Overview
- Learn how to build your own text generator in Python using OpenAI’s GPT-2 framework
- GPT-2 is a state-of-the-art NLP framework – a truly incredible breakthrough
- We will learn how it works and then implements our own text generator using GPT-2
Introduction
“The world’s best economies are directly linked to a culture of encouragement and positive feedback.”
Can you guess who said that? It wasn’t a President or Prime Minister. It certainly wasn’t a leading economist like Raghuram Rajan. All out of guesses?
This quote was generated by a machine! That’s right – a Natural Language Processing (NLP) model trained on OpenAI’s GPT-2 framework came up with that very real quote. The state of machine learning right now is on another level entirely, isn’t it?
In the midst of what is truly a golden era in NLP, OpenAI’s GPT-2 has remoulded the way we work with text data. Where ULMFiT and Google’s BERT eased open the door for NLP enthusiasts, GPT-2 has smashed it in and made it so much easier to work on NLP tasks – primarily text generation.
We are going to use GPT-2 in this article to build our own text generator. Here’s a taste of what we’ll be building:
Excited? Then let’s get into the article. We’ll first understand the intuition behind GPT-2 and then dive straight into Python to build our text generation model.
If you’re an avid NLP follower, you’ll love the below guides and tutorials on the latest developments in NLP:
- 8 Excellent Pretrained Models to get you Started with Natural Language Processing (NLP)
- How do Transformers Work in NLP? A Guide to the Latest State-of-the-Art Models
- Introduction to PyTorch-Transformers: An Incredible Library for State-of-the-Art NLP (with Python code)
- Introduction to StanfordNLP: An Incredible State-of-the-Art NLP Library for 53 Languages (with Python code)
Table of Contents
- What’s New in OpenAI’s GPT-2?
- How to Setup the Environment for GPT-2?
- Implementing GPT-2 in Python to Build our own Text Generator
What’s New in OpenAI’s GPT-2 Framework?
Natural Language Processing (NLP) has evolved at a remarkable pace in the past couple of years. Machines are now able to understand the context behind sentences – a truly monumental achievement when you think about it.
Developed by OpenAI, GPT-2 is a pre-trained language model which we can use for various NLP tasks, such as:
- Text generation
- Language translation
- Building question-answering systems, and so on.
Language Modelling (LM) is one of the most important tasks of modern Natural Language Processing (NLP). A language model is a probabilistic model which predicts the next word or character in a document.

GPT-2 is a successor of GPT, the original NLP framework by OpenAI. The full GPT-2 model has 1.5 billion parameters, which is almost 10 times the parameters of GPT. GPT-2 give State-of-the Art results as you might have surmised already (and will soon see when we get into Python).
The pre-trained model contains data from 8 million web pages collected from outbound links from Reddit. Let’s take a minute to understand how GPT-2 works under the hood.
The Architecture
The architecture of GPT-2 is based on the very famous Transformers concept that was proposed by Google in their paper “Attention is all you need”. The Transformer provides a mechanism based on encoder-decoders to detect input-output dependencies.
At each step, the model consumes the previously generated symbols as additional input when generating the next output.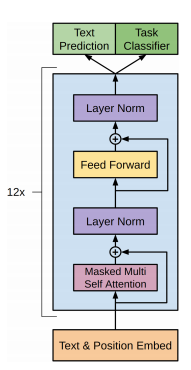
GPT-2 has only a few architecture modification besides having many more parameters and Transformers layers:
- The model uses larger context and vocabulary size
- After the final self-attention block, an additional normalization layer is added
- Similar to a residual unit of type “building block”, layer normalization is moved to the input of each sub-block. It has batch normalization applied before weight layers, which is different from the original type “bottleneck”
“GPT-2 achieves state-of-the-art scores on a variety of domain-specific language modeling tasks. Our model is not trained on any of the data specific to any of these tasks and is only evaluated on them as a final test; this is known as the “zero-shot” setting. GPT-2 outperforms models trained on domain-specific data sets (e.g. Wikipedia, news, books) when evaluated on those same data sets.” – Open AI team.
