Beginner’s Guide to AutoML with an Easy AutoGluon Example

Machine Learning is popular and is being used everywhere for applications ranging from financial services to healthcare, marketing & advertising to manufacturing. Almost all industries seem to derive substantial benefit using some form of Machine Learning. Over the recent past, automation technology also seems to be picking up along with Machine Learning. When these two are combined, we arrive at something amazing called ‘automated machine learning’ or simply ‘AutoML’. Therefore, this guide aims to generate awareness of the basics of AutoML tools and technology.
You will find two sections in this guide for easier understanding. The first section deals with the background information on AutoML while the second section covers an end-to-end example use case for AutoGluon – one of the AutoML frameworks.
Follow along this guide to familiarize yourself with the concepts, get to know some existing AutoML frameworks, and try out an example based on AutoGluon. Additionally, find the answers to some interesting questions such as-
-
Why is AutoML required?
-
What benefits does AutoML offer over the normal method of selecting conventional ML models?
-
Who can use AutoML?
-
Where can it be used?
-
How does AutoML work?
-
When to use and when to avoid using AutoML?
Understanding the Basics of AutoML
Need for AutoML
So beginning with the first question, do we need AutoML and why? Machine learning algorithms have become increasingly popular in recent years and their success in assisting the decision-making process in a wide range of applications is well-known. A typical machine learning model includes the following steps:
-
Data Collection
-
Data Preparation
-
Algorithm selection
-
Model Training
-
Model Evaluation
-
Parameter Tuning
-
Model Prediction and Interpretation
The figure below shows a generic representation of the steps carried out in a traditional Machine Learning process from Data collection to Model Predictions.

Steps in Traditional Machine Learning (Image Source: Author)
From the above image, we can guess why many businesses find it difficult to implement traditional ML models. This is due to the complexity and the amount of learning involved in implementing the machine learning model. It also requires extensive domain expertise to generate and compare multiple models before selecting the best one. AutoML promises to simplify these challenges.
Thus, in a broader sense, AutoML has been introduced for automating the process of building an entire Machine Learning pipeline, with minimal human intervention.
Benefits of using AutoML
In general, an AutoML model aims to automate all time-consuming operations like the selection of algorithms, writing the code, pipeline development, and hyperparameter tuning thereby allowing the data scientists to focus more on speedily resolving the business challenges at hand. Within the pipeline, the AutoML framework
-
Considers and selects multiple machine learning algorithms from the available ones like the random forest, k-Nearest Neighbor, SVMs, etc.
-
Performs data preprocessing steps like missing value imputation, feature scaling, feature selection, etc..,
-
Optimization or the hyperparameter tuning for all of the models
-
Decides/Tries multiple ways to ensemble or stack the algorithms
Currently available AutoML frameworks
The AutoML technology and the AutoML frameworks are quite new. Currently, there are various AutoML frameworks that can work with a variety of data, available in both open-source and paid versions.
Some popular AutoML packages are:
-
AutoGluon (2020): This popular AutoML open-source toolkit developed by AWS helps in getting a strong predictive performance in various machine learning and deep learning models on text, image, and tabular data. Installation is supported for the Linux & Mac operating systems whereas Windows is not an officially supported OS for this toolkit.
-
MLBox (2017): Another well-known open-source Python-based AutoML library is MLBox. However, it is a powerful library that offers three sub-packages related to Pre-processing (to read and pre-process data), Optimization (to test and/or optimize the models) and Prediction (to predict the outcomes on a test dataset). Additionally, it can perform feature selection, hyper-parameter optimization, automatic model selection for classification and regression as well as predicting the target variables for selected models.
-
AutoWEKA (2013): Auto-WEKA uses a fully automated approach and leverages the Bayesian optimization to select a machine learning algorithm and set its hyperparameters. In other words, it helps in applying the best parameter settings for a given classification or regression task automatically to get a nice model.
