Introduction
spaCy is my go-to library for Natural Language Processing (NLP) tasks. I’d venture to say that’s the case for the majority of NLP experts out there!
Among the plethora of NLP libraries these days, spaCy really does stand out on its own. If you’ve used spaCy for NLP, you’ll know exactly what I’m talking about. And if you’re new to the power of spaCy, you’re about to be enthralled by how multi-functional and flexible this library is.
The factors that work in the favor of spaCy are the set of features it offers, the ease of use, and the fact that the library is always kept up to date.
This tutorial is a crisp and effective introduction to spaCy and the various NLP features it offers. I’d advise you to go through the below resources if you want to learn about the various aspects of NLP:
- Certified Natural Language Processing (NLP) Course
- Ines Montani and Matthew Honnibal – The Brains behind spaCy
- Introduction to Natural Language Processing (Free Course!)
Table of contents
Getting Started with spaCy
If you are new to spaCy, there are a couple of things you should be aware of:
- spaCy’s Statistical Models
- spaCy’s Processing Pipeline
Let’s discuss each one in detail.
spaCy’s Statistical Models
These models are the power engines of spaCy. These models enable spaCy to perform several NLP related tasks, such as part-of-speech tagging, named entity recognition, and dependency parsing.
I’ve listed below the different statistical models in spaCy along with their specifications:
- en_core_web_sm: English multi-task CNN trained on OntoNotes. Size – 11 MB
- en_core_web_md: English multi-task CNN trained on OntoNotes, with GloVe vectors trained on Common Crawl. Size – 91 MB
- en_core_web_lg: English multi-task CNN trained on OntoNotes, with GloVe vectors trained on Common Crawl. Size – 789 MB
Importing these models is super easy. We can import a model by just executing spacy.load(‘model_name’) as shown below:
import spacy
nlp = spacy.load('en_core_web_sm')spaCy’s Processing Pipeline
The first step for a text string, when working with spaCy, is to pass it to an NLP object. This object is essentially a pipeline of several text pre-processing operations through which the input text string has to go through.
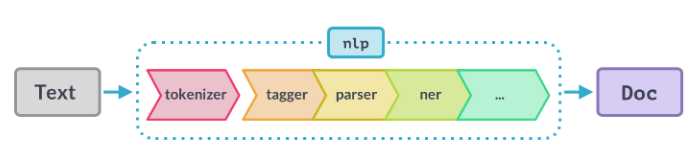
As you can see in the figure above, the NLP pipeline has multiple components, such as tokenizer, tagger, parser, ner, etc. So, the input text string has to go through all these components before we can work on it.
Let me show you how we can create an nlp object:
You can use the below code to figure out the active pipeline components:
nlp.pipe_namesOutput
['tagger', 'parser', 'ner']Just in case you wish to disable the pipeline components and keep only the tokenizer up and running, then you can use the code below to disable the pipeline components:
nlp.disable_pipes('tagger', 'parser')Let’s again check the active pipeline component:
nlp.pipe_namesOutput
['ner']When you only have to tokenize the text, you can then disable the entire pipeline. The tokenization process becomes really fast. For example, you can disable multiple components of a pipeline by using the below line of code:
nlp.disable_pipes('tagger', 'parser')spaCy in Action
Now, let’s get our hands dirty with spaCy. In this section, you will learn to perform various NLP tasks using spaCy. We will start off with the popular NLP tasks of Part-of-Speech Tagging, Dependency Parsing, and Named Entity Recognition.
1. Part-of-Speech (POS) Tagging using spaCy
In English grammar, the parts of speech tell us what is the function of a word and how it is used in a sentence. Some of the common parts of speech in English are Noun, Pronoun, Adjective, Verb, Adverb, etc.
POS tagging is the task of automatically assigning POS tags to all the words of a sentence. It is helpful in various downstream tasks in NLP, such as feature engineering, language understanding, and information extraction.
Performing POS tagging, in spaCy, is a cakewalk:
Output
He --> PRON
went --> VERB
to --> PART
play --> VERB
basketball --> NOUNSo, the model has correctly identified the POS tags for all the words in the sentence. In case you are not sure about any of these tags, then you can simply use spacy.explain() to figure it out:
spacy.explain("PART")
Output: 'particle'2. Dependency Parsing using spaCy
Every sentence has a grammatical structure to it and with the help of dependency parsing, we can extract this structure. It can also be thought of as a directed graph, where nodes correspond to the words in the sentence and the edges between the nodes are the corresponding dependencies between the word.