Four models with different parameters are trained to cater different scenarios:
GPT-2 has the ability to generate a whole article based on small input sentences. This is in stark contrast to earlier NLP models that could only generate the next word, or find the missing word in a sentence. Essentially, we are dealing in a whole new league.
Here’s how GPT-2 squares up against other similar NLP models:
| Base model | pre-training | Downstream tasks | Downstream model | Fine-tuning | |
|---|---|---|---|---|---|
| GPT | Transformer decoder | unsupervised | model-based | task-agnostic | pre-trained layers + top task layer(s) |
| BERT | Transformer encoder | unsupervised | model-based | task-agnostic | pre-trained layers + top task layer(s) |
| GPT-2 | Transformer decoder | unsupervised | model-based | task-agnostic | pre-trained layers + top task layer(s) |
How to Setup the Environment for GPT-2
We’ll be working with a medium-sized model with 345 million parameters. You can download the pre-trained model from the official OpenAI GitHub repository.
First, we need to clone the repository by typing the below statement (I recommend using a Colab notebook instead of your local machine for faster computation):
Note that we will need to change our directory. To do that, we’ll use chdir() of class os:
Next, choose between the models which we want to use. In this case, we’ll be using a medium-sized model with 345 million parameters.
This model requires TensorFlow with GPU support to make it run faster. So let’s go ahead and install TensorFlow in our notebook:
We want to fulfill some essential requirements before diving into the modeling part. In the cloned folder, you’ll find a file – requirements.txt. This contains the following four libraries which are mandatory for this model to work:
- fire>=0.1.3
- regex==2017.4.5
- requests==2.21.0
- tqdm==4.31.1
Install all of these libraries using just one line of code:
That’s it – we’re all set with our environment. One last step before we dive into our text generator – downloading the medum-size pretrained model! Again – we can do this with just one line of code:
It’ll take a few moments depending on your internet bandwidth. Once we are done with that, we need to do encoding with the following code:
Implementing GPT-2 in Python to Build our own Text Generator
Are you ready? Because this is the moment you’ve been waiting for. Time to build our very own advanced text generator in Python using GPT-2! Let’s begin.
First, move into the src folder by using the chdir() just like we did before:
Then, import the required libraries:
Note: model, sample and encoder are the Python files present in the src subfolder of the main GPT-2 folder:
Let’s understand the parameters we just saw one-by-one:
- model_name: This indicates which model we are using. In our case, we are using the GPT-2 model with 345 million parameters or weights
- seed: Integer seed for random number generators, fix seed to reproduce results
- nsamples: This represents the number of sample texts generated in our output
- batch_size: This only affects speed/memory. This must also divide nsamples
Note: To generate more than one sample, you need to change the values of both nsamples and batch_size and also have to keep them equal.
- length: It represents the number of tokens in the generated text. If the length is None, then the number of tokens is decided by model hyperparameters
- temperature: This controls randomness in Boltzmann distribution. Lower temperature results in less random completions. As the temperature approaches zero, the model will become deterministic and repetitive. Higher temperature results in more random completions
- top_k: This parameter controls diversity. If the value of top_k is set to 1, this means that only 1 word is considered for each step (token). If top_k is set to 40, that means 40 words are considered at each step. 0 (default) is a special setting meaning no restrictions. top_k = 40 generally is a good value
- models_dir: It represents the path to parent folder containing model subfolders (contains the <model_name> folder)
Now, the time has come to witness the result produced by the most advanced language model. Let’s run this function and generate some text (be prepared to be stunned):
You will now be asked to enter a string. This is what I went with:
I went to a lounge to celebrate my birthday and
And here’s what my GPT-2 text generator came up with:
I called Donna and told her I had just adopted her. She thought my disclosure was a donation, but I’m not sure if Donna met the criteria. Donna was a genuinely sweet, talented woman who put her life here as a love story. I know she thanked me because I saw her from the photo gallery and she appreciated my outrage. It was most definitely not a gift. I appreciate that I was letting her care about kids, and that she saw something in me. I also didn’t have much choice but to let her know about her new engagement, although this doesn’t mean I wasn’t concerned, I am extremely thankful for all that she’s done to this country. When I saw it, I said, “Why haven’t you become like Betty or Linda?” “It’s our country’s baby and I can’t take this decision lightly.” “But don’t tell me you’re too impatient.” Donna wept and hugged me. She never expresses milk, otherwise I’d think sorry for her but sometimes they immediately see how much it’s meant to her. She apologized publicly and raised flagrant error of judgment in front of the society of hard choices to act which is appalling and didn’t grant my request for a birth certificate. Donna was highly emotional. I forgot that she is a scout. She literally didn’t do anything and she basically was her own surrogate owner. August 11, 2017 at 12:11 PM Anonymous said…
Incredible! I was speechless the first time I saw this result. The incredible level of detail and the impressive grammar – it’s almost impossible to tell that it was generated completely by a machine. Pretty impressive, right?