-
Auto-sklearn (2015): This AutoML framework has been developed by Matthias Feurer, et al and according to the official documentation is based on Bayesian optimization, meta-learning, and ensemble construction. Algorithm selection and hyperparameter tuning are automated using this framework. This framework only supports sklearn based models i.e. this is not suitable for graphical models or sequence prediction problems.
-
Auto-PyTorch (2019): This framework has been developed by the AutoML Groups of the University of Freiburg and Hannover. It is based on the PyTorch deep learning framework and it supports the tabular data of classification and regression. Also, it can be applied to image data for classification.
-
Autokeras (2017): It is an open-source library used in deep learning for automating tasks. It helps you in getting good neural network models for classification and regression tasks. The AutoML Toolkit has been built on top of the deep learning framework Keras, developed by the Datalab team at Texas A&M University. Since Auto-Keras follows the classic Scikit-Learn API design, the syntax is similar and easy to use.
-
TPOT (2018): Tree-based Pipeline Optimization Tool (TPOT) is also one of the popular open-source AutoML frameworks which use sci-kit learn library as a part of its ML menu. According to the official documentation, it uses genetic programming to intelligently explore thousands of possible pipelines to find out a top-performing model pipeline for a given dataset. It is important to note here that TPOT does not perform any pre-processing of the dataset and hence, expects the fed dataset to be clean. However, it can perform feature processing, model selection, and hyperparameter optimization to return the best-performing model. It is a good choice for regression and classification problems but it is not suitable for NLP.
-
H2O AutoML (2018): The H2O 3 AutoML framework is an open-source toolkit best suited to both traditional neural networks and machine learning models. It can be used to automate the machine learning workflow i.e. model training and hyperparameter tuning of models within a specified time duration. It can perform data preprocessing, model selection, and hyperparameter tuning. Additionally, it returns with a leaderboard view of the model along with its performance. However, it is important to note that a java runtime environment is required since H2O AutoML has been developed in java.
-
MLJAR (2019): This toolkit works with tabular datasets and offers transparency to the users in each step of the AutoML training. All information about the trained models is saved in the hard drive and is accessible to the ML user.
There are some more AutoML libraries that are not mentioned in the article like –
Open-source: AdaNet, TransmogrifAI, Azure Machine Learning, Ludwig
Commercially available:Darwin,DataRobot,Google AutoML
Who can use AutoML and where can it be used?
In a broader sense, the idea is to reduce the need for human interaction with the help of AutoML. During training, AutoML focuses on optimizing not only the model weights but also the architecture. The goal is to automate the process of selecting an architecture, which is currently done by experienced Data Scientists. Auto-ML will perform all the above-mentioned tasks without asking many questions and that too in a shorter time. Thus, making the Machine Learning tasks easier. Automated Machine Learning offers different processes and techniques to make Machine Learning easily available and makes it simple for non-Machine Learning experts. That is why you will find that most of the AutoML frameworks mentioned earlier in this guide have been developed by the tech giants for the greater good. Thus, AutoML can be used by Software Engineers to develop applications without the need to know the details on working of ML algorithms, Data Scientists to build ML pipelines in a low-code environment, ML Engineers to speed up their work, and last but not least AI Enthusiasts to explore the capabilities of AutoML.
By now, one can see that AutoML can be used to deliver value in real-world challenges like Image classification, customer churn prediction, process automation, fraud detection, product & services personalization, digital marketing & advertising, anomaly detection, and many more.
How does AutoML work?
AutoML frameworks begin by connecting to the provided dataset. It is important to note that the selected dataset contains enough data to develop a supervised machine learning model for classification or regression. This dataset should particularly include the target variable as well as any other data that will be used as features for the model to use as input for its predictions. It is possible to drop non-relevant attributes when feeding the dataset to the AutoML framework. Users also need to specify the target column as well when using an AutoML tool. Further, the AutoML framework produces a data profile similar to the outcome of an EDA after the input dataset has been set up. We can find the descriptive statistics for each variable in the dataset, such as mean, median, quartiles, and so on, in this data profile. The AutoML tool determines whether variables are numeric vs. categorical and counts missing values for each variable as part of this data profiling process. Next, AutoML tools experiment with multiple models and perform optimization as well. Most hyperparameter tuning begins with some random sampling. So, most of the AutoML tools tend to use a strategy for intelligently refining samples. Such a trained and optimized model can then be deployed in a production environment using Rest APIs.
