Introduction
We are standing at the intersection of language and machines. I’m fascinated by this topic. Can a machine write as well as Shakespeare? What if a machine could improve my own writing skills? Could a robot interpret a sarcastic remark?
I’m sure you’ve asked these questions before. Natural Language Processing (NLP) also aims to answer these questions, and I must say, there has been groundbreaking research done in this field towards bridging the gap between humans and machines.

One of the core ideas in NLP is text classification. If a machine can differentiate between a noun and a verb, or if it can detect a customer’s satisfaction with the product in his/her review, we can use this understanding for other advanced NLP tasks like understanding context or even generating a brand new story!
That’s primarily the reason we’ve seen a lot of research in text classification. And yes, the advent of transfer learning has definitely helped accelerate the research. We are now able to use a pre-existing model built on a huge dataset and tune it to achieve other tasks on a different dataset.
Transfer learning, and pretrained models, have 2 major advantages:
- It has reduced the cost of training a new deep learning model every time
- These datasets meet industry-accepted standards, and thus the pretrained models have already been vetted on the quality aspect
You can see why there’s been a surge in the popularity of pretrained models. We’ve seen the likes of Google’s BERT and OpenAI’s GPT-2 really take the bull by the horns. I’ll cover 6 state-of-the-art text classification pretrained models in this article.
I assume that you are aware of what text classification is. Here’s a comprehensive tutorial to get you up to date:
The Pretrained Models for Text Classification we’ll cover:
- XLNet
- ERNIE
- Text-to-Text Transfer Transformer (T5)
- Binary Partitioning Transfomer (BPT)
- Neural Attentive Bag-of-Entities (NABoE)
- Rethinking Complex Neural Network Architectures
Pretrained Model #1: XLNet
We can’t review state-of-the-art pretrained models without mentioning XLNet!
Google’s latest model, XLNet achieved State-of-the-Art (SOTA) performance on the major NLP tasks such as Text Classification, Sentiment Analysis, Question Answering, and Natural Language Inference along with the essential GLUE benchmark for English. It outperformed BERT and has now cemented itself as the model to beat for not only text classification, but also advanced NLP tasks.
The core ideas behind XLNet are:
- Generalized Autoregressive Pretraining for Language Understanding
- The Transformer-XL

If this sounds complicated, don’t worry! I’ll break this down into simple words.
Autoregressive modeling is used to predict the next word using the context words occurring either before or after the missing word in question. However, we can’t process both the forward and backward directions at the same time.
Though BERT’s autoencoder did take care of this aspect, it did have other disadvantages like assuming no correlation between the masked words. To combat this, XLNet proposes a technique called Permutation Language Modeling during the pre-training phase. This technique uses permutations to generate information from both the forward and backward directions simultaneously.
It is no secret that the Transformer architecture has been a game-changer. XLNet uses Transformer XL. As we know, transformers were an alternative to recurrent neural networks (RNN) in the sense that they allowed non-adjacent tokens to be processed together as well. This improved understanding of long-distance relations in text. Transformer-XL is basically an enhanced version of the transformer used in BERT by adding two components:
- A recurrence at specific segments which gives the context between 2 sequences
- A relative positional embedding which contains information on the similarity between 2 tokens
As I mentioned previously, XLNet outperformed BERT on almost all tasks, including Text Classification and achieves SOTA performance on 18 of them!
Here is a summary of the Text Classification tasks and how XLNet performs on these different datasets and the high rank it has achieved on them:

- Link to the Paper: XLNet: Generalized Autoregressive Pretraining for Language Understanding
- Github Link: https://github.com/zihangdai/xlnet
Pretrained Model #2: ERNIE
Though ERNIE 1.0 (released in March 2019) has been a popular model for text classification, it was ERNIE 2.0 which became the talk of the town in the latter half of 2019. Developed by tech-giant Baidu, ERNIE outperformed Google XLNet and BERT on the GLUE benchmark for English.
ERNIE stands for Enhanced Representation through kNowledge IntEgration, and ERNIE 2.0 is an upgraded version of ERNIE 1.0. ERNIE 1.0 was pathbreaking in its own way – it was one of the first models to leverage Knowledge Graphs. This incorporation further enhanced training the model for advanced tasks like Relation Classification and NamedEntityRecognition (NER).
