Top 7 Machine Learning Github Repositories for Data Scientists
Introduction
If I had to pick one platform that has single-handedly kept me up-to-date with the latest developments in data science and machine learning – it would be GitHub. The sheer scale of GitHub, combined with the power of super data scientists from all over the globe, make it a must-use platform for anyone interested in this field.
Can you imagine a world where machine learning libraries and frameworks like BERT, StanfordNLP, TensorFlow, PyTorch, etc. weren’t open sourced? It’s unthinkable! GitHub has democratized machine learning for the masses – exactly in line with what we at Analytics Vidhya believe in.
This was one of the primary reasons we started this GitHub series covering the most useful machine learning libraries and packages back in January 2018.

Along with that, we have also been covering Reddit discussions we feel are relevant for all data science professionals. This month is no different. I have curated the top five discussions from May which focus on two things – machine learning techniques and career advice from expert data scientists.
You can also go through the GitHub repositories and Reddit discussions we’ve covered throughout this year:
Top GitHub Repositories (May 2019)

InterpretML by Microsoft – Machine Learning Interpretability

Interpretability is a HUGE thing in machine learning right now. Being able to understand how a model produced the output that it did – a critical aspect of any machine learning project. In fact, we even did a podcast with Christoph Molar on interpretable ML that you should check out.
InterpretML is an open-source package by Microsoft for training interpretable models and explaining black-box systems. Microsoft put it best when they explained why interpretability is essential:
- Model debugging: Why did my model make this mistake?
- Detecting bias: Does my model discriminate?
- Human-AI cooperation: How can I understand and trust the model’s decisions?
- Regulatory compliance: Does my model satisfy legal requirements?
- High-risk applications: Healthcare, finance, judicial, etc.
Interpreting the inner working of a machine learning model becomes tougher as the complexity increases. Have you ever tried to take apart and understand a multiple model ensemble? It takes a lot of time and effort to do it.
We can’t simply go to our client or leadership with a complex model without being able to explain how it produced a good score/accuracy. That’s a one-way ticket back to the drawing board for us.
The folks at Microsoft Research have developed the Explainable Boosting Machine (EBM) algorithm to help with interpretability. This EBM technique has both high accuracy and intelligibility – the holy grail.
Interpret ML isn’t limited to just using EBM. It also supports algorithms like LIME, linear models, decision trees, among others. Comparing models and picking the best one for our project has never been this easy!
You can install InterpretML using the below code:
pip install numpy scipy pyscaffold pip install -U interpret
Tensor2Robot (T2R) by Google Research
Google Research makes another appearance in our monthly Github series. No surprises – they have the most computational power in the business and they’re putting it to good use in machine learning.

Their latest open source released, called Tensor2Robot (T2R) is pretty awesome. T2R is a library for training, evaluation and inference of large-scale deep neural networks. But wait – it has been developed with a specific goal in mind. It is tailored for neural networks related to robotic perception and control
No prizes for guessing the deep learning framework on which Tensor2Robot is built. That’s right – TensorFlow. Tensor2Robot is used within Alphabet, Google’s parent organization.
Here are a couple of projects implemented using Tensor2Robot:
Generative Models in TensorFlow 2
TensorFlow 2.0, the most awaited TensorFlow (TF) version this year, officially launched last month. And I couldn’t wait to get my hands on it!