Performing dependency parsing is again pretty easy in spaCy. We will use the same sentence here that we used for POS tagging:
Output:
He --> nsubj
went --> ROOT
to --> aux
play --> advcl
basketball --> dobjThe dependency tag ROOT denotes the main verb or action in the sentence. The other words are directly or indirectly connected to the ROOT word of the sentence. You can find out what other tags stand for by executing the code below:
spacy.explain("nsubj"), spacy.explain("ROOT"), spacy.explain("aux"), spacy.explain("advcl"), spacy.explain("dobj")Output:
('nominal subject',
None,
'auxiliary',
'adverbial clause modifier',
'direct object')3. Named Entity Recognition using spaCy
Let’s first understand what entities are. Entities are the words or groups of words that represent information about common things such as persons, locations, organizations, etc. These entities have proper names.
For example, consider the following sentence:

In this sentence, the entities are “Donald Trump”, “Google”, and “New York City”.
Let’s now see how spaCy recognizes named entities in a sentence.
Output:
Introduction
spaCy is my go-to library for Natural Language Processing (NLP) tasks. I’d venture to say that’s the case for the majority of NLP experts out there!
Among the plethora of NLP libraries these days, spaCy really does stand out on its own. If you’ve used spaCy for NLP, you’ll know exactly what I’m talking about. And if you’re new to the power of spaCy, you’re about to be enthralled by how multi-functional and flexible this library is.
The factors that work in the favor of spaCy are the set of features it offers, the ease of use, and the fact that the library is always kept up to date.
spacy nlp
This tutorial is a crisp and effective introduction to spaCy and the various NLP features it offers. I’d advise you to go through the below resources if you want to learn about the various aspects of NLP:
Certified Natural Language Processing (NLP) Course
Ines Montani and Matthew Honnibal – The Brains behind spaCy
Introduction to Natural Language Processing (Free Course!)
Getting Started with spaCy
If you are new to spaCy, there are a couple of things you should be aware of:
spaCy’s Statistical Models
spaCy’s Processing Pipeline
Let’s discuss each one in detail.
Ready to start your data science journey?
Master 23+ tools & learn 50+ real-world projects to transform your career in Data Science.
spaCy’s Statistical Models
These models are the power engines of spaCy. These models enable spaCy to perform several NLP related tasks, such as part-of-speech tagging, named entity recognition, and dependency parsing.
I’ve listed below the different statistical models in spaCy along with their specifications:
en_core_web_sm: English multi-task CNN trained on OntoNotes. Size – 11 MB
en_core_web_md: English multi-task CNN trained on OntoNotes, with GloVe vectors trained on Common Crawl. Size – 91 MB
en_core_web_lg: English multi-task CNN trained on OntoNotes, with GloVe vectors trained on Common Crawl. Size – 789 MB
Importing these models is super easy. We can import a model by just executing spacy.load(‘model_name’) as shown below:
import spacy
nlp = spacy.load('en_core_web_sm')
spaCy’s Processing Pipeline
The first step for a text string, when working with spaCy, is to pass it to an NLP object. This object is essentially a pipeline of several text pre-processing operations through which the input text string has to go through.
spacy pipeline
Source: https://course.spacy.io/chapter3
As you can see in the figure above, the NLP pipeline has multiple components, such as tokenizer, tagger, parser, ner, etc. So, the input text string has to go through all these components before we can work on it.
Let me show you how we can create an nlp object:
import spacy
nlp = spacy.load('en_core_web_sm')
# Create an nlp object
doc = nlp("He went to play basketball")
view rawnlp_object_spacy.py hosted with ❤ by GitHub
You can use the below code to figure out the active pipeline components:
nlp.pipe_names
Output: [‘tagger’, ‘parser’, ‘ner’]
Just in case you wish to disable the pipeline components and keep only the tokenizer up and running, then you can use the code below to disable the pipeline components:
nlp.disable_pipes('tagger', 'parser')
Let’s again check the active pipeline component:
nlp.pipe_names
Output: [‘ner’]
When you only have to tokenize the text, you can then disable the entire pipeline. The tokenization process becomes really fast. For example, you can disable multiple components of a pipeline by using the below line of code:
nlp.disable_pipes('tagger', 'parser')
spaCy in Action
Now, let’s get our hands dirty with spaCy. In this section, you will learn to perform various NLP tasks using spaCy. We will start off with the popular NLP tasks of Part-of-Speech Tagging, Dependency Parsing, and Named Entity Recognition.
