Top 15 Python Libraries you must know for Data Science in 2021

Table of Contents
- Scrapy
- BeautifulSoup
- Numpy
- Pandas
- SciPy
- Scikit-Learn
- Keras
- PyTorch
- XGBoost
- LightGBM
- TensorFlow
- Matplotlib
- Seaborn
- Plotly
- Pycaret
Data Mining
1. Scrapy

It is one of the most popular Python frameworks for extracting data from websites. It helps to get data from the websites in an efficient way. Scraping helps us to get structured data from the web which we can later use for our machine learning model.
This framework follows the Don’t Repeat Yourself Principle in its interface design. Most data scientists across the globe use it for gathering data from APIs.
The following code can be used to install Scrapy on your system:
pip install Scrapy
For further detail please refer below official documentation o
Scrapy 2.5 documentation — Scrapy 2.5.0 documentation
2. BeautifulSoup

It is one of the best and most popular libraries of web crawling and data scraping. This can be used to get data from HTML and XML files. It works with your favorite parser to provide idiomatic ways of navigating, searching, and modifying the parse tree. It commonly saves programmers hours or days of work.
The following code can be used to install bs4( for python3)
apt-get install python3-bs4
For further details, please refer to the official documentation below:
Beautiful Soup Documentation — Beautiful Soup 4.4.0 documentation (beautiful-soup-4.readthedocs.io)
Data Pre-Processing and Data Manipulation
1. Numpy

NumPy – It means Numerical Python. It performs scientific operations and all the stuff related to single or higher dimensional arrays. It consists of a multidimensional array of objects and a collection of routines to perform those operations. This library is fast and versatile, the NumPy vectorization, indexing, and broadcasting concepts are the de-facto standards of array computing today.
Numpy can be installed by using the below code:
pip install numpy
For further details, please refer to the official documentation :
2. Pandas

It is an open-source library which is extensively being used by data scientist all over the globe to perform data analysis and data manipulation, it is built on top of python programming language. Pandas is fast, flexible, and very powerful. Following are some application of the pandas library in the world of data science:
- Can read files like CSV, excel, ,SQL etc
- Handle high-performance datasets.
- According to need, we can perform data segmentation and segregation
- Dataset cleaning, handling missing values, handling outliers, etc.
Pandas can be installed by using the below code:
pip install pandas
For further details, please refer to the official documentation below:
pandas documentation — pandas 1.2.3 documentation (pydata.org)
3. SciPy

SciPy is an open-source library that is used for solving scientific, mathematical, and technical problems. SciPy is built on top of the python Numpy extension. It contains a variety of sub-packages for different applications. We can say it is an advanced version of Numpy which has some additional features like it contains a fully-featured version of linear algebra. Scipy is fast and having high computation power.
Scipy can be installed by using the below command:
pip install scipy
For further detail, please refer to the official documentation below:
SciPy — SciPy v1.6.2 Reference Guide
Data Modeling
1. Scikit-Learn

Scikit Learn is the most useful library for Machine Learning in Python. It is an industry-standard for most data science projects. It is a simple and very fast tool for predictive data analysis and statistically modeling. This library is built using python on top of NumPy, SciPy, and matplotlib. Some of the scikit learn features include Regression, Classification, Clustering, Dimensionality Reduction using only a few lines of code.
For your reference, I am attaching a scikit learn algorithm cheat-sheet
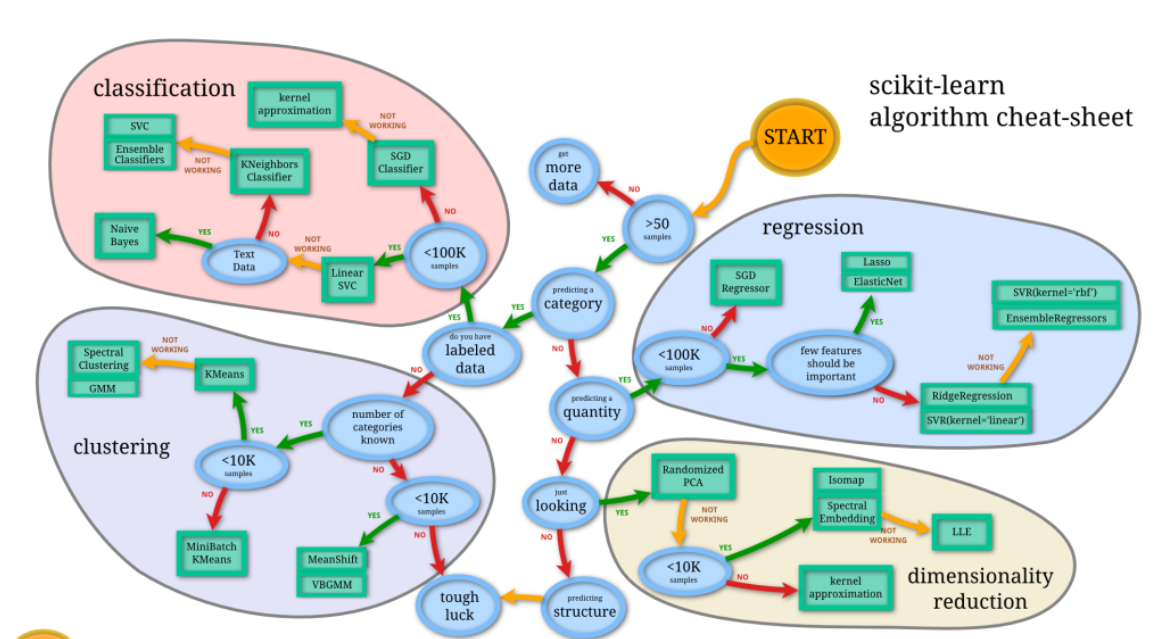
Scikit learn can be installed by using the following command:
pip install -U scikit-learn
For further details, please refer to the official documentation below:
scikit-learn: machine learning in Python — scikit-learn 0.24.1 documentation (scikit-learn.org)
2. Keras

