6 Practices to enhance the performance of a Text Classification Model
Introduction
A few months back, I was working on creating a sentiment classifier for Twitter data. After trying the common approaches, I was still struggling to get good accuracy on the results.
Text classification problems and algorithms have been around for a while now. They are widely used for Email Spam Filtering by the likes of Google and Yahoo, for conducting sentiment analysis of twitter data and automatic news categorization in google alerts.
However, while dealing with enormous amount of text data, model’s performance and accuracy becomes a challenge. The performance of a text classification model is heavily dependent upon the type of words used in the corpus and type of features created for classification. I used several practices to improve the results of my model.

In this article, I’ve illustrated the six best practices to enhance the performance and accuracy of a text classification model which I had used:
1. Domain Specific Features in the Corpus
For a classification problem, it is important to choose the test and training corpus very carefully. For a variety of features to act in the classification algorithm, domain knowledge plays an integral part.


For example, if the problem is “Sentiment Classification on social media data”, the training corpus should consist of the data from social sources like twitter and facebook.
On the other hand if the problem is “Sentiment Classification for news data”, the corpus should consist of data from news sources. This is because the vocabulary of a corpus varies with domains. Social Media contains a lot of slangs and improper keywords like “awsum, lol, gooood” etc which are absent in any of the formal corpus such as news, blogs etc.
Let’s take an example of a naive bayes classification problem where the task is to classify the statements into two Classes: “Class A and Class B”. We’ve training data corpus and a test data corpus. As mentioned here, the training corpus should contain the features from relevant corpus. Therefore, training corpus should consist of data points such as:
2. Use An Exhaustive Stopword List
Stopwords are defined as the most commonly used words in a corpus. Most commonly used stopwords are “a, the, of, on, … etc”. These words are used to define the structure of a sentence. But, are of no use in defining the context. Treating these type of words as feature words would result in poor performance in text classification. These words can be directly ignored from the corpus in order to obtain a better performance. Apart from language stopwords, There are some other supporting words as well which are of lesser importance than any other terms. These includes:

Language Stopwords – a, of, on, the … etc
Location Stopwords – Country names, Cities names etc
Time Stopwords – Name of the months and days (january, february, monday, tuesday, today, tomorrow …) etc
Numerals Stopwords – Words describing numerical terms ( hundred, thousand, … etc)
After removal of these entities from the test data, test data would be reformed to following:
test_data = [
(' luv phones.', 'Class A'),
(' amaaaazingg company!', 'Class A'),
(' feeling very gooood about features lol.', 'Class A'),
(' bestest phones.', 'Class A'),
(" awesomee player", 'Class A'),
(' not like phone #apple ', 'Class B'),
(' tired stuff.', 'Class B'),
(' worst fears! . check out here: http://goo.gl/qdjk3rf ', 'Class B'),
(' boss lives, horrible.', 'Class B')
x]
3. Noise Free Corpus
In most of the data science problems, it is recommended to undertake a classification algorithm on a cleaned corpus rather than a noisy corpus. Noisy corpus refers to unimportant entities of the text such as punctuations marks, numerical values, links and urls etc. Removal of these entities from the text would increase the accuracy, because size of sample space of possible features set decreases.
Yet, it becomes essential to note that, these entities should only be removed if the classification problem does not use these entities. For example – emoticons such as :), :P, 🙁 are important for sentiment classification but may not be important for other text classifications.
After eliminating the noisy entities like hashtags, url text, the training corpus would look like:
test_data = [
('luv phones', 'Class A'),
('amaaaazingg company', 'Class A'),
('feeling very gooood about features lol', 'Class A'),
('bestest phones', 'Class A'),
("awesomee player", 'Class A'),
('not like phone apple ', 'Class B'),
('tired stuff', 'Class B'),
('worst fears check out here', 'Class B'),
('boss lives horrible', 'Class B')
]
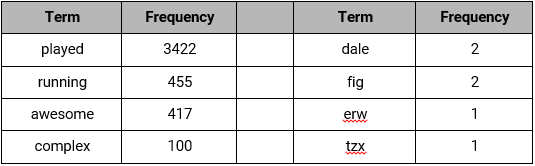
4. Eliminating features with extremely low frequency
Keywords which occur in lesser frequency in the corpus usually does not play a role in text classification. One can get rid of these low occurring features, resulting in better performance of the model. For example – if the frequency counts of words of a corpus looks like the following:It is clear that terms “fig” and “dale” have occurred in low frequency as compared to other terms. Hence, if we choose a threshold of 10, all keywords with less frequency can be ignored, resulting in good accuracy.
5. Normalized Corpus
Words are the integral part of any classification technique. However, these words are often used with different variations in the text depending on their grammar (verb, adjective, noun, etc.). It is always a good practice to normalize the terms to their root forms. This technique is known as Lemmatization. For example, the words:
- Playing
- Player
- Plays
- Play
- Players
- Played
All can be normalized down to the word “Play” as far as the classifier is concerned. Performance will be good when there is single feature for ten variations rather than ten features for each variations.
test_data = [
('luv phone', 'Class A'),
('amazing company', 'Class A'),
('feeling very good about feature lol', 'Class A'),
('best phone', 'Class A'),
("awesome player", 'Class A'),
('not like phone apple', 'Class B'),
('tired stuff', 'Class B'),
('worst fear check out here', 'Class B'),
('boss live horrible', 'Class B')
]
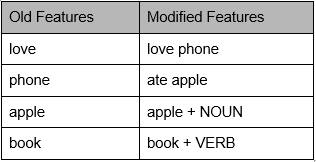
6. Use Complex Features: n-grams and part of speech tags
In some cases, features as the combination of words provides better significance rather than considering single words as features. Combination of N words together are called N-grams. It is known that Bigrams are the most informative N-Gram combinations. Adding bigrams to feature set will improve the accuracy of text classification model.
Similarly considering Part of Speech tags combined with with words/n-grams will give an extra set of feature space. also increase the classifications. For example –
it’s better to train the model, such that word “book” when used as NOUN means “book of pages”, when used as VERB means to “book a ticket or something else”.
End Notes
In this article, we discussed few practices to improve the accuracy of a text classifier model. These gave me an improvement of ~10% – 20% in accuracy depending on the use case.
This is obviously not a complete list, but it provides a nice introduction for optimization of text classification algorithms. If you feel there are any other techniques which I have missed, feel free to share in comments section below.
If you like what you just read & want to continue your analytics learning, subscribe to our emails, follow us on twitter or like our facebook page.
Shivam Bansal is a data scientist with exhaustive experience in Natural Language Processing and Machine Learning in several domains. He is passionate about learning and always looks forward to solving challenging analytical problems.