1. Part-of-Speech (POS) Tagging using spaCy
In English grammar, the parts of speech tell us what is the function of a word and how it is used in a sentence. Some of the common parts of speech in English are Noun, Pronoun, Adjective, Verb, Adverb, etc.
POS tagging is the task of automatically assigning POS tags to all the words of a sentence. It is helpful in various downstream tasks in NLP, such as feature engineering, language understanding, and information extraction.
Performing POS tagging, in spaCy, is a cakewalk:
import spacy
nlp = spacy.load('en_core_web_sm')
# Create an nlp object
doc = nlp("He went to play basketball")
# Iterate over the tokens
for token in doc:
# Print the token and its part-of-speech tag
print(token.text, "-->", token.pos_)
view rawpos_tagging_spacy.py hosted with ❤ by GitHub
Output:
He –> PRON
went –> VERB
to –> PART
play –> VERB
basketball –> NOUN
So, the model has correctly identified the POS tags for all the words in the sentence. In case you are not sure about any of these tags, then you can simply use spacy.explain() to figure it out:
spacy.explain("PART")
Output: ‘particle’
2. Dependency Parsing using spaCy
Every sentence has a grammatical structure to it and with the help of dependency parsing, we can extract this structure. It can also be thought of as a directed graph, where nodes correspond to the words in the sentence and the edges between the nodes are the corresponding dependencies between the word.
dependency tree spaCy
Dependency Tree
Performing dependency parsing is again pretty easy in spaCy. We will use the same sentence here that we used for POS tagging:
# dependency parsing
for token in doc:
print(token.text, "-->", token.dep_)
view rawdep_parsing_spacy.py hosted with ❤ by GitHub
Output:
He –> nsubj
went –> ROOT
to –> aux
play –> advcl
basketball –> dobj
The dependency tag ROOT denotes the main verb or action in the sentence. The other words are directly or indirectly connected to the ROOT word of the sentence. You can find out what other tags stand for by executing the code below:
spacy.explain("nsubj"), spacy.explain("ROOT"), spacy.explain("aux"), spacy.explain("advcl"), spacy.explain("dobj")
Output:
(‘nominal subject’,
None,
‘auxiliary’,
‘adverbial clause modifier’,
‘direct object’)
3. Named Entity Recognition using spaCy
Let’s first understand what entities are. Entities are the words or groups of words that represent information about common things such as persons, locations, organizations, etc. These entities have proper names.
For example, consider the following sentence:
Dependency Parsing spaCy
In this sentence, the entities are “Donald Trump”, “Google”, and “New York City”.
Let’s now see how spaCy recognizes named entities in a sentence.
Ready to start your data science journey?
Master 23+ tools & learn 50+ real-world projects to transform your career in Data Science.
view rawner_spacy.py hosted with ❤ by GitHub
Output:
Indians NORP
over $71 billion MONEY
2018 DATE
spacy.explain("NORP")Output: ‘Nationalities or religious or political groups’
4. Rule-Based Matching using spaCy
Rule-based matching is a new addition to spaCy’s arsenal. With this spaCy matcher, you can find words and phrases in the text using user-defined rules.
It is like Regular Expressions on steroids.
While Regular Expressions use text patterns to find words and phrases, the spaCy matcher not only uses the text patterns but lexical properties of the word, such as POS tags, dependency tags, lemma, etc.
Let’s see how it works:
So, in the code above:
- First, we import the spaCy matcher
- After that, we initialize the matcher object with the default spaCy vocabulary
- Then, we pass the input in an NLP object as usual
- In the next step, we define the rule/pattern for what we want to extract from the text.
