Support Vector Regression Tutorial for Machine Learning
Support Vector Machines (SVM) are popularly and widely used for classification problems in machine learning. I’ve often relied on this not just in machine learning projects but when I want a quick result in a hackathon.
But SVM for regression analysis? I hadn’t even considered the possibility for a while! And even now when I bring up “Support Vector Regression” in front of machine learning beginners, I often get a bemused expression. I understand – most courses and experts don’t even mention Support Vector Regression (SVR) as a machine learning algorithm.
But SVR has its uses as you’ll see in this tutorial. We will first quickly understand what SVM is, before diving into the world of Support Vector Regression in machine learning and how to implement it in Python!
Note: You can learn about Support Vector Machines and Regression problems in course format here (it’s free!):
Here’s what we’ll cover in this Support Vector Regression tutorial:
- What is a Support Vector Machine (SVM)?
- Hyperparameters of the Support Vector Machine Algorithm
- Introduction to Support Vector Regression (SVR)
- Implementing Support Vector Regression in Python
Table of contents
- Here’s what we’ll cover in this Support Vector Regression tutorial:
- What is a Support Vector Machine (SVM)?
- Hyperparameters of the Support Vector Machine (SVM) Algorithm
- Introduction to Support Vector Regression (SVR)
- Implementing Support Vector Regression (SVR) in Python
- Conclusion
- Frequently Asked Questions
Quiz of the Day #3

What is a Support Vector Machine (SVM)?
A Support Vector Machine (SVM) is a supervised machine learning algorithm used for classification and regression tasks. SVM works by finding a hyperplane in a high-dimensional space that best separates data into different classes. It aims to maximize the margin (the distance between the hyperplane and the nearest data points of each class) while minimizing classification errors. SVM can handle both linear and non-linear classification problems by using various kernel functions. It’s widely used in tasks such as image classification, text categorization, and more.
So what exactly is Support Vector Machine (SVM)? We’ll start by understanding SVM in simple terms. Let’s say we have a plot of two label classes as shown in the figure below:
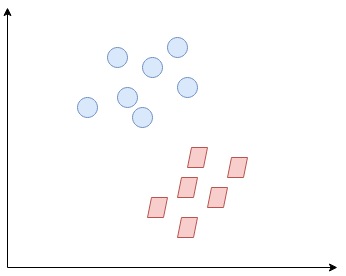
Can you decide what the separating line will be? You might have come up with this:
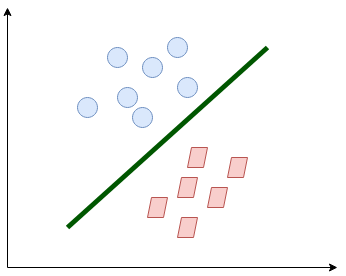
The line fairly separates the classes. This is what SVM essentially does – simple class separation. Now, what is the data was like this:
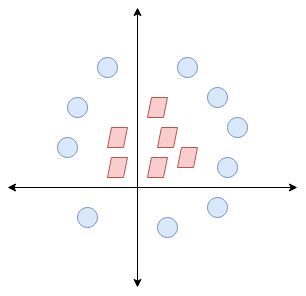
Here, we don’t have a simple line separating these two classes. So we’ll extend our dimension and introduce a new dimension along the z-axis. We can now separate these two classes:
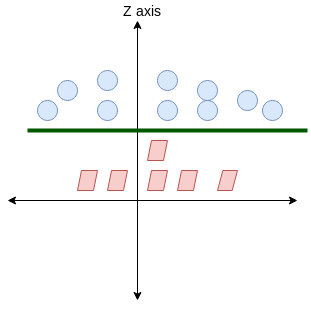
When we transform this line back to the original plane, it maps to the circular boundary as I’ve shown here:
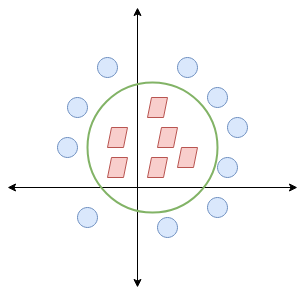
This is exactly what SVM does! It tries to find a line/hyperplane (in multidimensional space) that separates these two classes. Then it classifies the new point depending on whether it lies on the positive or negative side of the hyperplane depending on the classes to predict.
Hyperparameters of the Support Vector Machine (SVM) Algorithm
There are a few important parameters of SVM that you should be aware of before proceeding further:
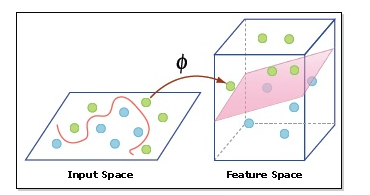
- Kernel: A kernel helps us find a hyperplane in the higher dimensional space without increasing the computational cost. Usually, the computational cost will increase if the dimension of the data increases. This increase in dimension is required when we are unable to find a separating hyperplane in a given dimension and are required to move in a higher dimension:
- Hyperplane: This is basically a separating line between two data classes in SVM. But in Support Vector Regression, this is the line that will be used to predict the continuous output
- Decision Boundary: A decision boundary can be thought of as a demarcation line (for simplification) on one side of which lie positive examples and on the other side lie the negative examples. On this very line, the examples may be classified as either positive or negative. This same concept of SVM will be applied in Support Vector Regression as well
To understand SVM from scratch, I recommend this tutorial: Understanding Support Vector Machine(SVM) algorithm from examples.