When to use and when to skip using AutoML?
AutoML performs well for structured data i.e., when the columns are clearly labeled and the data is well-formatted. As these tools perform imputation and normalization, they can easily handle missing values or skewness in the dataset.
AutoML performs extremely well when we need a quick assessment of the model. Next, small to medium size datasets would obviously be trained quicker using AutoML as compared to larger datasets. Choosing AutoML for larger and complex datasets might be a tough choice as it can prove expensive due to the use of more resources or it could be extremely slow due to multiple experiments for hyperparameter tuning and model optimization.

Steps covered in an AutoML framework (Image Source: Author)
Section II: End-to-End AutoML example using AutoGluon
In this section of the guide, we will explore AutoGluon’s different features which automate the machine learning tasks. Additionally, we will experience the implementation of tabular prediction using AutoGluon along with the other prediction categories it supports. Further, we will try to find out how to get the best suitable model for a particular machine learning task when using AutoGluon. Let’s start exploring this AutoML tool.

AutoGluon Logo (Image Source: Official Website)
The following are the benefits of using the ‘AutoGluon’ library:
-
Simplicity: Training of classification and regression models and deployment can be achieved with a few lines of code.
-
Robustness: Without doing any feature engineering or data manipulation, users should be able to use raw data.
-
Predictable-timing: Getting the best model under a specified time constraint.
-
Fault-tolerance: Training can be resumed even if interrupted and the users can inspect all the intermediate steps.
AutoGluon is designed for both beginners and experts in machine learning. Deep learning, automated stack ensembling, and real-world applications for text, image, and tabular data are covered by this tool.
Tool installation requirements
AutoGluon requires Python version 3.6 or higher. Currently, Linux and Mac are the only operating systems that are fully supported. All the details on the installation of AutoGluon and its different versions are here. AutoGluon can be used for the following categories:
-
Tabular Prediction
-
Image Prediction
-
Object Detection
-
Text Prediction
-
Multimodal Prediction
Example#1- TabularPrediction(Classification) with AutoGluon
In this example, we will use the Stroke prediction dataset. You can download the dataset from Kaggle.
We start by importing all the necessary packages
Python Code:
from sklearn.model_selection import train_test_split #splitting the dataset from autogluon.tabular import TabularDataset, TabularPredictor #to handle tabular data and train models
Next, we split the dataset into train and test sets.
# split into train and test sets
df_train,df_test=train_test_split(df,test_size=0.33,random_state=1) df_train.shape,df_test.shape
>>((3423, 12), (1687, 12))
df.head()

We need to drop the outcome column from the newly created test set
test_data=df_test.drop(['stroke'],axis=1) test_data.head()

Now, we build a predictor to train for classifying whether an individual with a given set of conditions will probably be at risk of a stroke. For this, we specify the outcome column as ‘stroke’ and ask the predictor to fit the algorithms on the train dataset. Arguments (optional) ‘verbosity=2’ will display all the steps the predictor is taking to arrive at the best model while ‘presets= best quality’ will ensure that the best model is selected from the trained ones. There are other additional arguments mentioned in the official documentation which can be used to fine-tune the model.
predictor= TabularPredictor(label =’stroke’).fit(train_data = df_train, verbosity = 2,presets='best_quality')
Let us scroll through the log from the above command. (As the log is quite long, only the snippets from the log wherever required have been included in this section).
We can notice that even though we did not specify the type of problem, AutoGluon perfectly understands that this is a binary classification problem based on the two unique labels ‘0’ & ‘1’ in the outcome column.
