Can Voice Conversion Improve ASR in Low-Resource Settings?
This article was published as a part of the Data Science Blogathon.
 Source: Canva
Source: Canva
Introduction
Voice conversion (VC) can be used to improve the performance of speech recognition systems in low-resource languages by augmenting limited training data. However, VC has not been extensively used for this task considering the practical issues like compute speed and limitations when converting to and from unseen speakers. Considering this, it becomes necessary to design a voice conversion model that can convert to and from unseen speakers (speech) during training and be computationally efficient and fast.
In light of the above, Matthew Baas and Herman Kamper have examined whether the VC system trained on a high-resource language can be used to produce additional training data for unseen low-resource language, which we will be exploring in this article.
Highlights
-
It was assessed whether a VC system could be used cross-lingually to improve low-resource speech recognition.
-
Several recent techniques were combined to design and train a practical VC system in English. Then this system was used to augment data for training speech recognition models in low-resource languages.
-
When a reasonable amount of VC augmented data is used, the performance of speech recognition is improved in all four low-resource languages.
-
VC-based augmentation is superior to SpecAugment (a widely used signal processing augmentation method) in the low-resource languages taken under consideration.
What is Voice Conversion?
Voice Conversion (VC) is a technique in which the utterance spoken by a speaker is processed in such a manner that it sounds as if a different target speaker spoke it while the content remains unchanged. Some recent solutions even provide fine-grained ways to control different aspects of the generated speech, such as naturalness, pitch, speed, etc. Furthermore, they can be used cross-lingually too.
Voice Conversion Method Overview
Since the objective is to use Voice Conversion (VC) for low-resource data augmentation, it becomes necessary to design a voice conversion model that can convert to and from unseen speakers (speech) during training in addition to being computationally efficient and fast.
Given the preceding, the method illustrated in Figures 1a and 1b has been proposed. In this, an input waveform is first transformed into a series of feature vectors, and the linguistic content (the words being spoken) is then separated from the speaker information. This is done with the aid of specially designed style and content encoders, which are indicated by dashed boxes. While the style encoder generates a single style vector (s), the content encoder generates a sequence of content embedding vectors.
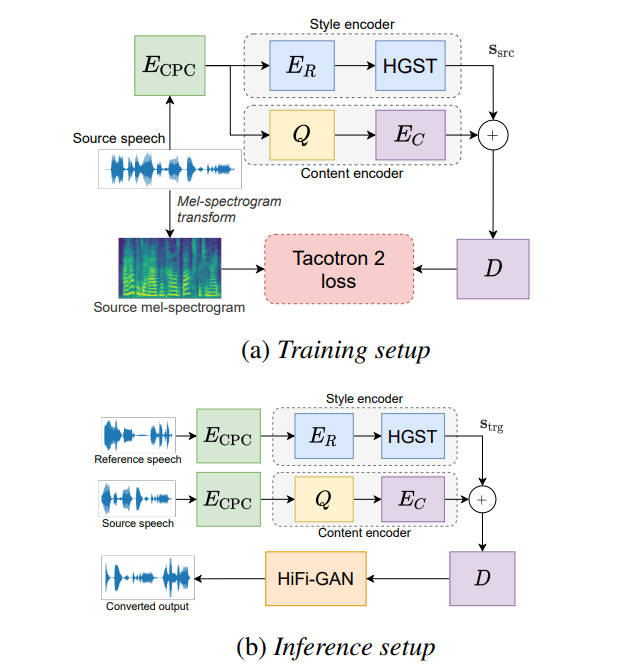
Figure 1: Voice Conversion Approach. (a) During training, the same utterance is passed through a CPC encoder into the content and style encoders; the decoder attempts to reconstruct the spectrogram of the input utterance. (b) At inference, separate input and reference utterances are fed into the style and content encoders, respectively, before using HiFi-GAN to vocoding the spectrogram.
During training (Figure 1a), the style vector (s = ssrc) and content embeddings are derived from the same input utterance. The model is trained to reconstruct the input by summing ssrc with each content embedding, feeding the resulting vectors into a decoder module.
At testing (Figure 1b), the content and speaker encoders receive speech from different utterances. This indicates that the source or reference utterance (or both) may originate from languages and speakers not encountered during training. If the content and speaker information are properly separated, the source utterance will be generated in the speaker’s voice, supplying the reference utterance.
Results
1. First, it was noted that using more augmented data tends to boost performance, with the lowest WER attained with 500% additional data generated by chaining VC and SpecAugment in conjunction (See Table1). Second, VC augmentation offers comparable performance gains to SpecAugment when applied independently. Third, using both VC and SpecAugment in conjunction enhances performance more than either alone. This indicates that these two approaches are complementary in English.
