How many boosting algorithms do you know? Can you name at least two boosting algorithms in machine learning? Boosting algorithms have been around for years and yet it’s only recently that they’ve become mainstream in the machine learning community. But why have these boosting algorithms become so popular?
One of the primary reasons for the rise in the adoption of boosting algorithms is machine learning competitions. Boosting algorithms grant superpowers to machine learning models to improve their prediction accuracy. A quick look through Kaggle competitions and DataHack hackathons is evidence enough – boosting algorithms are wildly popular!
Simply put, boosting algorithms often outperform simpler models like logistic regression and decision trees. In fact, most top finishers on our DataHack platform either use a boosting algorithm or a combination of multiple boosting algorithms.
In this article, I will introduce you to four popular boosting algorithms that you can use in your next machine learning hackathon or project. These are: Gradient Boosting Machine (GBM), Extreme Gradient Boosting Machine (XGBM), LightGBM, and CatBoost

Picture this scenario: You’ve built a linear regression model that gives you a decent 77% accuracy on the validation dataset. Next, you decide to expand your portfolio by building a k-Nearest Neighbour (KNN) model and a decision tree model on the same dataset. These models gave you an accuracy of 62% and 89% on the validation set respectively.
It’s obvious that all three models work in completely different ways. For instance, the linear regression model tries to capture linear relationships in the data while the decision tree model attempts to capture the non-linearity in the data.
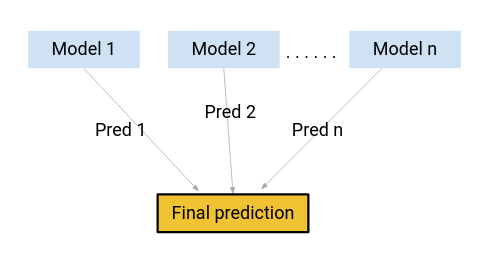
How about, instead of using any one of these models for making the final predictions, we use a combination of all of these models?
I’m thinking of an average of the predictions from these models. By doing this, we would be able to capture more information from the data, right?
That’s primarily the idea behind ensemble learning. And where does boosting come in?
Boosting is one of the techniques that use the concept of ensemble learning. A boosting algorithm combines multiple simple models (also known as weak learners or base estimators) to generate the final output.
We will look at some of the important boosting algorithms in this article.
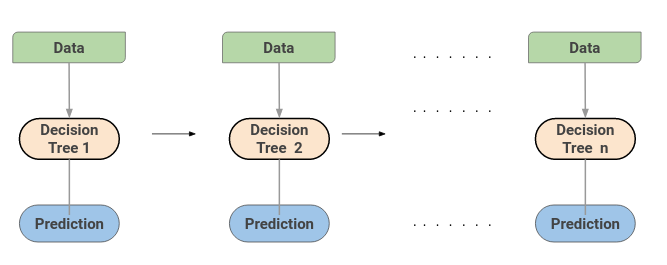
A Gradient Boosting Machine or GBM combines the predictions from multiple decision trees to generate the final predictions. Keep in mind that all the weak learners in a gradient-boosting machine are decision trees.
But if we are using the same algorithm, then how is using a hundred decision trees better than using a single decision tree? How do different decision trees capture different signals/information from the data?
Here is the trick – the nodes in every decision tree take a different subset of features for selecting the best split. This means that the individual trees aren’t all the same and hence they are able to capture different signals from the data.
Additionally, each new tree takes into account the errors or mistakes made by the previous trees. So, every successive decision tree is built on the errors of the previous trees. This is how the trees in a gradient-boosting machine algorithm are built sequentially.
Here is an article that explains the hyperparameter tuning process for the GBM algorithm:
Extreme Gradient Boosting or XGBoost is another popular boosting algorithm. In fact, XGBoost is simply an improvised version of the GBM algorithm! The working procedure of XGBoost is the same as GBM. The trees in XGBoost are built sequentially, trying to correct the errors of the previous trees.
