Introduction
What is one of the most important and core concepts of statistics that enables us to do predictive modeling, and yet it often confuses aspiring data scientists? Yes, I’m talking about the central limit theorem (CLT). It is a powerful statistical concept that every data scientist MUST know. Now, why is that?
Well, the central limit theorem (CLT) is at the heart of hypothesis testing – a critical component of the data science and machine learning lifecycle. That’s right, the idea that lets us explore the vast possibilities of the data we are given springs from CLT. It’s actually a simple notion to understand, yet most data scientists flounder at this question during interviews.
In this beginner’s tutorial, we will understand the concept of the Central Limit Theorem (CLT) in this article. We’ll see why it’s important and where it’s used, and learn how to apply it in R and python.
Learning Objectives
- In this tutorial, we will learn about the Central limit theorem and conditions of the central limit theorem.
- We will also learn about the Central limit theorem assumptions, significance, and implementation in R language.
Table of contents
- What is Central Limit Theorem?
- Understanding CLT with Example
- Central Limit Theorem Formula
- Distribution of the Variable in the Population
- Formally Defining the Central Limit Theorem
- Conditions of the Central Limit Theorem
- Significance of the Central Limit Theorem
- Practical Applications of CLT
- Assumptions Behind the Central Limit Theorem
- What Is Standard Error?
- Implementing the Central Limit Theorem in R
- Frequently Asked Questions?
What is Central Limit Theorem?
The central limit theorem states that when the sample size is large, the distribution of the sample mean will be normal. This holds true regardless of the original distribution of the population, be it normal, Poisson, binomial, or any other type.
Unpacking the meaning of that complex definition can be difficult. That’s the topic of this post! I’ll walk you through the various aspects of the central limit theorem (CLT) definition and show you why it is vital in statistics.
Measure of Central Tendency
The measure of central tendency (central location/measures of center) is the summary measure that tries to explain the whole set of data with a single value that represents the middle or center of a distribution.
Understanding CLT with Example
Let’s understand the central limit theorem with the help of an example. This will help you intuitively grasp how CLT works underneath.
Consider that there are 15 sections in the science department of a university, and each section hosts around 100 students. Our task is to calculate the average weight of students in the science department. Sounds simple, right?
The approach I get from aspiring data scientists is to simply calculate the average:
- First, measure the weights of all the students in the science department.
- Add all the weights.
- Finally, divide the total sum of weights by the total number of students to get the average.
But what if the size of the data is humongous? Does this approach make sense? Not really – measuring the weight of all the students will be a very tiresome and long process. So, what can we do instead? Let’s look at an alternate approach.
- First, draw groups of students at random from the class. We will call this a sample. We’ll draw multiple samples, each consisting of 30 students.

- Now, calculate the individual mean of these samples.
- Then, calculate the mean of these sample means.
- This value will give us the approximate mean weight of the students in the science department.
- Additionally, the histogram of the sample mean weights of students will resemble a bell curve (or normal distribution).
Central Limit Theorem Formula
The shape of the sampling distribution of the mean can be determined without repeatedly sampling a population. The parameters are based on the population:

Distribution of the Variable in the Population
Part of the definition for the central limit theorem states, “regardless of the variable’s distribution in the population.” This part is easy! In a population, the values of a variable can follow different probability distributions. These distributions can range from normal, left-skewed, right-skewed, and uniform, among others.
- Normal: It is also known as the Gaussian distribution. It is symmetric about the mean, showing that data near the mean are more frequent in occurrence than data far from the mean.
- Right-Skewed: It is also known as the positively skewed. Most of the data lie to the right/positive side of the graph peak.
- Left-Skewed: Most of the data lies on the left side of the graph at its peak than on its right.
- Uniform: It is a condition when the data is equally distributed across the graph.
- This part of the definition refers to the distribution of the variable’s values in the population from which you draw a random sample.
The central limit theorem applies to almost all types of probability distributions, but there are exceptions. For example, the population must have a finite variance. That restriction rules out the Cauchy distribution because it has an infinite variance.
Additionally, the central limit theorem applies to independent, identically distributed variables. In other words, the value of one observation does not depend on the value of another observation. And the distribution of that variable must remain constant across all measurements.
Formally Defining the Central Limit Theorem
Let’s put a formal definition to CLT:
Given a dataset with unknown distribution (it could be uniform, binomial or completely random), the sample means will approximate the normal distribution.
These samples should be sufficient in size. The distribution of sample means, calculated from repeated sampling, will tend to normality as the size of your samples gets larger.