Like its predecessor, ERNIE 2.0 brings another innovation to the table in the form of Continual Incremental Multi-task Learning. Basically, this means that the model has defined 7 clear tasks, and
- can generate the output of more than 1 task at the same time. For example, completing the sentence “I like going to New …” -> “I like going to New York”, and also classify the sentence as having a positive sentiment. The loss is also calculated accordingly for the combined tasks
- uses the output of previous tasks for the next task incrementally. For example, the output of Task 1 is used as training for Task 1, Task 2; output for this, Task 1 and Task 2 is used for training Tasks 1, 2 and 3,… and so on
I really like how intuitive this process is since it follows a human way of understanding text. Our brain does not only think of “I like going to New York” as a positive sentence, does it? It simultaneously understands the nouns “New York”, and I; understand the verb “like”, and infers that New York is a place.
ERNIE achieves a SOTA F1-Score of 88.32 on the Relation Extraction Task.
- Link to the Paper: ERNIE: Enhanced Language Representation with Informative Entities
- Github Link: https://github.com/thunlp/ERNIE
Pretrained Model #3: Text-to-Text Transfer Transformer (T5)
I’ll be honest – I had the most fun studying this model as compared to the others. Google’s new Text-to-Text Transfer Transformer (T5) model uses transfer learning for a variety of NLP tasks.
The most interesting part is that it converts every problem to a text input – a text output model. So, even for a classification task, the input will be text, and the output will again be a word instead of a label. This boils down to a single model on all tasks. Not only this, the output for one task can be used as input for the next task.
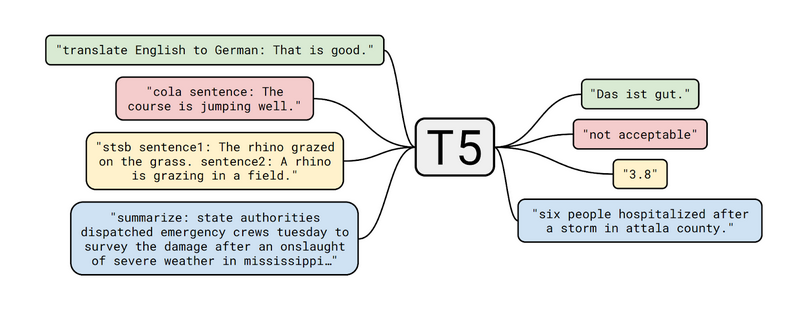
The corpus uses an enhanced version of Common Crawls. This is basically scraped text from the web. The paper actually highlights the importance of cleaning the data, and clearly elucidates how this was done. Though the scraped data generates data of 20TB per month, most of this data is not suitable for NLP tasks.
Even after retaining only text content (pages containing markups, code content, etc have been removed), the corpus still has a size of a whopping 750GB which is much larger than most datasets.
Note: This has been released on TensorFlow too: c4.
The task which is to be performed is encoded as a prefix along with the input. As you can see in the diagram above, be it a classification or a regression task, the T5 model still generates new text to get the output.
The T5 achieves SOTA on more than 20 established NLP tasks – this is rare, and taking a look at the metrics, it is as close to a human output as possible.
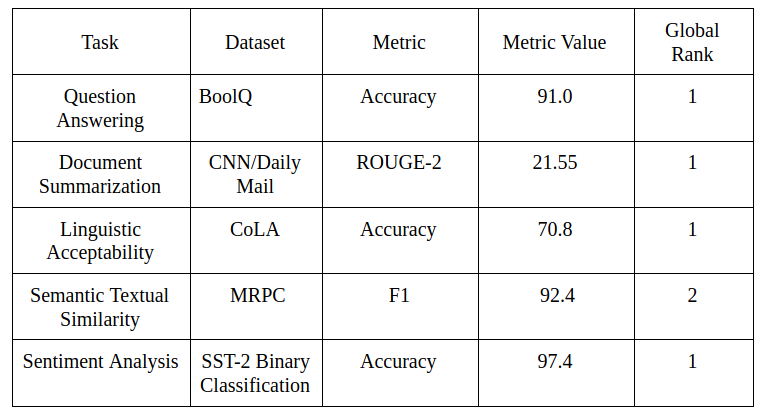
The T5 model follows up on the recent trend of training on unlabelled data and then fine-tuning this model on the labeled text. Understandably, this model is huge, but it would be interesting to see further research on scaling down such models for wider usage and distribution.
- Link to the Paper: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
- Github Link: https://github.com/google-research/text-to-text-transfer-transformer
Pretrained Model #4: Binary-Partitioning Transformer (BPT)
As we have seen so far, the Transformer architecture is quite popular in NLP research. The BP Transformer again uses the transformer, or rather an enhanced version of it for text classification, machine translation, etc.