Here is an article that intuitively explains the math behind XGBoost and also implements XGBoost in Python:

But there are certain features that make XGBoost slightly better than GBM:
Learn about the different hyperparameters of XGBoost and how they play a role in the model training process here:
Additionally, if you are using the XGBM algorithm, you don’t have to worry about imputing missing values in your dataset. The XGBM model can handle the missing values on its own. During the training process, the model learns whether missing values should be in the right or left node.
The LightGBM boosting algorithm is becoming more popular by the day due to its speed and efficiency. LightGBM is able to handle huge amounts of data with ease. But keep in mind that this algorithm does not perform well with a small number of data points.
Let’s take a moment to understand why that’s the case.
The trees in LightGBM have a leaf-wise growth, rather than a level-wise growth. After the first split, the next split is done only on the leaf node that has a higher delta loss.
Consider the example I’ve illustrated in the below image:
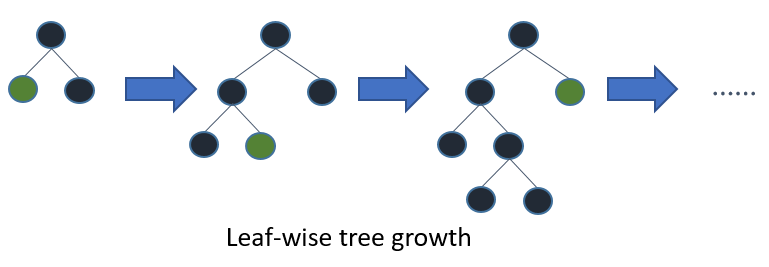
After the first split, the left node had a higher loss and is selected for the next split. Now, we have three leaf nodes, and the middle leaf node had the highest loss. The leaf-wise split of the LightGBM algorithm enables it to work with large datasets.
In order to speed up the training process, LightGBM uses a histogram-based method for selecting the best split. For any continuous variable, instead of using the individual values, these are divided into bins or buckets. This makes the training process faster and lowers memory usage.
Here’s an excellent article that compares the LightGBM and XGBoost Algorithms:
As the name suggests, CatBoost is a boosting algorithm that can handle categorical variables in the data. Most machine learning algorithms cannot work with strings or categories in the data. Thus, converting categorical variables into numerical values is an essential preprocessing step.
CatBoost can internally handle categorical variables in the data. These variables are transformed to numerical ones using various statistics on combinations of features.
If you want to understand the math behind how these categories are converted into numbers, you can go through this article:

Another reason why CatBoost is being widely used is that it works well with the default set of hyperparameters. Hence, as a user, we do not have to spend a lot of time tuning the hyperparameters.
Here is an article that implements CatBoost on a machine learning challenge:
CatBoost: A Machine Learning Library to Handle Categorical Data Automatically
The field of data science and machine learning is continually evolving, and boosting algorithms plays a pivotal role in enhancing model performance across various applications. As a data scientist delves into the intricacies of machine learning, understanding the nuances of algorithms like Gradient Boosting Machine (GBM), Extreme Gradient Boosting Machine (XGBM), LightGBM, and CatBoost becomes essential.
Considerations such as training time, the selection of appropriate classifiers, meticulous choice of metrics, and thoughtful handling of model performance are crucial aspects. The exploration of training data, integration of cross-validation techniques, and the utilization of GPUs to expedite computations contribute to the efficiency of the learning process.
Hyperparameter tuning, involving iterations with careful adjustments of parameters like max_depth and the number of trees, significantly impacts the success of boosting algorithms. Leveraging tools like scikit-learn (sklearn) facilitates the implementation of these algorithms, emphasizing tree-based structures and their impact on model outcomes.