Introduction to Support Vector Regression (SVR)
Support Vector Regression (SVR) is a type of machine learning algorithm used for regression analysis. The goal of SVR is to find a function that approximates the relationship between the input variables and a continuous target variable, while minimizing the prediction error.
Unlike Support Vector Machines (SVMs) used for classification tasks, SVR seeks to find a hyperplane that best fits the data points in a continuous space. This is achieved by mapping the input variables to a high-dimensional feature space and finding the hyperplane that maximizes the margin (distance) between the hyperplane and the closest data points, while also minimizing the prediction error.
SVR can handle non-linear relationships between the input variables and the target variable by using a kernel function to map the data to a higher-dimensional space. This makes it a powerful tool for regression tasks where there may be complex relationships between the input variables and the target variable.
Support Vector Regression (SVR) uses the same principle as SVM, but for regression problems. Let’s spend a few minutes understanding the idea behind SVR.
The Idea Behind Support Vector Regression
The problem of regression is to find a function that approximates mapping from an input domain to real numbers on the basis of a training sample. So let’s now dive deep and understand how SVR works actually.
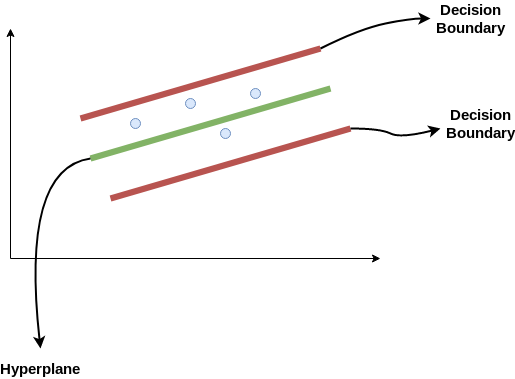
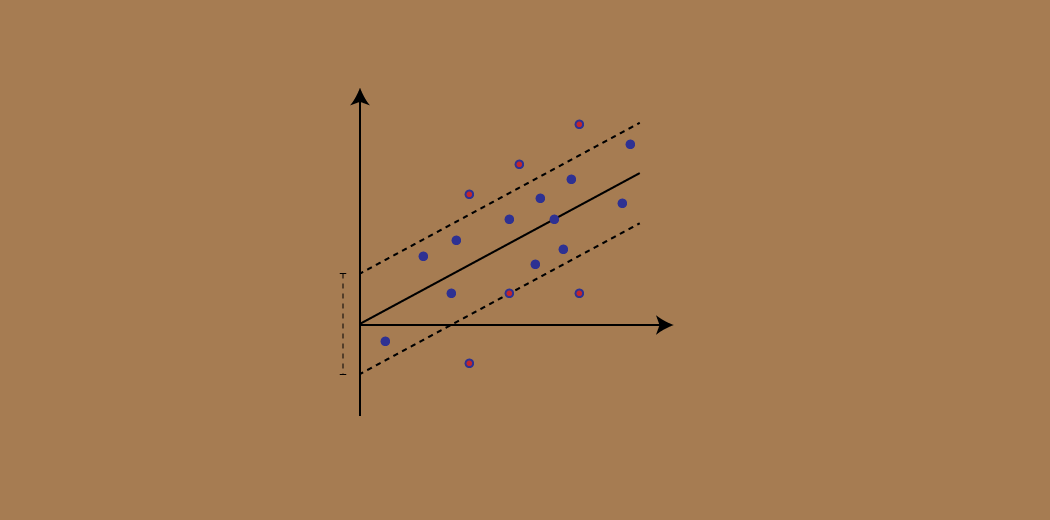
Consider these two red lines as the decision boundary and the green line as the hyperplane. Our objective, when we are moving on with SVR, is to basically consider the points that are within the decision boundary line. Our best fit line is the hyperplane that has a maximum number of points.
The first thing that we’ll understand is what is the decision boundary (the danger red line above!). Consider these lines as being at any distance, say ‘a’, from the hyperplane. So, these are the lines that we draw at distance ‘+a’ and ‘-a’ from the hyperplane. This ‘a’ in the text is basically referred to as epsilon.
Assuming that the equation of the hyperplane is as follows:
Y = wx+b (equation of hyperplane)
Then the equations of decision boundary become:
wx+b= +a wx+b= -a
Thus, any hyperplane that satisfies our SVR should satisfy:
-a < Y- wx+b < +a
Our main aim here is to decide a decision boundary at ‘a’ distance from the original hyperplane such that data points closest to the hyperplane or the support vectors are within that boundary line.