This repository contains TF implementations of multiple generative models, including:
- Generative Adversarial Networks (GANs)
- Autoencoder
- Variational Autoencoder (VAE)
- VAE-GAN, among others.
All these models are implemented on two datasets you’ll be pretty familiar with – Fashion MNIST and NSYNTH.
The best part? All of these implementation are available in a Jupyter Notebook! So you can download it and run it on your own machine or export it to Google Colab. The choice is yours and TensorFlow 2.0 is right here for you to understand and use.
STUMPY – Time Series Data Mining
![]()
A time series repository! I haven’t come across a new time series development in quite a while.
STUMPY is a powerful and scalable library that helps us perform time series data mining tasks. STUMPY is designed to compute a matrix profile. I can see you wondering – what in the world is a matrix profile? Well, this matrix profile is a vector that stores the z-normalized Euclidean distance between any subsequence within a time series and its nearest neighbor.
Below are a few time series data mining tasks this matrix profile helps us perform:
- Anomaly discovery
- Semantic segmentation
- Density estimation
- Time series chains (temporally ordered set of subsequence patterns)
- Pattern/motif (approximately repeated subsequences within a longer time series) discovery
Use the below code to install it directly via pip:
pip install stumpy
MeshCNN in PyTorch
MeshCNN is a general-purpose deep neural network for 3D triangular meshes. These meshes can be used for tasks such as 3D-shape classification or segmentation. A superb application of computer vision.
The MeshCNN framework includes convolution, pooling and unpooling layers which are applied directly on the mesh edges:
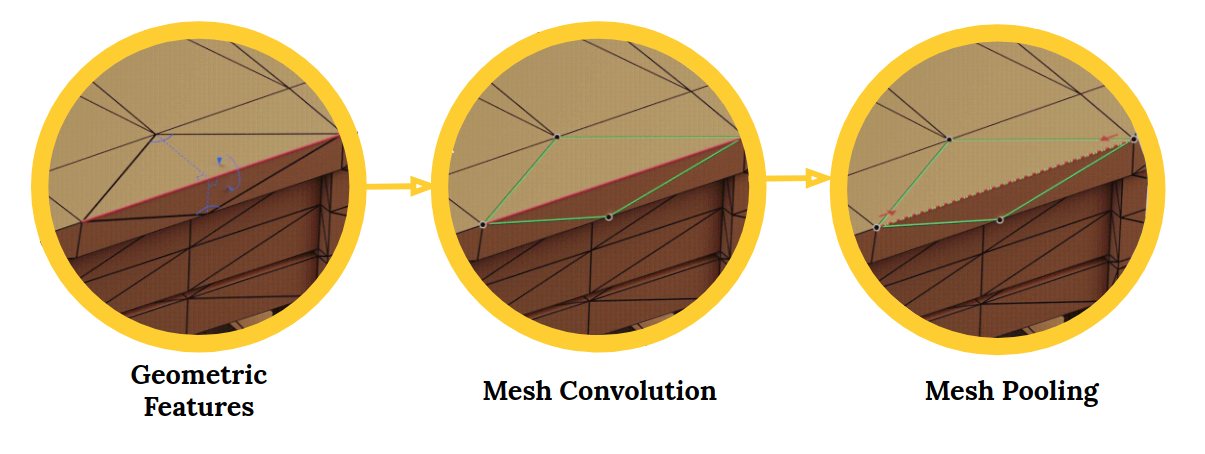
Convolutional Neural Networks (CNNs) are perfect for working with image and visual data. CNNs have become all the rage in recent times with a boom of image related tasks springing up from them. Object detection, image segmentation, image classification, etc. – these are all possible thanks to the advancement in CNNs.
3D deep learning is attracting interest in the industry, including fields like robotics and autonomous driving. The problem with 3D shapes is that they are inherently irregular. This makes operations like convolutions difficult an challenging.
This is where MeshCNN comes into play. From the repository:
Meshes are a list of vertices, edges and faces, which together define the shape of the 3D object. The problem is that every vertex has a different # of neighbors, and there is no order.
If you’re a fan of computer vision and are keen to learn or apply CNNs, this is the perfect repository for you. You can learn more about CNNs through our articles:
- A Comprehensive Tutorial to learn Convolutional Neural Networks from Scratch
- Architecture of Convolutional Neural Networks (CNNs) Demystified
Awesome Decision Tree Research Papers

Decision Tree algorithms are among the first advanced techniques we learn in machine learning. Honestly, I truly appreciate this technique after logistic regression. I could use it on bigger datasets, understand how it worked, how the splits happened, etc.
I personally love this repository. It is a treasure trove for data scientists. The repository contains a collection of papers on tree based algorithms, including decision, regression and classification trees. The repository also contains the implementation of each paper. What more could we ask for?
TensorWatch by Microsoft Research
Have you ever wondered how your machine learning algorithm’s training process works? We write the code, some complication happens behind the scenes (the joy of programming!), and we get the results.
Microsoft Research have come up with a tool called TensorWatch that enables us to see real-time visualizations of our machine learning model’s training process. Incredible! Check out a snippet of how TensorWatch works:

TensorWatch, in simple terms, is a debugging and visualization tool for deep learning and reinforcement learning. It works in Jupyter notebooks and enables us to perform many other customized visualizations of our data and our models.
Reddit Discussions
![]()
Let’s spend a few moments checking out the most awesome Reddit discussions related to data science and machine learning from May, 2019. There’s something here for everyone, whether you’re a data science enthusiast or practitioner. So let’s dig in!
Which Skills should a PhD student have if he/she wants to work in the industry?
This is a tough nut to crack. The first question is whether you should actually opt for a Ph.D ahead of an industry role. And then if you did opt for one, then what skills should you pick up to make your industry transition easier?
I believe this discussion could be helpful in decoding one of the biggest enigmas in our career – how do we make a transition from one field or line of work to another? Don’t just look at this from the point of view of a Ph.D student. This is very relevant for most of us wanting to get that first break in machine learning.
I strongly encourage you to go through this thread as so many experienced data scientists have shared their personal experiences and learning.
Neural nets typically contain smaller “sub networks” that can often learn faster – MIT
Recently, a research paper was released expanding on the headline of this thread. The paper explained the Lottery Ticket Hypothesis in which a smaller sub-network, also known as a winning ticket, could be trained faster as compared to a larger network.
This discussion focuses on this paper. To read more about the Lottery Ticket Hypothesis and how it works, you can refer to my article where I break down this concept for even beginners to understand:
Decoding the Best Papers from ICLR 2019 – Neural Networks are Here to Rule
Does anybody else feel overwhelmed looking at how much there is to learn?
I picked this discussion because I can totally relate to it. I used to think – I’ve learned so much, and yet there is so much more left. Will I ever become an expert? I made the mistake of looking just at the quantity and not the quality of what I was learning.
With the continuous and rapid advancement technology, there will always be a LOT to learn. This thread has some solid advice on how you can set priorities, stick to them, and focus on the task at hand rather than trying to become a jack of all trades.
End Notes
I had a lot of fun (and learning) putting together this month’s machine learning GitHub collection! I highly recommend bookmarking both these platforms and regularly checking them. It’s a great way to stay up to date with all that’s new in machine learning.
Or, you can always come back each month and check out our top picks. 🙂
If you think I’ve missed any repository or any discussion, comment below and I’ll be happy to have a discussion on it!










great work that provides great help. waiting for more updates.
Interesting article Career fairs are very helpful when you need to know about career services and choices. Thank you for sharing
Great piece of insight