However, using a transformer is still a costly process since it uses the self-attention mechanism. Self-attention just means that we are performing the attention operation on the sentence itself, as opposed to 2 different sentences (this is attention). Self-attention helps identify the relationship between the words in a single sentence. It is this self-attention mechanism that contributes to the cost of using a transformer.

The Binary-Partitioning Transformer (BPT) aims to improve the efficiency of the self-attention mechanism by treating the transformer as a graph neural network. Essentially, each node in this graph represents an input token.
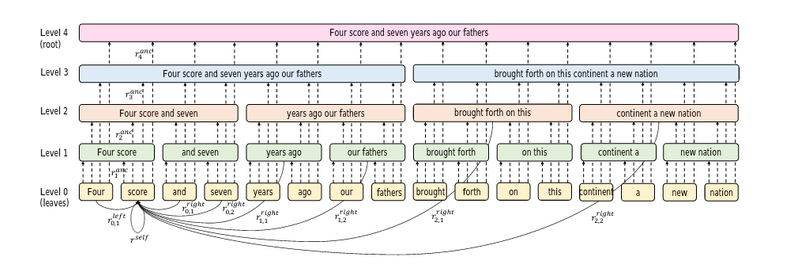
This is how the BP Transformer works:
Step 1: Divide the sentence into 2 parts recursively until some stopping condition is reached. This is called a binary partitioning. So, for example, the sentence “I like going to New York” will have the following partitions:
- I like going; to New York
- I like; going; to New; York
- I; like; going; to; New; York
Note: A sentence with n words will have 2*n – 1 partitions, and in the end, you have a complete binary tree.
Step 2: Each partition is now a node in the Graph Neural Network. There can be 2 types of edges:
- The edge connecting a parent node to its children
- The edge connecting the leaf nodes with other nodes
Step 3: Perform self-attention on each node of the graph with its neighboring nodes:
The BPT achieves:
- SOTA performance on Chinese to English Machine Translation (BLEU score: 19.84)
- Accuracy of 92.12 for Sentiment Analysis on the IMDb dataset (combined with GloVE embedding)
I appreciate this model in the sense that it made me revisit the concept of graphs and made me venture into looking up graph neural networks. I am admittedly late to the party, but I will surely be exploring more on Graph Neural networks in the near future!
- Link to the Paper: BP-Transformer: Modelling Long-Range Context via Binary Partitioning
- Github Link: https://github.com/yzh119/BPT
Pretrained Model #5: Neural Attentive Bag-of-Entities Model for Text Classification (NABoE)
Neural networks have always been the most popular models for NLP tasks and they outperform the more traditional models. Additionally, replacing entities with words while building the knowledge base from the corpus has improved model learning.
This means that instead of building vocabulary from the words in a corpus, we build a bag of entities using Entity Linking. Though there has been research on this method of representing the corpus to the model, the NABoE model goes a step further by:
- Using a Neural network to detect the entities
- Using the attention mechanism to compute the weights on the detected entities (this decides the relevance of the entities for the document in question)
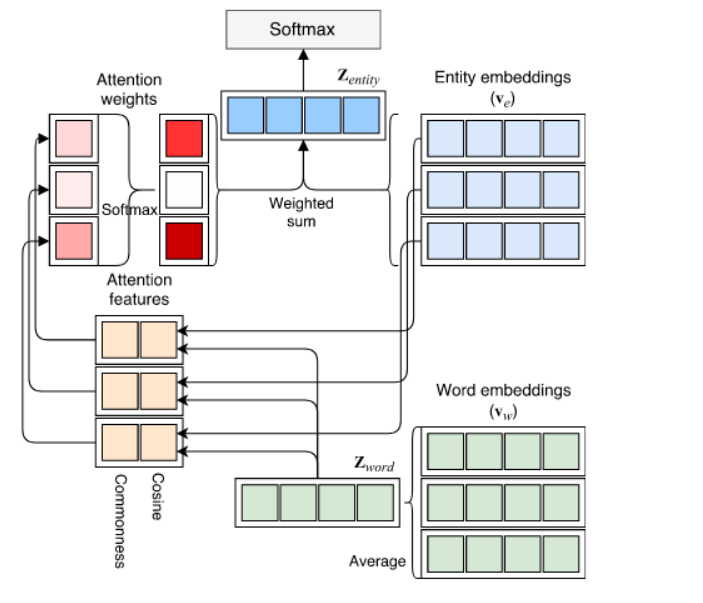
The Neural Attentive Bag of Entities model uses the Wikipedia corpus to detect the associated entities with a word. For example, the word “Apple” can refer to the fruit, the company, and other possible entities. Once all these entities are retrieved, the weight of each entity is calculated using the softmax-based attention function. This gives a smaller subset of entities which are relevant only to that particular document.