Further, we can also see that AutoGluon aptly selects the ‘accuracy’ metric for this classification task.
Once the classifier training is complete, we can print a summary of the models it has trained using the following command
predictor.fit_summary()
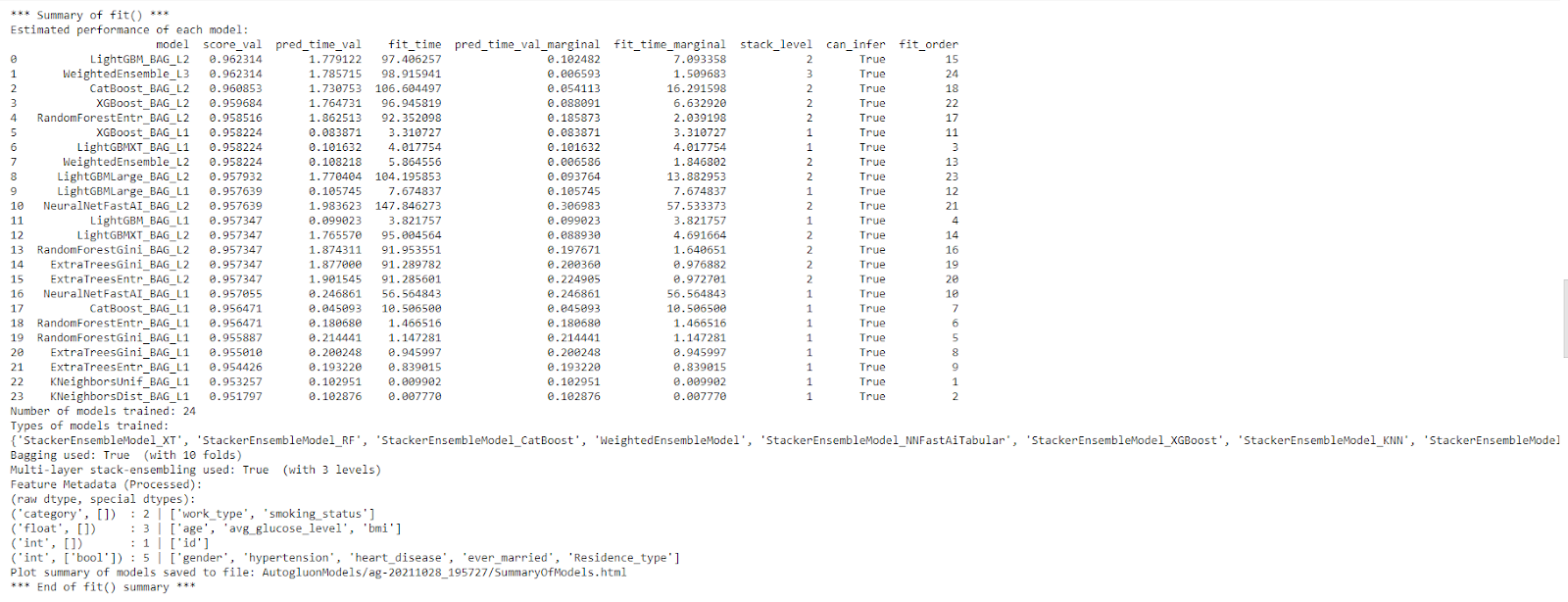
