Introduction to PyTorch-Transformers: An Incredible Library for State-of-the-Art NLP (with Python code)
Overview
- We look at the latest state-of-the-art NLP library in this article called PyTorch-Transformers
- We will also implement PyTorch-Transformers in Python using popular NLP models like Google’s BERT and OpenAI’s GPT-2!
- This has the potential to revolutionize the landscape of NLP as we know it
Introduction
“NLP’s ImageNet moment has arrived.” – Sebastian Ruder
Imagine having the power to build the Natural Language Processing (NLP) model that powers Google Translate. What if I told you this can be done using just a few lines of code in Python? Sounds like an incredibly exciting opportunity.
Well – we can now do this sitting in front of our own machines! The latest state-of-the-art NLP release is called PyTorch-Transformers by the folks at HuggingFace. This PyTorch-Transformers library was actually released just yesterday and I’m thrilled to present my first impressions along with the Python code.
The ability to harness this research would have taken a combination of years, some of the best minds, as well as extensive resources to be created. And we get to simply import it in Python and experiment with it. What a time to be alive!

I am truly astonished at the speed of research and development in NLP nowadays. Every new paper/framework/library just pushes the boundary of this incredibly powerful field. And due to the open culture of research around AI and large amounts of freely available text data, there is almost nothing that we can’t do today.
Now, I can’t stress enough the impact that PyTorch-Transformers will have on the research community as well as the NLP industry. I believe this has the potential to revolutionize the landscape of NLP as we know it.
Table of Contents
- Demystifying State-of-the-Art in NLP
- What is PyTorch-Transformers?
- Installing PyTorch-Transformers on our Machine
- Predicting the next word using GPT-2
- Natural Language Generation
- GPT-2
- Transformer-XL
- XLNet
- Training a Masked Language Model for BERT
- Analytics Vidhya’s Take on PyTorch-Transformers
Demystifying State-of-the-Art in NLP
Essentially, Natural Language Processing is about teaching computers to understand the intricacies of human language.

Before we get into the technical details of PyTorch-Transformers, let’s quickly revisit the very concept on which the library is built – NLP. We’ll also understand what state-of-the-art means as that will set the context for the article.
Here are a few things that you need to know before we start with PyTorch-Transformers:
- State-of-the-Art means an algorithm or a technique that is currently the “best” for a task. When we say “best”, we mean these are the algorithms pioneered by giants like Google, Facebook, Microsoft, and Amazon
- NLP has many well-defined tasks that researchers are studying to create intelligent techniques to solve them. Some of the most popular tasks are Language Translation, Text Summarization, Question Answering systems, etc.
- Deep Learning techniques like Recurrent Neural Networks (RNNs), Sequence2Sequence, Attention, and Word Embeddings (Glove, Word2Vec) have previously been the State-of-the-Art for NLP tasks
- These techniques were superseded by a framework called Transformers that is behind almost all of the current State-of-the-Art NLP models
Note: This article is going to be full of Transformers so I’d highly recommend that you read the below guide in case you need a quick refresher:
What is PyTorch-Transformers?
PyTorch-Transformers is a library of state-of-the-art pre-trained models for Natural Language Processing (NLP).
I have taken this section from PyTorch-Transformers’ documentation. This library currently contains PyTorch implementations, pre-trained model weights, usage scripts and conversion utilities for the following models:
- BERT (from Google) released with the paper BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- GPT (from OpenAI) released with the paper Improving Language Understanding by Generative Pre-Training
- GPT-2 (from OpenAI) released with the paper Language Models are Unsupervised Multitask Learners
- Transformer-XL (from Google/CMU) released with the paper Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
- XLNet (from Google/CMU) released with the paper XLNet: Generalized Autoregressive Pretraining for Language Understanding
- XLM (from Facebook) released together with the paper Cross-lingual Language Model Pretraining
All of the above models are the best in class for various NLP tasks. Some of these models are as recent as the previous month!
Most of the State-of-the-Art models require tons of training data and days of training on expensive GPU hardware which is something only the big technology companies and research labs can afford. But with the launch of PyTorch-Transformers, now anyone can utilize the power of State-of-the-Art models!