Go ahead and play around with the input string and share your results in the comments section below.
A Note on the Potential Misuse of GPT-2
GPT-2 has been in the news for its possible malicious use. You can imagine how powerful this NLP framework is. It could easily be used to generate fake news or frankly any fake text without humans being able to realize the difference.
Keeping these things in mind, OpenAI didn’t release the full model. Instead, they have released a much smaller model. The original model is trained on 40 GB of internet data and has 1.5 billion parameters. The two sample models OpenAI have released have 117 million and 345 million parameters.
End Notes
In this article, we’ve used the medium-sized model with 345M million parameters. If these smaller models are capable of generating such impressive results, imagine what the complete model of 1.5 billion parameters could generate. Scary and exciting at the same time.
What’s next for NLP? I have a feeling we won’t have to wait too long to find out.
In the meantime, try out this GPT-2 framework and let me know your experience below. Besides that, I also encourage you to use this model only for the purpose of research and to gain knowledge. Keep learning!








Thank you for the information.
Expressing milk and making requests for birth certificates? The generated story started out ok but hey I don't see this being weaponised in an automated fashion anytime soon, although progress continues to be made. PS. Did I write this or did GPT-2???
Very good post. i am getting an error at "import tensorflow as tf" in colab could you provide the version of tensorflow and cuda version used for this? Thanks
can you prime it with say a websites content and it successfully answer questions about it?
even with export PYTHONIOENCODING=UTF-8, I still get this:- Traceback (most recent call last): File "test.py", line 22, in interact_model enc = encoder.get_encoder(model_name, models_dir) File removed.... encoder.py", line 110, in get_encoder encoder = json.load(f) File "/usr/lib64/python3.7/json/__init__.py", line 296, in load parse_constant=parse_constant, object_pairs_hook=object_pairs_hook, **kw) File "/usr/lib64/python3.7/json/__init__.py", line 348, in loads return _default_decoder.decode(s) File "/usr/lib64/python3.7/json/decoder.py", line 337, in decode obj, end = self.raw_decode(s, idx=_w(s, 0).end()) File "/usr/lib64/python3.7/json/decoder.py", line 355, in raw_decode raise JSONDecodeError("Expecting value", s, err.value) from None json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
Hi Shubham--thanks for providing this for us. I'm trying to use Google Colab for this since you said you recommend it at the top, but it's not working. It keeps giving me library compatibility errors. I've tried Tensor Flow 1.14, 1.15, 2.0 but none of them work. Have you tried using Google Colab for this, or have you only used a local Jupiter notebook?
Dear Team, I want to use GPT2 or want to create similar project for our internal use in our company (Telecom) where user will give their requirements for reports and dashboard by explaining their KPI's. So Please explain,how can I train my model with our internal organization data so that when user fill the documents all the words related to telecom should appear like network, network speed, number of lines active.... . Could you please help us for this scenario.
I got an error: FileNotFoundError: [Errno 2] No such file or directory: '/gpt-2/models/345M/encoder.json' Even though I have the file encoder.json in the exact specified location. A little help please
in the first sight it seems like an overfitted model