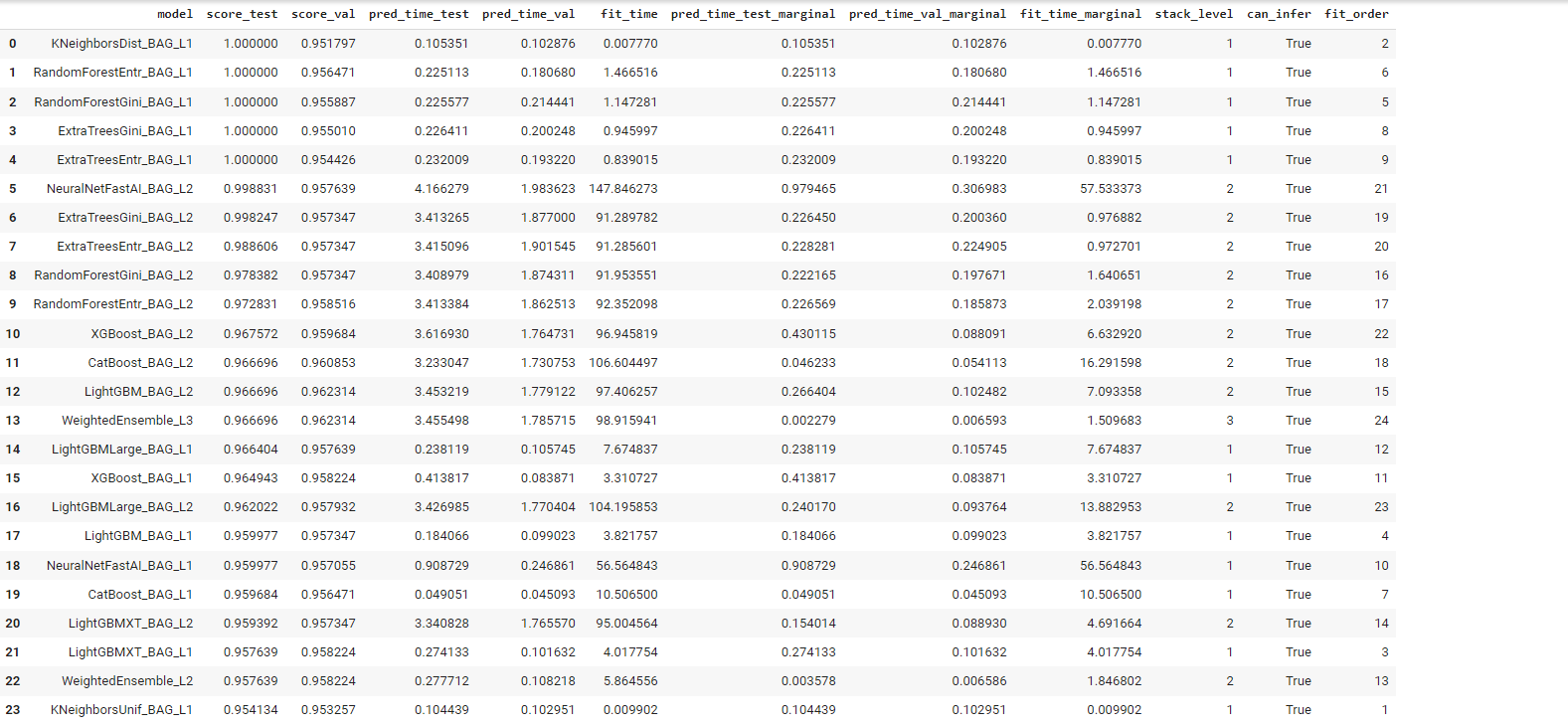
In this case, AutoGluon trained 24 models but we would be more interested to find out which is the best model as selected by AutoGluon. To display this, simply use the leaderboard() command which ranks the trained models in order.