Installing PyTorch-Transformers on your Machine
Installing Pytorch-Transformers is pretty straightforward in Python. You can just use pip install:
pip install pytorch-transformers
or if you are working on Colab:
!pip install pytorch-transformers
Since most of these models are GPU heavy, I would suggest working with Google Colab for this article.
Note: The code in this article is written using the PyTorch framework.
Predicting the next word using GPT-2
Because PyTorch-Transformers supports many NLP models that are trained for Language Modelling, it easily allows for natural language generation tasks like sentence completion.
In February 2019, OpenAI created quite the storm through their release of a new transformer-based language model called GPT-2. GPT-2 is a transformer-based generative language model that was trained on 40GB of curated text from the internet.
Being trained in an unsupervised manner, it simply learns to predict a sequence of most likely tokens (i.e. words) that follow a given prompt, based on the patterns it learned to recognize through its training.
Let’s build our own sentence completion model using GPT-2. We’ll try to predict the next word in the sentence:
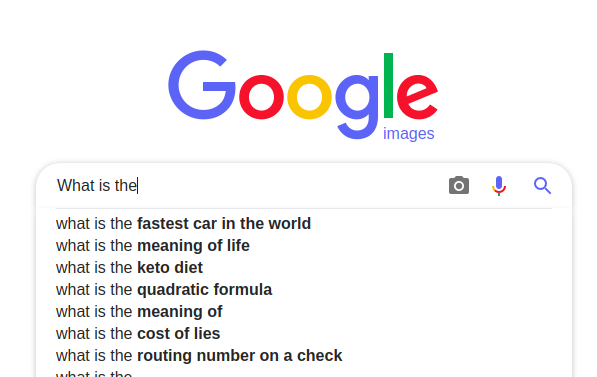
what is the fastest car in the _________
I chose this example because this is the first suggestion that Google’s text completion gives. Here is the code for doing the same:
The code is straightforward. We tokenize and index the text as a sequence of numbers and pass it to the GPT2LMHeadModel. This is nothing but the GPT2 model transformer with a language modeling head on top (linear layer with weights tied to the input embeddings).

Awesome! The model successfully predicts the next word as “world”. This is pretty amazing as this is what Google was suggesting. I recommend you try this model with different input sentences and see how it performs while predicting the next word in a sentence.
Natural Language Generation using GPT-2, Transformer-XL and XLNet
Let’s take Text Generation to the next level now. Instead of predicting only the next word, we will generate a paragraph of text based on the given input. Let’s see what output our models give for the following input text:
In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English.
We will be using the readymade script that PyTorch-Transformers provides for this task. Let’s clone their repository first:
!git clone https://github.com/huggingface/pytorch-transformers.git
GPT-2
Now, you just need a single command to start the model!
Let’s see what output our GPT-2 model gives for the input text:
The unicorns had seemed to know each other almost as well as they did common humans. The study was published in Science Translational Medicine on May 6. What's more, researchers found that five percent of the unicorns recognized each other well. The study team thinks this might translate into a future where humans would be able to communicate more clearly with those known as super Unicorns. And if we're going to move ahead with that future, we've got to do it at least a
Isn’t that crazy? The text that the model generated is very cohesive and actually can be mistaken as a real news article.
XLNet
XLNet integrates ideas from Transformer-XL, the state-of-the-art autoregressive model, into pretraining. Empirically, XLNet outperforms BERT on 20 tasks, often by a large margin. XLNet achieves state-of-the-art results on 18 tasks including question answering, natural language inference, sentiment analysis, and document ranking.
You can use the following code for the same:
This is the output that XLNet gives:
St. Nicholas was located in the valley in Chile. And, they were familiar with the southern part of Spain. Since 1988, people had lived in the valley, for many years. Even without a natural shelter, people were getting a temporary shelter. Some of the unicorns were acquainted with the Spanish language, but the rest were completely unfamiliar with English. But, they were also finding relief in the valley.<eop> Bioinfo < The Bioinfo website has an open, live community about the
Interesting. While the GPT-2 model focussed directly on the scientific angle of the news about unicorns, XLNet actually nicely built up the context and subtly introduced the topic of unicorns. Let’s see how does Transformer-XL performs!