Keras is a great python library that is used to train deep learning models. It runs on top of the machine learning platform Tensorflow. It’s very easy to use and very fast. Build on top of Tensorflow 2.0, Keras is an industry-strength framework that can scale to large clusters of GPUs.
For further details, please refer to the official documentation below:
Keras: the Python deep learning API
3. PyTorch

It is an open-source machine learning and deep learning framework developed by Facebook’s AI researcher. Worldwide many data scientists are extensively using PyTorch for natural language processing and computer vision problem. Moreover, it has a deployment feature for mobile and embedded frameworks.
The below image shows some advanced features of PyTorch

For more details, refer to the below link:
4. XGBoost

XGBoost is an optimized distributed gradient boosting library designed to be highly efficient, flexible, and portable. It implements machine learning algorithms under the Gradient Boosting framework. XGBoost provides a parallel tree boosting (also known as GBDT, GBM) that solves many data science problems in a fast and accurate way. The same code runs on a major distributed environment (Hadoop, SGE, MPI) and can solve problems beyond billions of examples.
Install XGBoost using the below code-
pip3 install xgboost
Advantages of XGBoost
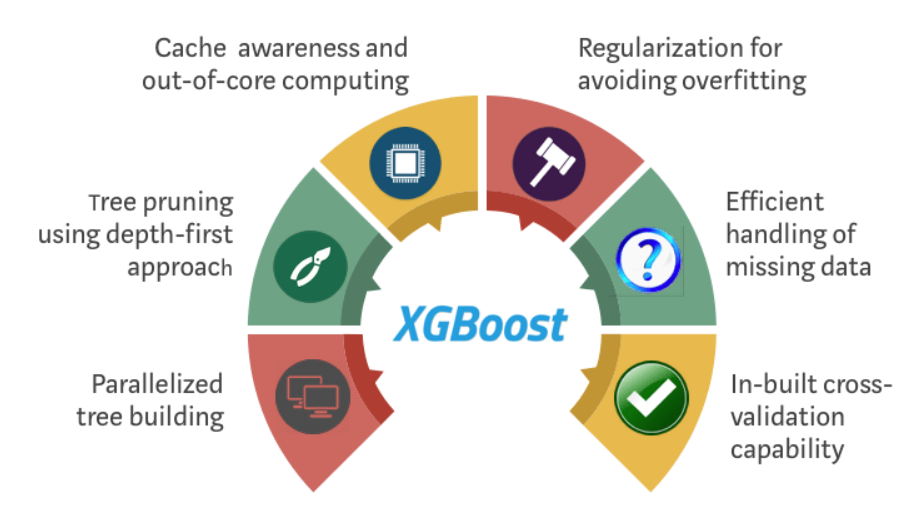
For more information refer to the below link:
5. LightGBM

LightGBM is a gradient boosting framework based on decision trees to increases the efficiency of the model and reduces memory usage.
Following are the advantages of LightGBM:
- Faster training speed and higher efficiency.
- Lower memory usage.
- Better accuracy.
- Support of parallel, distributed, and GPU learning. Capable of handling large-scale data.
Architecture of lightGBM
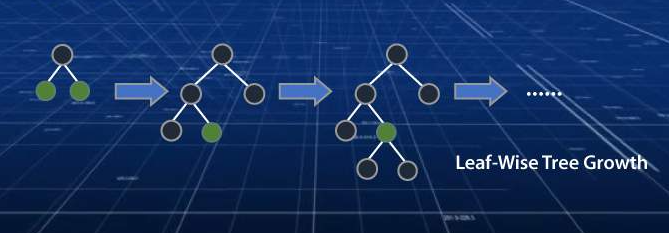
For more details, please refer to Features.
6.TensorFlow