Hence, we are going to take only those points that are within the decision boundary and have the least error rate, or are within the Margin of Tolerance. This gives us a better fitting model.
Implementing Support Vector Regression (SVR) in Python
Time to put on our coding hats! In this section, we’ll understand the use of Support Vector Regression with the help of a dataset. Here, we have to predict the salary of an employee given a few independent variables. A classic HR analytics project!
Step 1: Importing the libraries
Step 2: Reading the dataset
Step 3: Feature Scaling
A real-world dataset contains features that vary in magnitudes, units, and range. I would suggest performing normalization when the scale of a feature is irrelevant or misleading.
Feature Scaling basically helps to normalize the data within a particular range. Normally several common class types contain the feature scaling function so that they make feature scaling automatically. However, the SVR class is not a commonly used class type so we should perform feature scaling using Python.
Step 4: Fitting SVR to the dataset
Kernel is the most important feature. There are many types of kernels – linear, Gaussian, etc. Each is used depending on the dataset. To learn more about this, read this: Support Vector Machine (SVM) in Python and R
Step 5. Predicting a new result
So, the prediction for y_pred(6, 5) will be 170,370.
Step 6. Visualizing the SVR results (for higher resolution and smoother curve)
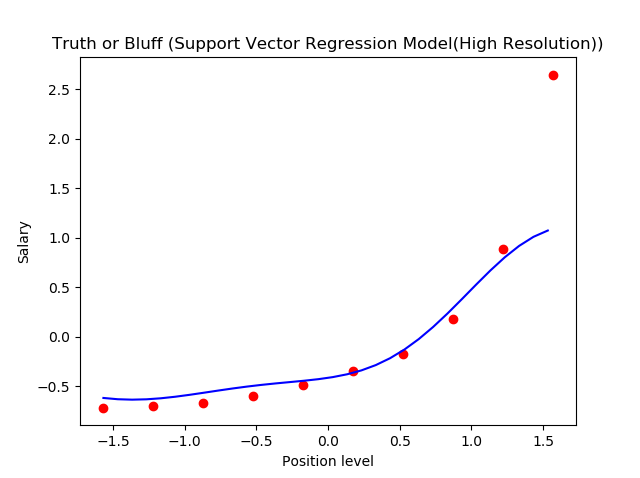
This is what we get as output- the best fit line that has a maximum number of points. Quite accurate!
Conclusion
We can think of Support Vector Regression as the counterpart of SVM for regression problems. SVR acknowledges the presence of non-linearity in the data and provides a proficient prediction model.
I would love to hear your thoughts and ideas around using SVR for regression analysis. Connect with me in the comments section below and let’s ideate!
Frequently Asked Questions
A. SVM (Support Vector Machines) is a classification algorithm that separates data points into different classes with a hyperplane while minimizing the misclassification error. On the other hand, SVR (Support Vector Regression) is a regression algorithm that finds a hyperplane that best fits data points in a continuous space while minimizing the prediction error. SVM is used for categorical target variables, while SVR is used for continuous target variables.
A. SVM regression or Support Vector Regression (SVR) is a machine learning algorithm used for regression analysis. It is different from traditional linear regression methods as it finds a hyperplane that best fits the data points in a continuous space, instead of fitting a line to the data points.
The SVR algorithm aims to find the hyperplane that passes through as many data points as possible within a certain distance, called the margin. This approach helps to reduce the prediction error and allows SVR to handle non-linear relationships between input variables and the target variable using a kernel function. As a result, SVM regression is a powerful tool for regression tasks where there may be complex relationships between the input variables and the target variable.
A. SVM regression or Support Vector Regression (SVR) has a wide range of applications in various fields. It is commonly used in finance for predicting stock prices, in engineering for predicting machine performance, and in bioinformatics for predicting protein structures. SVM regression is also used in natural language processing for text classification and sentiment analysis. Additionally, it is used in image processing for object recognition and in healthcare for predicting medical outcomes. Overall, SVM regression is a versatile algorithm that can be used in many domains for making accurate predictions.
Aspiring Data Scientist with a passion to play and wrangle with data and get insights from it to help the community know the upcoming trends and products for their better future.With an ambition to develop product used by millions which makes their life easier and better.









Thanks for the article,it gave an intuitive understanding about SVR It would be really helpful if you could also include the dataset,used for the demonstration.
The code is completely irrelevant to the dataset shown in the picture. Also this code is from Udemy course by Kiril Ermenko. Atleast give them the credit when you have plagiarized the code and content of the tutorial from elsewhere.
Thank you for this article, is very clear and helpful. However, I have one question on the example you gave. And My question concern characteristics variables (X) and target variables (Y). How to use SVR if we have more then one (1) characteristic variables. Like if we want to consider Salary against position level and age?
Why we used inverse transform in step 5 line 2