predictor.leaderboard(df_train, silent=True)
Additionally, we can also check for the feature importance using
predictor.feature_importance(data=df_train)
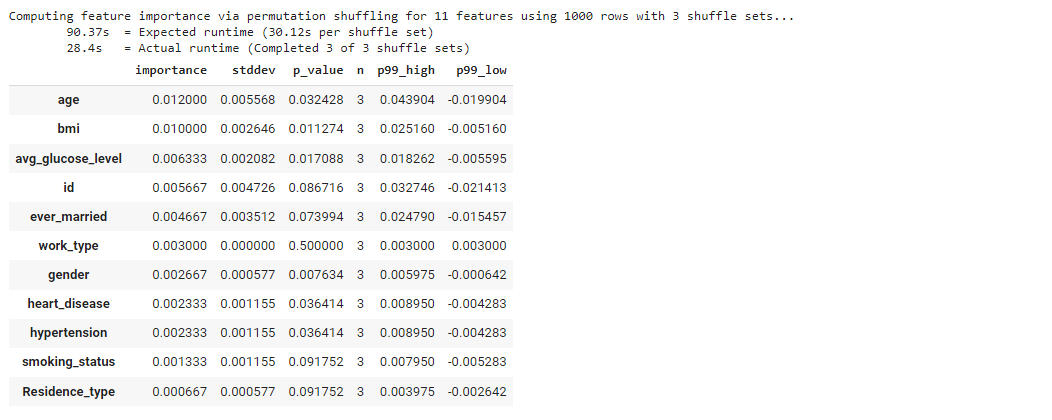
Here we can see that it has identified age and bmi to be the most important factors in the prediction of the outcome.
Next, we feed the test data to the classifier for prediction and we can store it in a DataFrame
y_pred = predictor.predict(test_data) y_pred=pd.DataFrame(y_pred,columns=['stroke']) y_pred #print the DataFrame

To understand the evaluation metric ‘accuracy’, let us print the details for it.
predictor.evaluate(df_test)
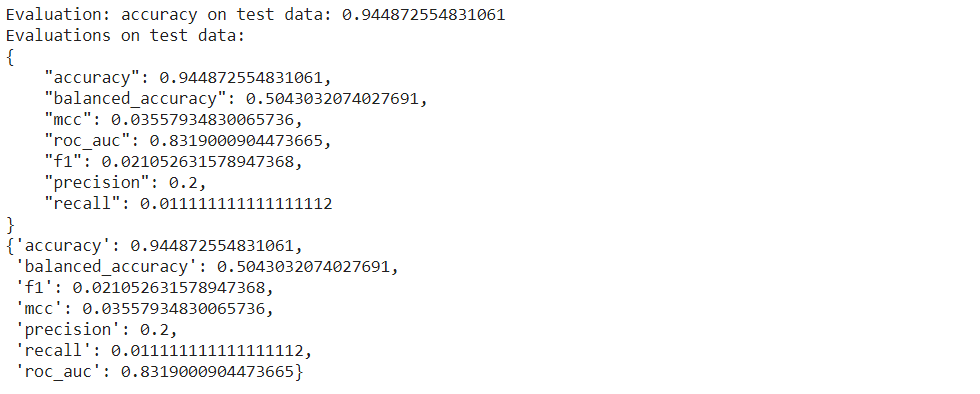
Data preprocessing and Feature Engineering were carried out by AutoGluon. The trained model includes cross-validation as well. So, we got the trained classifier at 95% accuracy with just two lines of code (for the classifier to train and predict). Now, that’s impressive! If it were a traditional ML model, we would be spending a long time completing the entire process including EDA, data cleaning as well as coding to set up multiple models. AutoGluon made this quite simple for us.