Let’s say we want to extract the phrase “lemon water” from the text. So, our objective is that whenever “lemon” is followed by the word “water”, then the matcher should be able to find this pattern in the text. That’s exactly what we have done while defining the pattern in the code above. Finally, we add the defined rule to the matcher object.
Now let’s see what the matcher has found out:
matches = matcher(doc)
matchesOutput: [(7604275899133490726, 6, 8)]
The output has three elements. The first element, ‘7604275899133490726’, is the match ID. The second and third elements are the positions of the matched tokens.
Output: lemon water
So, the pattern is a list of token attributes. For example, ‘TEXT’ is a token attribute that means the exact text of the token. There are, in fact, many other useful token attributes in spaCy which can be used to define a variety of rules and patterns.
I’ve listed below the token attributes:
| ATTRIBUTE | TYPE | DESCRIPTION |
|---|---|---|
ORTH | unicode | The exact verbatim text of a token. |
TEXT | unicode | The exact verbatim text of a token. |
LOWER | unicode | The lowercase form of the token text. |
LENGTH | int | The length of the token text. |
IS_ALPHA, IS_ASCII, IS_DIGIT | bool | Token text consists of alphabetic characters, ASCII characters, digits. |
IS_LOWER, IS_UPPER, IS_TITLE | bool | Token text is in lowercase, uppercase, titlecase. |
IS_PUNCT, IS_SPACE, IS_STOP | bool | Token is punctuation, whitespace, stop word. |
LIKE_NUM, LIKE_URL, LIKE_EMAIL | bool | Token text resembles a number, URL, email. |
POS, TAG, DEP, LEMMA, SHAPE | unicode | The token’s simple and extended part-of-speech tag, dependency label, lemma, shape. |
ENT_TYPE | unicode | The token’s entity label. |
Let’s see another use case of the spaCy matcher. Consider the two sentences below:
- You can read this book
- I will book my ticket
Now we are interested in finding whether a sentence contains the word “book” in it or not. It seems pretty straight forward right? But here is the catch – we have to find the word “book” only if it has been used in the sentence as a noun.
In the first sentence above, “book” has been used as a noun and in the second sentence, it has been used as a verb. So, the spaCy matcher should be able to extract the pattern from the first sentence only.
Let’s try it out:
matches = matcher(doc1)
matches
Output: [(7604275899133490726, 3, 4)]The matcher has found the pattern in the first sentence.
matches = matcher(doc2)
matches
Output: [ ]Nice! Though “book” is present in the second sentence, the matcher ignored it as it was not a noun.
Conclusion
This was a quick introduction to give you a taste of what spaCy can do. Trust me, you will find yourself using spaCy a lot for your NLP tasks. I encourage you to play around with the code, take up a dataset from DataHack and try your hand on it using spaCy.
And if you’re cpmletely new to NLP and the various tasks you can do, I’ll again suggest going through the below comprehensive course: Certified Natural Language Processing (NLP) Course.
Frequently Asked Questions
Q1. Is spaCy better than NLTK?
A. spaCy is often considered better than NLTK for several reasons, including its speed, efficiency, and ease of use. NLTK is more focused on education, while spaCy is designed for production.
Q2. Is spaCy still relevant?
A. Yes, spaCy is highly relevant. It continues to be a popular and actively maintained natural language processing library, widely used in both academia and industry for various NLP tasks.
Q3. What is the real-life use of spaCy?
A. spaCy finds applications in various real-life scenarios, including text processing, information extraction, sentiment analysis, and named entity recognition (NER). Its efficiency and accuracy make it suitable for diverse NLP tasks.
Q4. Is spaCy good for NER?
A. Yes, spaCy excels in Named Entity Recognition (NER). It provides pre-trained models for NER tasks and allows customization for specific entities, making it a powerful tool for extracting structured information from unstructured text.
Prateek Joshi
28 Nov, 2023
Data Scientist at Analytics Vidhya with multidisciplinary academic background. Experienced in machine learning, NLP, graphs & networks. Passionate about learning and applying data science to solve real world problems.








not able to install spacy. Getting the following error. spacy.pipeline.morphologizer.array' has no attribute '__reduce_cython__'
It seems you forgot example code in `3. Named Entity Recognition using spaCy`
Thanks for pointing out. I have added the code.