TensorFlow is an open-source end-to-end platform for creating Machine Learning applications. It is a symbolic math library that uses dataflow and differentiable programming to perform various tasks focused on training and inference of deep neural networks. It allows developers to create machine learning applications using various tools, libraries, and community resources.
Currently, the most famous deep learning library in the world is Google’s TensorFlow. Google product uses machine learning in all of its products to improve the search engine, translation, image captioning, or recommendations.
Features of TensorFlow:

For more detail refer to this TensorFlow
Data Visualization
1. Matplotlib

Matplotlib was introduced by John Hunter in 2002. It is an amazing visualization library in Python for 2D plots of arrays. It is one of the most worldwide used data visualization libraries. It is simple and easy to use. It is a multi-platform data visualization library built on NumPy arrays and designed to work with the broader SciPy stack.
One of the greatest use of matplotlib is that it has a large number of charts. It has a wide range of spectrum includes bar plot, scatter plot, histogram, line charts, etc.
Use the following code to install matplotlib:
python -m pip install -U matplotlib
For more information refer below link
Matplotlib: Python plotting — Matplotlib 3.4.1 documentation
2. Seaborn

Seaborn is a python library for data visualization. It is built on top of matplotlib. It provides a high-level interface for drawing attractive and informative statistical graphics. The main advantage of seaborn over matplotlib is that firstly it resolves the problem of default matplotlib parameters and secondary working with data frames. The main features of seaborn are:
- Help in styling matplotlib graphs. This feature by default is present in seaborn
- Help in visualizing linear regression models.
- Works well with NumPy arrays and pandas data frames.
Use the following to install seaborn:
pip install seaborn

For more information refer to the below link:
seaborn: statistical data visualization — seaborn 0.11.1 documentation (pydata.org)
3. Plotly

Plotly an open-source python library that can be used for data visualization and understanding data easily and simply. It supports various types of plots like scatter plots, line charts, histograms, bubble charts, contour plots, cox plots easily. But now you must be wondering why we use plotly if matplotlib and seaborn are already there in the market????
Here is the answer to why you should use plotly:
- It produces interactive graphs
- Graphs and very attractive.
- It provides the feature of customization of our graphs
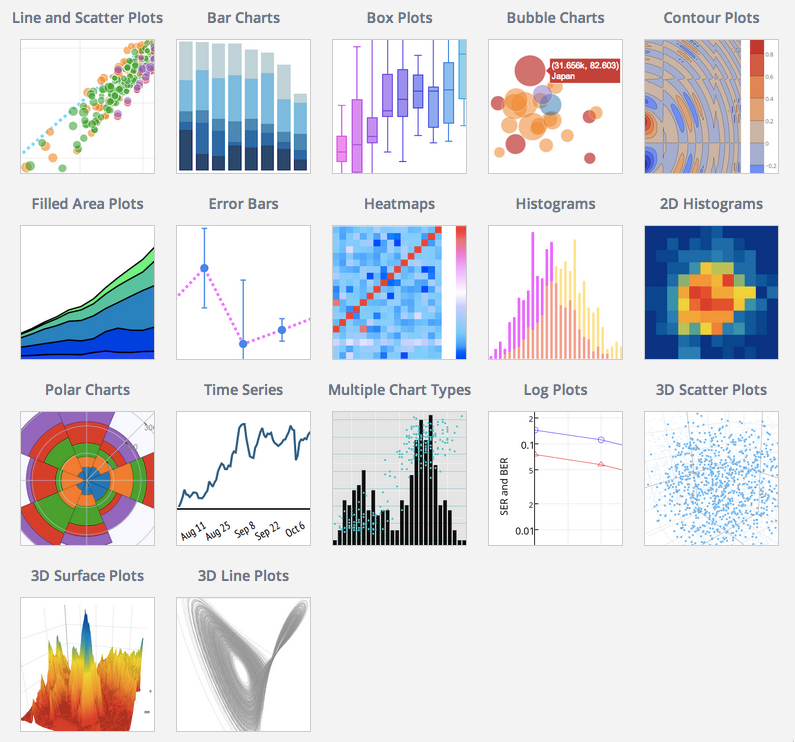
Installation:
pip install plotly
Refer to this for more information:
plotly package — 4.14.3 documentation
4. PyCaret
PyCaret is a python open-source low-code machine learning library that aims to automate machine learning workflows. It is a machine learning management tool that speeds up the machine learning project lifecycle. It helps data scientists to perform machine learning end-to-end tasks easily quickly.
- With a few lines of code, it increases productivity
- PyCaret being a low-code library makes you more productive. With less time spent coding, you and your team can now focus on business problems.
- PyCaret is a wrapper around many ML models and frameworks such as XGBoost, Scikit-learn, and many more.
Use this code for installation:
pip install pycaret
Refer to this for more information:
If you do like this article or it helps you in any way , then please do like .It will motivate me to write more useful articles. In case any help mail me at [email protected] or connect me with LinkedIn Akshay Gupta | LinkedIn.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.









Nice work! Useful programming information for beginners! Thanks!