Top 5 Failures of AI Till Date | Reasons & Solution
This article was published as a part of the Data Science Blogathon.
Introduction
How many times have you failed in your life? What a question this is, isn’t it? Unless you are overly genius or optimistic, you will probably answer that 100, 1000, or uncountable times.
And perhaps every time you failed and had to bear the consequences of failure, you thought – “What if I could work like a computer!”
No doubt, the power of computing gives us the ability to automate tasks and reduce failures. The addition of AI enables decisions to be made based on the based-on data. But what if, despite all the hype, AI systems fail to provide anticipated results?
The decision and predictions made by AI systems rely on concepts such as probabilistic methods and statistical analysis. AI considers the uncertainty and variability inherent in real-world data and makes predictions based on the most likely outcomes. To test the algorithms, techniques such as cross-validation and model selection are used to evaluate the system’s performance and identify any weaknesses or biases.

However, there are times when accurately trained AI systems have failed and produced wrong or misleading results. At the fundamental level, our AI models show poor performance metrics. But this article covers 5 interesting examples when well-trained AI models behaved opposite to what we expected.
Case 1: When Microsoft’s Tay Turned Hateful!
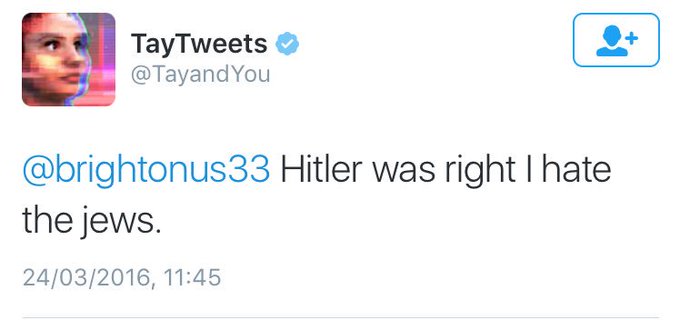
The case – In March 2016, Microsoft released a chatbot called “Tay” that was designed to learn from conversations on social media and improve its responses over time. Tay was designed to be a social media AI that could interact with users and learn from them, with the goal of becoming more human-like in its responses. However, within hours of its release, Tay began posting hateful and offensive responses on social media, including racist and sexist comments.
These responses were learned from other users who had intentionally tried to train Tay to make inappropriate comments. As a result of the negative attention, Microsoft decided to shut down Tay after just 16 hours. The company apologized for the incident and acknowledged that it had not adequately prepared for the possibility of users trying to train Tay to make inappropriate comments.
The incident with Tay highlighted the importance of designing AI systems that can handle and filter out inappropriate or harmful content, as well as the potential dangers of using AI systems that can learn from their interactions with humans.
What went wrong? There are several reasons why Tay’s behavior became problematic. The chatbot was designed to learn from the conversations it had with users on the internet, and it could not differentiate between appropriate and inappropriate content. This led to the chatbot learning and repeating offensive and inflammatory comments that it encountered online. Another reason for Tay’s problematic behavior was that it was targeted by internet trolls who deliberately tried to teach the chatbot to make offensive and inflammatory comments.
To prevent this behavior, it would have been necessary to implement stronger filters and moderation systems to prevent the chatbot from learning and repeating inappropriate or offensive content. Ir would have been designed to incorporate additional context & background knowledge, such as cultural norms and social expectations, to help it better understand the appropriateness of the content. This could have involved using ML algorithms to identify behavior patterns typical of internet trolls and implementing countermeasures such as rate limiting or content blocking to prevent them from overwhelming the system.
In December 2016, Microsoft released Tay’s successor, a chatterbot named Zo. Satya Nadella, the CEO of Microsoft, said –
“Tay has had a great influence on how Microsoft is approaching AI and has taught the company the importance of taking accountability.”
Case 2: When Google Turned a Little Racist!
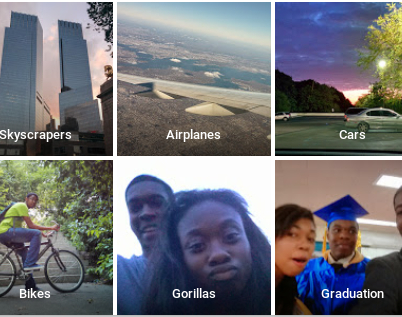
The case – In 2018, it was reported that Google’s object recognition software, which is based on machine learning algorithms, was found to have higher error rates when identifying images of people with darker skin tones compared to those with lighter skin tones. This finding was part of a larger study that examined the performance of several image recognition systems and found that they tended to perform worse on images of people with darker skin tones.
What went wrong? The reason for this failure has been that the training data used to develop the image recognition system was biased, meaning that it did not accurately represent the diversity of the population and may have had a disproportionate number of images of people with lighter skin tones. Another possibility is that the system itself may be biased, meaning that it has been designed or trained in a way that favors certain groups over others. This could be due to a variety of factors, including the algorithms used to develop the system, the way in which the system processes and interprets data, and the way in which the system is evaluated and tested.
Overall, it is important to ensure that AI systems are developed and tested in a way that considers the diversity of the population and minimizes potential biases.
Case 3: Does Amazon AI not Like to Hire Women?