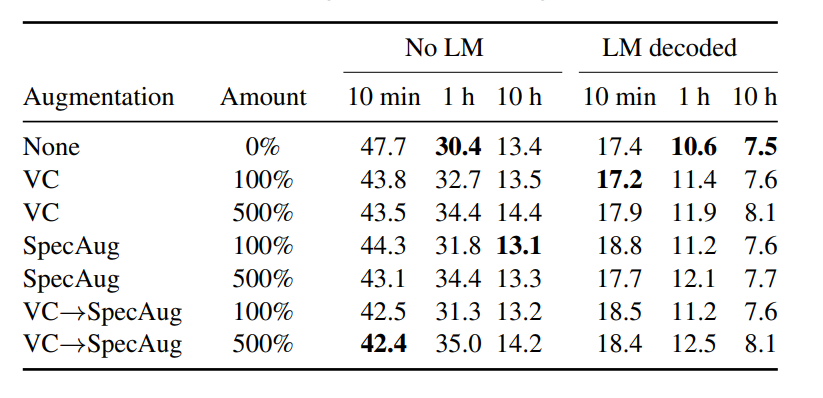
Table 1: WERs (%) on LibriSpeech test data for ASR models trained with increasing amounts of VC- and SpecAug-augmented data, with and without 4-gram LM decoding
2. Very low-resource settings: When an adequate amount of VC augmented data is used, speech recognition performance is improved in all four low-resource languages studied. Afrikaans, Setswana, isiXhosa and Sepedi. Table 2 indicates that when 10 minutes of additional data is generated using the English-trained VC system, ASR performance improves for all four unknown languages. For isiXhosa, adding the augmented data results in a 7% absolute gain in WER. Chaining VC in conjunction with SpecAugment degrades the performance. However, W/CER worsened in all cases compared to training with just the original data. SpecAugment was also used on Afrikaans in isolation, resulting in poor performance compared to no augmentation.
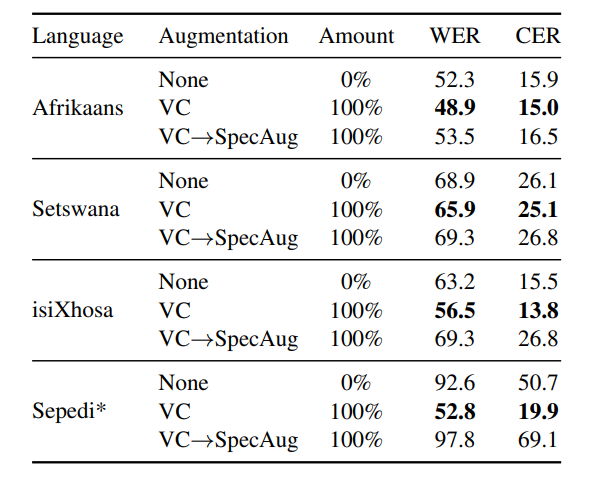
Table 2: ASR results (%) on test data of 4 low-resource languages when trained on 10 minutes of real audio data plus different amounts of additional VC- and combined VC-SpecAug augmented data.
For the low-resource languages evaluated, VC-based augmentation outperforms SpecAugment. Furthermore, a VC system trained on a single well-resourced language (English) can be used cross-lingually to generate additional training data for unseen low-resource languages. When labelled resources are scarce (approximately 10 minutes), ASR performance improves in all four low-resource languages studied.
Limitation
The interaction between the VC and the conventional augmentation was not thoroughly investigated, nor was it assessed how various design decisions within the VC model itself affect the performance of the downstream ASR task.
Conclusion
To sum it up, in this article, we learned the following:
1. It was examined whether a VC system can be leveraged cross-lingually to improve low-resource speech recognition.
2. Several recent techniques were combined to design and train a practical VC system in English. Then this system was used to augment data for training speech recognition models in low-resource languages.
3. For the low-resource languages evaluated, VC-based augmentation outperformed SpecAugment. Furthermore, it was found that a VC system trained on a single high-resourced language (English) can be used cross-lingually to produce additional training data for unseen low-resource languages.
4. Using both VC and SpecAugment in conjunction improves performance more than alone; this indicates that these two approaches are complementary in English.
That concludes this article. Thanks for reading. If you have any questions or concerns, please post them in the comments section below. Happy learning!
Read here| https://arxiv.org/pdf/2111.02674.pdf
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.