Example#2- TabularPrediction(Regression) with AutoGluon
Let us try another example to explore how AutoGluon’s TabularPrediction handles a regression problem. For this, we will use the ‘Boston prices’ dataset from the sk-learn dataset library. We follow the same set of steps from the previous example
#importing the dataset import numpy as np import pandas as pd from sklearn.datasets import load_boston boston= load_boston() boston.keys() print(boston.DESCR)#use this command to know more about the dataset
Creating a DataFrame from the loaded dataset
#create a dataframe from the dataset df=pd.DataFrame(data=boston.data,columns=boston.feature_names) df.head()
Append the target column to the dataframe
#adding price column to the dataframe df['PRICE'] = boston.target df.head()
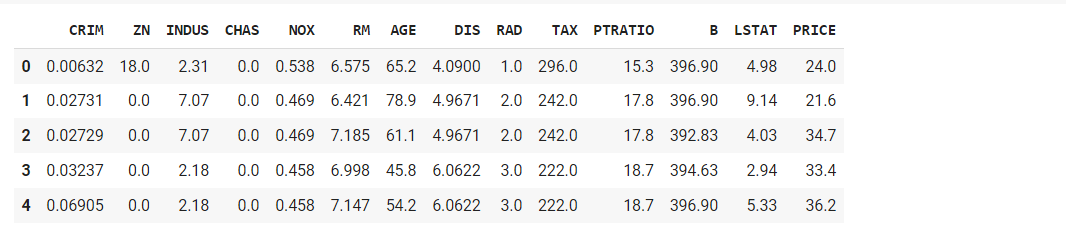
Splitting the dataset
# split into train test sets df_train,df_test = train_test_split(df, test_size=0.33, random_state=1) df_train.shape,df_test.shape
>>((339, 14), (167, 14))
We will drop the target column from the test dataset.
test_data=df_test.drop(['PRICE'],axis=1) test_data.head()
Setup the predictor (regressor)
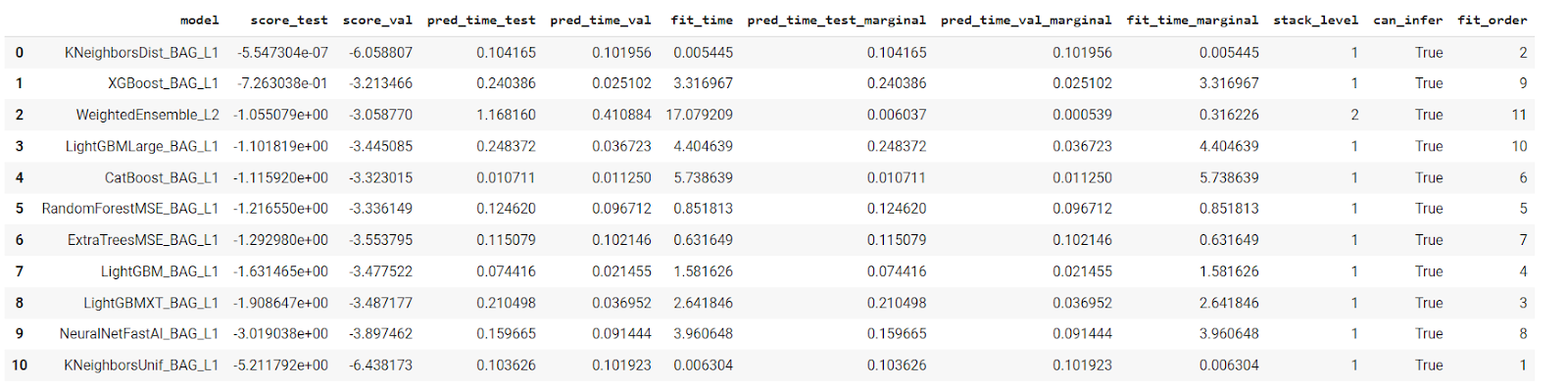
predictor= TabularPredictor(label =’PRICE’).fit(train_data = df_train, verbosity = 2,presets='best_quality') predictor.leaderboard(df_train, silent=True)
# Making Predictions y_pred = predictor.predict(test_data)
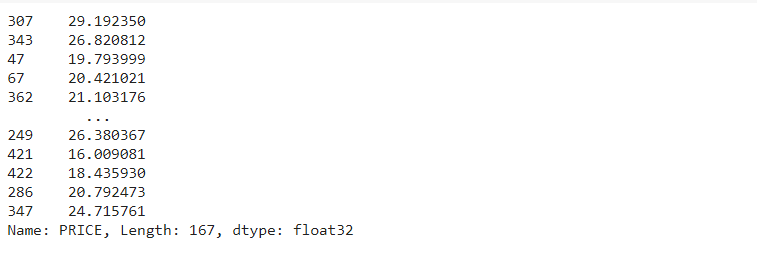
In this example too, AutoGluon correctly identified the type of problem as Regression based on the dtype=float for the column and the presence of multiple unique values. Next, it also aptly selected the evaluation metric as ‘root_mean_squared_error’
For the regression problem, AutoGluon trained 11 models and recommended kNN (KNeighborsDist_BAG_L1) as the best model followed by XGBoost (XGBoost_BAG_L1).
