally distributed data. Out of 100 independent variables 20 are skewed, 10 are categorical. What method would be a best fit?
Thanks Savita. It's hard for me to comment which method will be best fit. But I believe wrapper methods( Use with tree based models) might give you decent results.
I am having about 230 features, and i am using xgboost to train my model. I am using xgb.importance to remove features. Is it same as using random forest for feature selection?, Moreover, Random forest is pretty slow
No its not the same as using Random forest feature importance. But generally, Random forest does provide better approximation of feature importance that XGB. Here's a suggestion, if running random forest on complete data takes a long time, you can try to run random forest on few samples of data to get an idea of feature importance and use that as a criteria for selecting features to put in XGB.
Great Article. all concepts explained very well. Also, it will be helpful if we can have a walkthrough example in Python also. Thanks, looking forward for more articles from you
Hey Shubvyas, Thanks! There are a few resources that I have mentioned in the article itself for python users. You might like to check that out.
Thank you for this great article, I'm new in this domain and this article saved me a lot of time.
good article
Great article. Thanks a ton :-)
Excellent . I am using feature selection method in Recommender system research. But stuck in implementation. Please would you like to help me out. I am looking forward to hear you soon. Thanks
It's a good article but there are a lot for underlying assumptions that the author has overlooked. It is important that these be pointed out before hand. For e.g. Correlation is strictly a measure of linear relationship between the numeric vectors. For e.g. if Y = x^3+x^2+1, cor(x,Y) will be low but a relation exists nevertheless. Something like LDA assumes that both groups follow a normal distribution and have the same covariance structure which is rarely the case in practice. Multinomial Logit is a better alternative when such assumptions are violated for cat-cat type vectors.
A great collection of techniques! Thanks for the article.
Hi, Great article! One question, when I ran your above code, I got error once it reaches to auc function. Any idea why that is?
great article. Thank you
Great article. Two quick questions. Is the top 20 features to use is a random guess or you are looking for a specific Gini value for the cut off? What if some of the features are collinear? How do you handle that? Thank you for your help John
Hi, Thanks for the excellent article. Do you know how to select the best predictor (feature) after fitting a SuperLearner Model. i.e., extracting the best predictor out of the best fit SuperLearner model. Thanks
Hey Sourav, thanks for posting such an good article. Can you please help me out with python code for two way manova
Canu you please python code for two way manova
Hi Sourav, Thanks for sharing an wonderful material on feature selection. I am trying to open an Boruta python article which you have quoted in this article, but its not opening. it could be great if you can share any other link you have for Boruta python. Gangadhar
Hi Sourav, Thanks for sharing an wonderful material on feature selection. I am trying to open an Boruta python article which you have quoted in this article, but its not opening. it could be great if you can share any other link you have for Boruta python. Gangadhar
Hi Saurav, Thanks for the nice explanation. I am wondering in cases like class discovery, which is the situation where the actual class of data is unknown, how it is possible to use any of this method to find a subset of features to can make discriminant clusters in the training data set? Thanks a lot!
Well Written . Will definitely try these and come back with my problems.
Great article.... But can you please help me with stream data feature selection process using wrapper method in Python's
Hi Saurav its a really great article one can understand in depth on feature selection and its scope.I am working on image texture specially textile dataset could you please suggest few feature selection and extraction methods or algorithm which will give decent result.I have tried few methods like GLCM,lbp gabor, Haar and surf but the accuracy rate is average.
hi, thank you for great article, but dataset download URL is missing. please tell me how can down the file.
***************ERROR************** When I am using auc(preds, test$Y), it is showing me an error: "Error: could not find function "auc"" How can we check the accuracy then?? Please help.
Hi, Here is how you can use AUC:
roc_auc_score(y_true, y_score)which feature selection method is best for retinal images? Filter or wrapper.... Chi square or student t test etc
Awesome work here. Only one question, I wanted to sort the importance from largest to smallest but I wasn't successful. I tried using varImp form caret package also not successful. I ended up using "partialPlot" from randomForest to plot the first 20 most important features and the results were as follows; Y ~ X6+X11+X7+X55+X56+X40+X31+X64+X15+X37+X29+X30+X60+X23+X38+X48+X25+X19+X52+X2 differing from yours by 7 features i.e.i have X6, X60, etc yours doesn't. Y ~ X55+X11+X15+X64+X30 +X37+X58+X2+X7+X89+X31+X66+X40+X12+X90 +X29+X98+X24+X75+X56, What could have lead to this being that we are using the same dataset.
Hi Gbson, The author has used the seed value as 101. Did you use the same while training your model?
Thanks for your great article Can you kindly help me with this question , if i use k-fold cross validation with e.g 5 itteration , how we can decide wich features of each itteration are best features. We can calculate mean accuracy of all itteration but how can we know wich features are best
Great article! Simple and brief explanation