Transformer-XL
Transformer networks are limited by a fixed-length context and thus can be improved through learning longer-term dependency. That’s why Google proposed a novel method called Transformer-XL (meaning extra long) for language modeling, which enables a Transformer architecture to learn longer-term dependency.
Transformer-XL is up to 1800 times faster than a typical Transformer.
You can use the below code to run Transformer-XL:
Here’s the text generated:
both never spoke in their native language ( a natural language ). If they are speaking in their native language they will have no communication with the original speakers. The encounter with a dingo brought between two and four unicorns to a head at once, thus crossing the border into Peru to avoid internecine warfare, as they did with the Aztecs. On September 11, 1930, three armed robbers killed a donkey for helping their fellow soldiers fight alongside a group of Argentines. During the same year
Now, this is awesome. It is interesting to see how different models focus on different aspects of the input text to generate further. This variation is due to a lot of factors but mostly can be attributed to different training data and model architectures.
But there’s a caveat. Neural text generation has been facing a bit of backlash in recent times as people worry it can increase problems related to fake news. But think about the positive side of it! We can use it for many positive applications like- helping writers/creatives with new ideas, and so on.
Training a Masked Language Model for BERT
The BERT framework, a new language representation model from Google AI, uses pre-training and fine-tuning to create state-of-the-art NLP models for a wide range of tasks. These tasks include question answering systems, sentiment analysis, and language inference.
BERT is pre-trained using the following two unsupervised prediction tasks:
- Masked Language Modeling (MLM)
- Next Sentence Prediction
And you can implement both of these using PyTorch-Transformers. In fact, you can build your own BERT model from scratch or fine-tune a pre-trained version. So, let’s see how can we implement the Masked Language Model for BERT.
Problem Definition
Let’s formally define our problem statement:
Given an input sequence, we will randomly mask some words. The model then should predict the original value of the masked words, based on the context provided by the other, non-masked, words in the sequence.
So why are we doing this? The model learns the rules of the language during the training process. And we’ll soon see how effective this process is.
First, let’s prepare a tokenized input from a text string using BertTokenizer:
This is how our text looks like after tokenization:

The next step would be to convert this into a sequence of integers and create PyTorch tensors of them so that we can use them directly for computation:
Notice that we have set [MASK] at the 8th index in the sentence which is the word ‘Hensen’. This is what our model will try to predict.
Now that our data is rightly pre-processed for BERT, we will create a Masked Language Model. Let’s now use BertForMaskedLM to predict a masked token:
Let’s see what is the output of our model:
Predicted token is: henson
That’s quite impressive.
This was a small demo of training a Masked Language Model on a single input sequence. Nevertheless, it is a very important part of the training process for many Transformer-based architectures. This is because it allows bidirectional training in models – which was previously impossible.
Congratulations! You’ve just implemented your first Masked Language Model! If you were trying to train BERT, you just finished half your work. This example will have given you a good idea of how to use PyTorch-Transformers to work with the BERT model.
Analytics Vidhya’s take on PyTorch-Transformers
In this article, we implemented and explored various State-of-the-Art NLP models like BERT, GPT-2, Transformer-XL, and XLNet using PyTorch-Transformers. This was more like a firest impressions expertiment that I did to give you a good intuition on how to work with this amazing library.