Hi Shivam, Good article. I have two questions: 1. Is Lemmatization and stemming of words are same? 2. I would like to know your experience with stemming of the words. Does that really improves the performance? I was trying to use stemdocument function in R. For me having the function didnt reduce the accuracy of the model, however if you see the words like organization has been stemmed to organ. Which is wrong in my case. Hence i am forced to remove the stemming from my work. 3. How point number 4 discussed above( removing the less frequency words) and TF-IDF are related / unrelated? In my understanding IDF reduces the high frequency words. If this understanding correct, is the point no 4 and IDF are opposite in meaning? Kindly clarify. Thanks in advance.
Hi Karthikeyan 1. Stemming and Lemmatization are two different processes.: Stemming is much simpler process in which, suffixes are removed from a word. It involves various if - else rules and conditions, to convert the word to a root form. Lemmatization on the other hand, is more advanced approach, which converts the word into its lemma. It takes care of grammar, vocabulary and dictionary importance of a word while the conversion. for example: in Stemming: "driving" will be reduced to "driv" but in lemmatization it will be reduced to "drive" 2. As per my experience with text mining, stemming is not a good tool for enhancing the performance. As stemming results in loss of some information. 3. Point 4 and TF-IDF are somewhat similar in practical sense. IDF also does the same thing by giving less priority to low frequency words.
Thanks for the clarifications. Well explained !!!
Hi Shivam The article is really good you put all the models in one place providing a really good insight of classification. I did the news classification but for that i have to perform a lot of research and their are little number of articles which provide such a good and point-to-point insight on this topic. Appreciate your work and time to write this article. Keep it up mate.
Hi Hemant, Thanks ! I will keep posting the useful articles.
Very nice summation, which I found useful. However, I have reservations about the stop-word lists, which I prefer to derive in an empirical, task-specific way having found the chi-square test a great way to simultaneously deselect both popular but useless and excessively rare words. I have found both numbers and place names with useful predictive value in this way. I am reminded of the usefulness of bi-grams, which I have neglected. Thank you!
Hi Shivam, Thanks for your inputs on this. I have very specific questions: 1) I am from a CRM domain in the automotive sector where we have a lot of unstructured survey data coming our way. 1st question is- Is there a domain specific dictionary that can be used here to map positive & negative words for sentiment analysis? If yes, please help me with that. 2) How do we take care of words like "Not bad" and "Not good" while working on sentiment analysis. Not bad essentially means good but will be given a score of negative.. 3) How do we take care of the words lying in the vicinity of important words. eg. "was not helpful" and "very helpful" should be given negative & positive score as what is important here is the "not" & "very" which is surrounding the word "helpful". Some call this approach as "opinion mining". How does it happen in r & take care of such scenarios. Your help will be really appreciated.
@Shantanu : You need to create multiple other dicts along with positive and negative words, which will essentially take care of "negator" words. Check for one-two words before each positive or negative word before providing the sentiment weight. E.g Negator words - no, not, never etc Sentiment enhancer words - very, too etc Sentiment reducer words - little, moderate etc For every positive or negative words, check their previous word and Flip the sentiment weight if previous word - Negator word ( “Not bad” and “Not good”) Increase sentiment weight if previous word - Sentiment enhancer word ( “very helpful” ) Decrease sentiment weight if previous word - Sentiment reducer word You can still write a more complex rule to take care other scenarios like 1. Not excellent - still good 2. Not up to the mark - but not negative 3. Better than words - still negative
hi, i have very lttle corpus of mutual fund corpus on which i wana do sentimentl analysis. I tried normal lexicon and Naive bayes on unigram but didnot get enough accuracy. As i am not having much data so that i can train well and get reults. i am training on movie corpus and validating on mutual fund 25 rows. somebody suggested me to get ngrams and den find its POS and then calculate sentiment scores based on wordnet. Can you help me in providing r code on this pls. I am not able to get it anywhere. also how to do this. like after getting ngrams how to find POS id and then sentiment score based on sentinet
How can I apply lemmatization on a Corpus instead of stemming? Can you please explain with a sample code in R.
Hi Ashay, Yes you can apply lemmatization on corpus. You can use "tm" package in R. Please refer this link - https://cran.r-project.org/web/packages/tm/tm.pdf
Hi Shivam, Great article! Pinpointed clearly issues and improvements. Have one question on the accuracy: how do you measure it? Thanks in advance Conce
Hi, Thank you for this article. One improvement I would suggest is being careful when you remove words and using n-grams, since you might be creating non-existent n-grams.