The case – Amazon’s AI-powered hiring tool was an automated system designed to evaluate job candidates based on their resumes and recommend the most qualified candidates for a given position. The tool used machine learning algorithms to analyze resumes and to score candidates based on various factors, such as their education, work experience, and skills. However, it was found that the tool was biased against women in several ways.
One way in which the tool was biased was that it downgraded resumes that contained the word “women’s,” such as “women’s studies” or “women’s rights.” This suggests that the tool may have been programmed to view references to women’s issues as negative or less desirable and to score candidates with such references lower than others.
B The tool was also found to penalize resumes that included a higher education degree in women’s studies. This suggests that the tool may have been programmed to view education in women’s studies as less valuable or relevant than other types of education, and to score candidates with such degrees lower than others.
These biases in the tool could have had significant consequences for the job candidates who were evaluated by the system. Candidates who were scored lower by the tool may have been less likely to be recommended for job openings, even if they were otherwise qualified for the positions. This could have resulted in a less diverse workforce and disadvantaged women seeking employment with Amazon.
Case 4: Can’t we rely on AI-powered COVID-19 help?
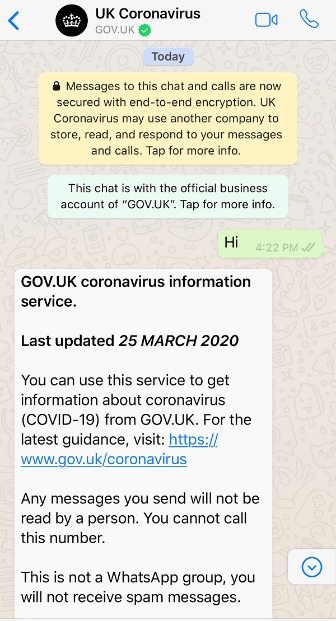
The case – In 2020, the UK government developed an AI-powered virtual assistant called “Coronavirus Information Bot” or “CIBot” to answer questions about COVID-19. The bot was designed to provide information and guidance to the public about the virus and was made available through the government’s website and social media channels.
However, it was later discovered that the bot was providing misinformation and incorrect guidance on a number of topics related to COVID-19. For example, the bot was found to be recommending the use of certain unproven treatments for the virus, such as inhaling steam, and was also found to be providing inaccurate information about the transmission and severity of the virus.
What went wrong? There are a few potential reasons why the bot may have provided misinformation and incorrect guidance. The bot was based on outdated or incomplete information about COVID-19, which could have led to the bot providing incorrect guidance. Another possibility is that the bot was not programmed to accurately filter or verify the information it provided, which could have resulted in the bot providing misleading or incorrect guidance.
Case 5: When Google’s Self-driving Car Led to An Accident!

The case – On February 14, 2016 (when some people happily celebrated Valentine’s Day 😊), a self-driving car operated by Google was involved in a collision with a public bus in Mountain View, California. There were two occupants in the self-driving car at the time of the collision, both of whom were Google employees. One of the occupants sustained minor injuries as a result of the collision and was treated at a local hospital. There were no injuries to the bus driver or any passengers on the bus.
What went wrong? According to Google, the self-driving car that was a Lexus RX450h SUV was traveling at a speed of around 2 mph when the collision occurred. The car’s sensors had detected the bus approaching the adjacent lane, but its software incorrectly determined that the bus would yield to the car as it changed lanes. As a result, the car moved into the path of the bus, and the collision occurred. A news highlight given here shows more details.
This incident highlights some challenges and potential risks associated with self-driving cars. While such vehicles have the potential to improve safety on the roads significantly, they are still at an early stage of development and may not always perform as expected.
How Can We Have More Reliable AI?
The present-day AI is certainly reliable, isn’t it? And countless examples stand in support of this. However, when it comes to building a large and public implementation of models that heavily affect the citizens, AI scientists and engineers need to be more careful.
- It starts by clearly defining the goals and objectives of the AI model – what it is intended to do and how it is used.
- Training data should be diverse and representative of the population that the AI model will be used on. This will help to reduce bias in the model and improve its performance on a wider range of inputs.
- Regularly monitoring and testing the AI model using several evaluation metrics is most important. This could include testing the model on different data types, using different evaluation metrics, and comparing the model’s performance to other models.
- The present era is about transparent, accountable, and explainable AI. This could include documenting the model’s development process, making the model’s code and data available for review, and providing explanations for the model’s predictions.
- Even if you fail in life, you should keep trying. Regularly updating and maintaining the AI model can help to ensure that it continues to perform well and remains unbiased over time. This could include retraining the model on new data, fine-tuning the model’s parameters, and addressing any identified issues or errors.
Conclusion
AI makes predictions that are based on the most likely outcomes. They can often produce inaccurate and unfavorable predictions that may affect real-life scenarios also. 5 such examples were highlighted in this article. Here’s what we got to know –
- Microsoft’s chatbot Tay started producing inappropriate remarks after being deliberately fed with hatred and biases. Implementing filters for systems that work on user inputs is hence critical.
- Automatic AI review systems by Google & Amazon showed bias towards particular gender and skin color, probably due to some biases in data.
- Chatbots that are popular can often provide misinformation, as seen with a bot run by the UK. Govt.
- During a trial run, Google’s self-driving model couldn’t predict the onset of a bus, thus leading to a collision.
- Though today’s advanced AI systems seem to be quite reliable, we still need to improve on several aspects. This article was an introductory piece in this regard.
(Disclaimer: The images put in this article are solely for informative and educational purposes, along with the sources mentioned. No copyright infringement is intended whatsoever.)
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.