Here are 6 compelling reasons why I think you would love this library:
- Pre-trained models: It provides pre-trained models for 6 State-of-the-Art NLP architectures and pre-trained weights for 27 variations of these models
- Preprocessing and Finetuning API: PyTorch-Transformers doesn’t stop at pre-trained weights. It also provides a simple API for doing all the preprocessing and finetuning steps required for these models. Now, if you have read recent research papers, you’d know many of the State-of-the-Art models have unique ways of preprocessing the data and a lot of times it becomes a hassle to write code for the entire preprocessing pipeline
- Usage scripts: It also comes with scripts to run these models against benchmark NLP datasets like SQUAD 2.0 (Stanford Question Answering Dataset), and GLUE (General Language Understanding Evaluation). By using PyTorch-Transformers, you can directly run your model against these datasets and evaluate the performance accordingly
- Multilingual: PyTorch-Transformers has multilingual support. This is because some of the models already work well for multiple languages
- TensorFlow Compatibility: You can import TensorFlow checkpoints as models in PyTorch
- BERTology: There is a growing field of study concerned with investigating the inner working of large-scale transformers like BERT (that some call “BERTology”)
Have you ever implemented State-of-the-Art models like BERT and GPT-2? What’s your first take on PyTorch-Transformers? Let’s discuss in the comments section below.
A computer science graduate, I have previously worked as a Research Assistant at the University of Southern California(USC-ICT) where I employed NLP and ML to make better virtual STEM mentors. My research interests include using AI and its allied fields of NLP and Computer Vision for tackling real-world problems.










Great article Mohd Sanad Zaki Rizvi. Thanks for sharing this work.
Hey Vaibhav glad you liked it!
Nice article..
Suneel thanks for your feedback! :)
Simple and rich article! Nice work :)
would the same work for other languages say Hindi or Urdu???
Awesome article, thanks man. Can you please guide me to implement in same manner for Q&A part.
Hey Mahi, I haven't explored the QA part yet but you can look up the documentation here:https://huggingface.co/pytorch-transformers/model_doc/bert.html#bertforquestionanswering
Hey Mahi, I haven't explored the QA part yet but you can look up the documentation here: https://huggingface.co/pytorch-transformers/model_doc/bert.html#bertforquestionanswering
Glad to see another post introducing this awesome open source projects! For those who want to handle Chinese text, there is a Chinese tutorial on how to use BERT to fine-tune multi-label text classification task with the package. Hope we can get more people involved.
Awesome! i feel enlightened.. Could you pl share link to some videos which elaborate the maths behind Transformers.
Hey, Pankaj glad that you liked the article! You can check out this video from Stanford for understanding the underlying principles of Transformers https://www.youtube.com/watch?v=5vcj8kSwBCY
very informative.
Hey Ashvika, Glad you liked it!
Dear MOHD awesome work in explaining this SOT library. could please share me a link or tutorial on the subject of text classification with pythorch-transformer.
how to import XLM models?
The approach will be similar to what we have done.. you can read more in the documentation: https://huggingface.co/transformers/
Hey Rizvi, Great article. I had a problem to apply "GPT-2. When I try to run, appeer this error: (base) C:\Users\Marco>python pytorch-transformers/examples/run_generation.py Traceback (most recent call last): File "pytorch-transformers/examples/run_generation.py", line 25, in import torch ModuleNotFoundError: No module named 'torch' Conda and all of packages are updated. Do I need a GPU? Thanks!
Hey Antonio, You do need a GPU but this is not a GPU error. This is the error because you do not have "torch" installed which is the pre-requisite for Pytorch-Transformers.
That's an amazing article on latest breakthroughs in Natural Language Processing. Thank you!
Where is the beef? Just kidding. simply AWESOME!!! Can u give some pointer how/where we can just simply translate technical/legal document? JZK!
I not able to comprehend the max sequence length of 512 in BERT. Does it mean i will not be able to build a classifier if a documents are long ( Eg: having more than 1000 words)
Hey Satish, Let's say you have:
the man went to the store and bought a gallon of milkAnd had max_seq_length = 6, stride = 3, then you could split it up like this:the man went to the store to the store and bought a and bought a gallon of milkYou'll have to be a little careful though. You can read more at this thread: https://github.com/google-research/bert/issues/27 The exact implementation is task-specific of course.Hey Rizvi, great article: Does the BERT could be used in Text Summary? Can you show me a simple example? Thanks
Hi Rizvi, great article: Can you please show me an example using BERT to implement Text Summary? Dose BERT could be used in TextSummary? Thanks!