Thank you for your article Prateek, I have a problem with your code: import spacy nlp = spacy.load('en_core_web_sm') # Import spaCy Matcher from spacy.matcher import Matcher # Initialize the matcher with the spaCy vocabulary matcher = Matcher(nlp.vocab) doc = nlp("Some people start their day with lemon water") # Define rule pattern = [{'TEXT': 'lemon'}, {'TEXT': 'water'}] # Add rule matcher.add('rule_1', None, pattern) matches = matcher(doc) matches I ought to get: [(7604275899133490726, 3, 4)] Instead, I get: [(93837904012480, 0, 1), (93837904012480, 1, 2), (93837904012480, 2, 3), (93837904012480, 3, 4), (93837904012480, 4, 5), (93837904012480, 5, 6), (93837904012480, 6, 7), (93837904012480, 7, 8)] I wasn't able to find the bug. Also subsequent code do not work as ought to do. Thnak you
Hello, I am using spacy in order to extract pattern and then sentences containing, those pattern. I would like to know if it is possible to check the value of the lasr attribute in a sequence of pattern : for example : I have this pattern pattern2 = [{"POS": "ADV"}, {"POS": "AUX"}, {"LOWER": "pas"}, {"POS": "ADJ"},] And I want to check in a sentence value of POS / ADJ if it is present in a list: for example : import spacy.attrs from spacy.attrs import POS import spacy from spacy.lang.fr import French from spacy.tokenizer import Tokenizer from spacy.util import compile_prefix_regex, compile_infix_regex, compile_suffix_regex nlp = spacy.load("fr_core_news_md") from spacy.matcher import Matcher matcher = Matcher(nlp.vocab) matcher.add("matching_1", None,pattern2) sent = [] a= "ce n'est pas bien' list= ['bien','mauvais','gentil'] doc=nlp(a) print([t.text for t in doc]) matches= matcher(doc) for match_id, start, end in matches: span = doc[start:end] print("found match:", span) if span.text in a: if span.text[-1] in lexique: sent.append(a) print(sent)
Hello , I am using spacy in order to identify different type of pattern. the pattern are mostly this form : What I am trying to do is check the value of the last post tag of my pattern in a lexicon. As you can see it is either an adj or adv. So if the word at that place is found in my dictionnary. I can append the sentences on my new list. I give you here a small edit of my code because, it returns me an empty list. So If you can help figure how to do that , I will appreciate any help. sentence = ["Voyons ce n'est pas mal ce que vous faites", "Vive la vie.", " Vous n'êtes pas bien.", "Je ne suis pas mauvaise","Jeune gens mangez bien", "Ce n'est pas mauvais", "il est peu scrupuleux", " il manque d'amour ou de conséridation", " il est sans merci", " il est trop cher" " il est de mauvaise qualité", "il est dépourvu de sens", ] pattern = [{"POS": "ADV"}, {"POS": "AUX"}, {"LOWER": "pas"}, {"POS": "ADV"},] # ADV, NOUN, ADJ pattern2 = [{"POS": "ADV"}, {"POS": "AUX"}, {"LOWER": "pas"}, {"POS": "ADJ"},] pattern3 = [{"LOWER": "peu"}, {"POS": "ADJ"},] matcher = Matcher(nlp.vocab) matcher.add("matching_1", None, pattern, pattern3, pattern2) lexique =['bien', 'gentil', 'long','scrupuleux'] f = open("file.txt", "w") print("token --> lemme --> dep -->pos ") for sent in sentence: doc=nlp(sent) for tok in doc: print(tok.text, "\t", tok.lemma_, "-->", tok.dep_, "-->", tok.pos_) sent_extract=[] for sent in sentence: doc=nlp(sent) print([t.text for t in doc]) matches= matcher(doc) for match_id, start, end in matches: span = doc[start:end] print("found match:", span) if span.text in sent: if span.text[-1] in lexique: sent_extract.append(sent) print(sent_extract) # show nothing
Really informative. If Anyone is looking forward for Biomedical domain NER. Refer their i.e Spacy Github repo. You can find some cool models there.
what model I should consider for Relation extraction for biomedical text. to simplify , I am looking for finding relation between CHEMICAL and DISEASE entities. I am using Spacy for NER and it's doing perfectly ok.