Notable frameworks such as GBDT (Gradient Boosting Decision Trees) and Goss (Gradient-based One-Side Sampling) highlight the diversity within the gradient boosting framework. Understanding the principles of gradient descent and its application in boosting, along with the support from industry leaders like Microsoft and Yandex, further enriches the data scientist’s toolkit.
Considerations for n_estimators, neural networks, numerical handling (num), and techniques like one-hot encoding play a role in refining the feature engineering process. The exploration of open-source platforms and libraries, such as scikit-learn, contributes to a collaborative and dynamic community, fostering advancements in the field.
Addressing challenges related to classification problems, implementing early stopping strategies, and dealing with residuals contribute to the robustness of boosting algorithms. The integration of stochastic gradient techniques, thorough evaluation of test sets, and optimization of training speed are imperative for real-world applicability.
The intersection of boosting algorithms with diverse aspects of data science, from algorithmic intricacies to practical considerations like training speed and test set evaluation, underscores their significance. As the landscape continues to evolve, data scientists must navigate complex scenarios, leveraging the rich toolkit provided by boosting algorithms to achieve superior model performance in classification and regression tasks alike.
In this article, we covered the basics of ensemble learning and looked at the 4 types of boosting algorithms. Interested in learning about other ensemble learning methods? You should check out the following article:
Ready to master boosting algorithms? Join our “Machine Learning Essentials: GBM, XGBoost, LightGBM & CatBoost” course and gain hands-on experience in boosting your models’ performance with confidence—unlock your potential today!
A. XGBoost is known for its regularization techniques, CatBoost excels in handling categorical features, and LightGBM is optimized for distributed and efficient training.
A. Boosting algorithms are ensemble learning techniques that combine the predictions of multiple weak learners (typically decision trees) to create a strong learner. Popular boosting algorithms include AdaBoost, Gradient Boosting Machine (GBM), XGBoost, LightGBM, and CatBoost.
A. XGBoost is a versatile algorithm used for supervised learning tasks, such as classification, regression, and ranking. It is known for its speed, scalability, and regularization techniques.
A. LightGBM has various parameters that can be tuned for optimal performance. Some key parameters include the learning rate, tree depth, number of leaves, and bagging fraction. Tuning these parameters can significantly impact the model’s behavior.
A. While XGBoost and LightGBM require manual encoding of categorical features, CatBoost automatically handles them. This automatic handling of categorical variables in CatBoost simplifies the preprocessing step, leading to better performance.
A. Gradient boosting machines build a strong predictive model by combining the predictions of multiple weak learners in a sequential manner. Each weak learner corrects the errors of the previous ones, and the ensemble converges towards an accurate and robust model.
A. No, these boosting algorithms are not used in Random Forest. While random forest builds multiple decision trees independently and combines their predictions, boosting algorithms sequentially build a strong model by correcting the errors of the previous weak learners.
Lorem ipsum dolor sit amet, consectetur adipiscing elit,








AdaBosst algorithm was missed! Ernest Bonat, Ph.D. Senior Software Engineer Senior Data Scientist
Hey Ernest, I selected the above mentioned algorithms since they are more popularly used. If you want to read about the adaboost algorithm you can check out the following link: https://www.analyticsvidhya.com/blog/2015/05/boosting-algorithms-simplified/
I really enjoyed reading this post! It's fascinating to learn about the different ways to boost algorithms in machine learning. I'm particularly interested in exploring the use of gradient boosting in my own projects. Thanks for sharing your insights!
Great post! I completely agree that boosting algorithms have revolutionized the field of machine learning. The ability to combine multiple weak models to create a strong one has led to tremendous improvements in model accuracy and efficiency. I'm excited to see how these algorithms continue to evolve and improve in the future.
Great breakdown of the different boosting algorithms in machine learning! It's really helpful to see the pros and cons of each algorithm and how they can be applied in different scenarios. I'm particularly interested in trying out LightBoost and CatBoost, as they seem to have some unique features that could be useful in my own projects. Thanks for sharing your insights!