In the end, the final representation of the word is given by its vectorized embedding combined with the vectorized embedding of the relevant entities associated with the word.
The NABoE model performs particularly well on Text Classification tasks:
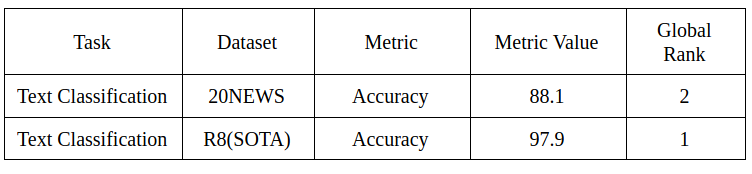
- Link to the Paper: Neural Attentive Bag-of-Entities Model for Text Classification
- Github Link: https://github.com/wikipedia2vec/wikipedia2vec/tree/master/examples/text_classification
Pretrained Model #6: Rethinking Complex Neural Network Architectures for Document Classification
Now, it might appear counter-intuitive to study all these advanced pretrained models and at the end, discuss a model that uses plain (relatively) old Bidirectional LSTM to achieve SOTA performance. But that was precisely why I decided to introduce it at the end.
Oftentimes, we miss the forest for the trees. We tend to forget that a simple well-tuned model might achieve just as good results as these complex deep learning models. This paper aims to explain just that.
A combination of Bidirectional LSTM and Regularization is able to achieve SOTA performance on the IMDb document classification task and stands shoulder-to-shoulder with other bigwigs in this domain.
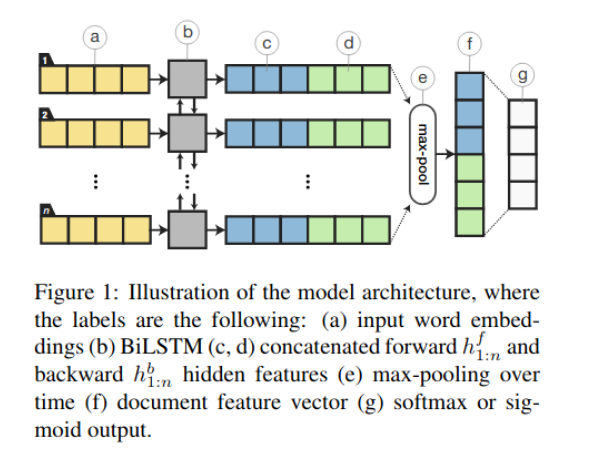
The most intriguing and noteworthy aspects of this paper are:
- It does not use the attention mechanism
- It is the first paper to use a combination of LSTM + regularization for document classification
This minimalistic model uses Adam optimizer, temporal averaging and dropouts to achieve this high score. The paper empirically compares these results with other deep learning models and demonstrates how this model is simple but effective and the results speak for themselves:
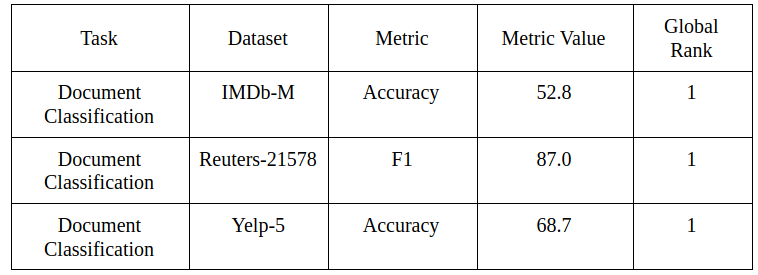
This kind of model can be considered a novel approach for the industry where it is important to build production-ready models and yet achieve high scores on your metrics.
- Link to the paper: Rethinking Complex Neural Network Architectures for Document Classification
- Github Link: https://github.com/castorini/hedwig
End Notes
Here, we discussed the top 6 pretrained models that achieved state-of-the-art benchmarks in text classification recently. These NLP models show that there are many more ones yet to come and I will be looking forward to learning about them this year.
The one awesome element in all this research is the availability and open source nature of these pretrained models. All the above models have a GitHub repository to them and are available for implementation. Another aspect that cannot be ignored is that they are available on PyTorch as well. This emphasizes that PyTorch is fast replacing TensorFlow as THE platform to build your deep learning models.
I encourage you to try out these models on various datasets and experiment with them to understand how they work. If you have some models in mind which were just as cool but went under the radar last year, do mention them in the comments below!