The syntax for the predictor is the same in both classification and regression problems. AutoGluon TabularPrediction task seems to work nicely on different datasets. To keep the tutorial simple we selected smaller datasets, but it would be interesting to see how it performs when a bigger dataset is used.
Other use cases in AutoGluon
Before we wrap up the guide, let us briefly look at the other available options in AutoGluon.
-
Image Prediction: Like Tabular prediction, AutoGluon uses a simple ‘fit()’ command for classifying images based on their content which automatically produces high-quality image classification models.
-
Object Detection: Object detection is an important task in computer vision involving the process of detecting and localizing objects in an image. Here too, AutoGluon gives an option of calling a simple ‘fit()’ command which will automatically generate a high-quality object detection model for identifying the presence and location of objects in images.
-
Text Prediction: Likewise for the prediction of text data in supervised learning, we can use a simple ‘fit()’ command to automatically generate high-quality text prediction models. Each training example in the data may be a sentence, a short paragraph, some additional numeric/categorical features present in the text. A single call to ‘predictor.fit()’ command can train highly accurate neural networks on the given text dataset where the target values or labels used to predict may be continuous values or individual categories. Even though the TextPredictor is designed for classification and regression tasks only, it can directly be used for other NLP tasks also if the data is properly formatted into a data table. The TextPredictor uses only Transformer neural network models. These are fit to the provided data via transfer learning from a pre-trained list of NLP models like BERT, ALBERT, and ELECTRA. It also allows training on multi-modal data tables which contain text, numeric and categorical columns, and the neural network hyperparameter which can be automatically tuned with Hyperparameter Optimization (HPO).
-
Multimodal Prediction: Multimodal tabular data consisting of text, numeric, and categorical columns can also be handled by AutoGluon. Raw text data is observed as a first-class citizen of data tables in AutoGluon. It can help you train and match a wide variety of models including classical tabular models like LightGBM, RF, CatBoost as well as the pre-trained NLP model-based multimodal network.
Conclusion
It is quite interesting to see the effectiveness of AutoML frameworks. It could be used to reduce the time it takes to create production-ready ML models with remarkable simplicity and efficiency. This expedites the overall ML process; thereby freeing up time for data scientists so that they focus on finding the solution to real-life problems. The biggest benefit of using AutoML could be attributed to its ability of training and test multiple existing machine learning algorithms on a variety of data sets autonomously. Further, it is to be noted that using AutoML does not remove the need for training and some basic understanding of data, data annotation, and the desired outcome. Thus, AutoML’s success would likely depend on how soon it is accepted, adopted and the tangible benefits it brings to a certain industry. Nevertheless, we can say that AutoML is there to stay.
Author Bio:
Devashree has an M.Eng degree in Information Technology from Germany and a Data Science background. As an Engineer, she enjoys working with numbers and uncovering hidden insights in diverse datasets from different sectors to build beautiful visualizations to try and solve interesting real-world machine learning problems.
In her spare time, she loves to cook, read & write, discover new Python-Machine Learning libraries or participate in coding competitions.
You can follow her on LinkedIn, GitHub, Kaggle, Medium, Twitter.








Is the columns parameter in y_pred=pd.DataFrame(y_pred, columns=['stroke']) naming or selecting the stroke column? To my beginner's understanding, that two columns then appear in the results is in conflict with both possibilities. And, what are the two columns? thank you