The central limit theorem has a wide variety of applications in many fields and can be used with python and its libraries like numpy, pandas, and matplotlib. Let us look at them in the next section.
Conditions of the Central Limit Theorem
The central limit theorem states that the sampling distribution of the mean will always follow a normal distribution under the following conditions:
- The sample size is sufficiently large. This condition is usually met if the size of the sample is n ≥ 30.
- The samples are independent and identically distributed, i.e., random variables. The sampling should be random.
- The population’s distribution has a finite variance. The central limit theorem doesn’t apply to distributions with infinite variance.
Significance of the Central Limit Theorem
The central limit theorem has both, statistical significance as well as practical applications. Isn’t that the sweet spot we aim for when we’re learning a new concept? As a data scientist, you should be able to deeply understand this theorem. You should be able to explain it and understand why it’s so important. Criteria for it to be valid and the details about the statistical inferences that can be made from it. We’ll look at both aspects to gauge where we can use them.
Statistical Significance of CLT

Analyzing data involves statistical methods like hypothesis testing and constructing confidence intervals. These methods assume that the population is normally distributed. In the case of unknown or non-normal distributions, we treat the sampling distribution as normal according to the central limit theorem.
If we increase the samples drawn from the population, the standard deviation of sample means will decrease. This helps us estimate the mean of the population much more accurately. Also, the sample mean can be used to create the range of values known as a confidence interval (that is likely to consist of the population mean).
Practical Applications of CLT

The central limit theorem has many applications in different fields.
Political/election polls are prime CLT applications. These polls estimate the percentage of people who support a particular candidate. You might have seen these results on news channels that come with confidence intervals. The central limit theorem helps calculate the same.
Confidence interval, an application of CLT, is used to calculate the mean family income for a particular region.
Assumptions Behind the Central Limit Theorem
Before we dive into the implementation of the central limit theorem, it’s important to understand the assumptions behind this technique:
- The data must follow the randomization condition. It must be sampled randomly
- Samples should be independent of each other. One sample should not influence the other samples
- Sample size should be not more than 10% of the population when sampling is done without replacement
- The sample size should be sufficiently large. Now, how will we figure out how large this size should be? Well, it depends on the population. When the population is skewed or asymmetric, the sample size should be large. If the population is symmetric, then we can draw small samples as well.
In general, a sample size of 30 is considered sufficient when the population is symmetric.
The mean of the sample means is denoted as:
µ X̄ = µ
where,
- µ X̄ = Mean of the sample means
- µ= Population mean
And the standard deviation of the sample mean is denoted as:
σ X̄ = σ/sqrt(n)
where,
- σ X̄ = Standard deviation of the sample mean
- σ = Standard deviation of the population
- n = sample size
And that’s it for the concept behind the central limit theorem. Time to fire up RStudio and dig into CLT’s implementation!
The central limit theorem has important implications in applied machine learning. This theorem does inform the solution to linear algorithms such as linear regression, but not for complex models like artificial neural networks(deep learning) because they are solved using numerical optimization methods.
What Is Standard Error?
It is also an important term that spurs from the sampling distribution, and it closely resembles the Central limit theorem. The standard error. The SD of the distribution is formed by sample means.
Standard error is used for almost all statistical tests. This is because it is a probabilistic measure that shows how well you approximated the truth. It decreases when the sample size increases. The bigger the samples, the better the approximation of the population.
Implementing the Central Limit Theorem in R
Are you excited to see how we can code the central limit theorem in R? Let’s dig in then.
Understanding the Problem Statement
A pipe manufacturing organization produces different kinds of pipes. We are given the monthly data of the wall thickness of certain types of pipes. You can download the data here.
The organization wants to analyze the data by performing hypothesis testing and constructing confidence intervals to implement some strategies in the future. The challenge is that the distribution of the data is not normal.
Note: This analysis works on a few assumptions and one of them is that the data should be normally distributed.
Solution Methodology
The central limit theorem will help us get around the problem of this data where the population is not normal. Therefore, we will simulate the CLT on the given dataset in R step-by-step. So, let’s get started.
First, import the CSV file in R and then validate the data for correctness:
Output:
#Count of Rows and columns
9000 1
#View top 10 rows of the dataset
Wall.Thickness
1 12.35487
2 12.61742
3 12.36972
4 13.22335
5 13.15919
6 12.67549
7 12.36131
8 12.44468
9 12.62977
10 12.90381
#View last 10 rows of the dataset
Wall.Thickness
8991 12.65444
8992 12.80744
8993 12.93295
8994 12.33271
8995 12.43856
8996 12.99532
8997 13.06003
8998 12.79500
8999 12.77742
9000 13.01416
Next, calculate the population mean and plot all the observations of the data.
Output:
#Calculate the population mean
[1] 12.80205
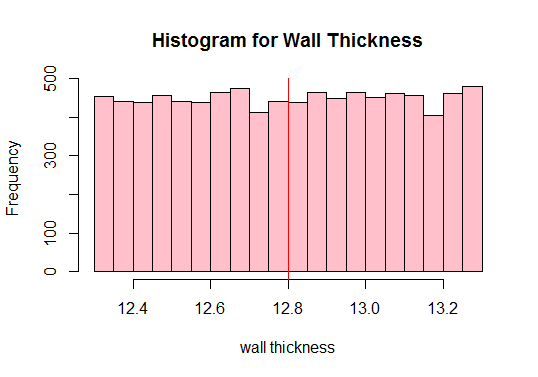
See the red vertical line above? That’s the population mean. We can also see from the above plot that the population is not normal, right? Therefore, we need to draw sufficient samples of different sizes and compute their means (known as sample means). We will then plot those sample means to get a normal distribution.
In our example, we will draw m sample of size n sufficient samples of size 10, calculate their means, and plot them in R. I know that the minimum sample size taken should be 30, but let’s just see what happens when we draw 10:

Now, we know that we’ll get a very nice bell-shaped curve as the sample sizes increase. Let us now increase our sample size and see what we get:

Here, we get a good bell-shaped curve, and the sampling distribution approaches the normal distribution as the sample sizes increase. Therefore, we can consider the sampling distributions as normal, and the pipe manufacturing organization can use these distributions for further analysis.
You can also play around by taking different sample sizes and drawing a different number of samples. Let me know how it works out for you!
Conclusion
The central limit theorem is quite an important concept in statistics and, consequently, data science, which also helps in understanding other properties such as skewness and kurtosis. I cannot stress enough how critical it is to brush up on your statistics knowledge before getting into data science or even sitting for a data science interview.
I recommend taking the Introduction to Data Science course – it’s a comprehensive look at statistics before introducing data science.
Key Takeaways
- The central limit theorem says that the sampling distribution of the mean will always be normally distributed until the sample size is large enough.
- Sampling should be random. The samples should not relate to one another. One sample shouldn’t affect the others.
Frequently Asked Questions?
Q1. Is there a formula for central limit theorem?
A. Yes, the central limit theorem (CLT) does have a formula. It states that the sampling distribution of the sample mean approaches a normal distribution as the sample size increases, regardless of the shape of the population distribution.
Q2. What are the three points of the central limit theorem?
A. The three key points of the central limit theorem are:
1. Regardless of the shape of the population distribution, the sampling distribution of the sample mean will approach a normal distribution as the sample size increases.
2. The mean of the sampling distribution will be equal to the population mean.
3. The standard deviation of the sampling distribution (also known as the standard error) decreases as the sample size increases.
Q3. Why central limit theorem is called central?
A. The central limit theorem is called “central” because it is fundamental in statistics and serves as a central pillar for many statistical techniques. It is central in the sense that it allows statisticians to make inferences about population parameters based on sample statistics, even when the population distribution is unknown or non-normal.
Q4. What is central limit type theorem?
A. A central limit type theorem is a generalization or extension of the classical central limit theorem to situations where the conditions of the classical CLT may not hold exactly. These theorems provide conditions under which the distribution of a sum or average of independent and identically distributed random variables approaches a normal distribution, even if the variables themselves are not identically distributed or if they have heavy-tailed distributions.








please sir, can you explain this using python. i will appreciate it sir. moreso will love you to keep explaining core statistics for data science and machine learning this way sir
Hello, We will try to come up with the same concept using python. Also, for more posts on core statistics for data science stay tuned to Analytics Vidhya.
Ver good, thanks
The code in last 3 histograms looks like it is missing 30, 50 and 100 in the sample function? Good post in general.
Hello, Thanks for the feedback. Necessary changes have been made.
Very well explained. The beauty of using the simple language is that anyone from any background can understand the concept.
Hello, Thanks for the appreciation.
Great stuff. Very helpful. Mean income for a local authority jurisdiction is a CTL application!
Hi, Thanks for the feedback.
Very well explained and most importantly in the simplest of words. I have a few questions. Firstly if I draw samples without replacement then that causes the samples to be dependent on each other, doesn't this violate your second assumption? Second, you have taken 9000 samples which will cover almost all data points, hence what is the benefit of sampling in this case ? Continuing the second question, what is the minimum or the required number of samples that can effectively state the Central Limit Theorem? Thanks!!
Hello Ayush; 1. In the case of sampling without replacement from a finite population, the assumption of independence holds when n is small by comparison to the size of the population or it basically means that if the sample/population ratio is small enough (e.g. 10%), sampling without replacement may (approximately) be treated like sampling with replacement. In my case, I took sampling with replacement. 2. Large samples should be taken in the case of the central limit theorem. Here I took 9000 samples so that the mean of the sample means approaches close to the population mean. You can also take 5000 samples. Basically, sample size and number of samples should be selected in a way that the means of sampling distribution approaches normality. Thanks
Very well explained and am happy that i have learned some thing new today. Thank you so much.
Your concept is well explained to a layman's understanding. If I am using food samples eg tubers, from a total of 30kg, 10% will be 3kg. How do I apply CLT to obtain the actual number of tubers I am to use as my sample size to carry out different analysis
This is an interesting topic that I have not encountered before. Can you provide more information on the Central Limit Theorem and its significance in statistics?
crisply written. its clear and easily understandable