Note: This article was originally published on May 29, 2017, and updated on July 24, 2020
You can learn and practice a concept in two ways:
I prefer Option 2 and take that approach to learn any new topic. I might not be able to tell you the entire math behind an algorithm, but I can tell you the intuition. I can tell you the best scenarios to apply an algorithm based on my experiments and understanding.
In my interactions with people, I find that people don’t take time to develop this intuition and hence they struggle to apply things in the right manner.
In this article, I will discuss the building block of neural networks from scratch and focus more on developing this intuition to apply Neural networks. We will code in both “Python” and “R”. By the end of this article, you will understand how Neural networks work, how do we initialize weights and how do we update them using back-propagation.
Let’s start.
In case you want to learn this in a course format, check out our course Fundamentals of Deep Learning
In case you have been a developer or seen one work – you know how it is to search for bugs in code. You would fire various test cases by varying the inputs or circumstances and look for the output. Further, the change in output provides you a hint on where to look for the bug – which module to check, which lines to read. Once you find it, you make the changes and the exercise continues until you have the right code/application.
Neural networks work in a very similar manner. It takes several inputs, processes it through multiple neurons from multiple hidden layers, and returns the result using an output layer. This result estimation process is technically known as “Forward Propagation“.
Next, we compare the result with actual output. The task is to make the output to the neural network as close to the actual (desired) output. Each of these neurons is contributing some error to the final output. How do you reduce the error?
We try to minimize the value/ weight of neurons that are contributing more to the error and this happens while traveling back to the neurons of the neural network and finding where the error lies. This process is known as “Backward Propagation“.
In order to reduce this number of iterations to minimize the error, the neural networks use a common algorithm known as “Gradient Descent”, which helps to optimize the task quickly and efficiently.
That’s it – this is how Neural networks work! I know this is a very simple representation, but it would help you understand things in a simple manner.
Just like atoms form the basics of any material on earth – the basic forming unit of a neural network is a perceptron. So, what is a perceptron?
A perceptron can be understood as anything that takes multiple inputs and produces one output. For example, look at the image below.
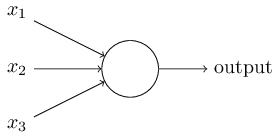
Perceptron
The above structure takes three inputs and produces one output. The next logical question is what is the relationship between input and output? Let us start with basic ways and build on to find more complex ways.
Below, I have discussed three ways of creating input-output relationships:
But, all of this is still linear which is what perceptrons used to be. But that was not as much fun. So, people thought of evolving a perceptron to what is now called as an artificial neuron. A neuron applies non-linear transformations (activation function) to the inputs and biases.
Activation Function takes the sum of weighted input (w1*x1 + w2*x2 + w3*x3 + 1*b) as an argument and returns the output of the neuron. 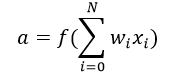 In the above equation, we have represented 1 as x0 and b as w0.
In the above equation, we have represented 1 as x0 and b as w0.
Moreover, the activation function is mostly used to make a non-linear transformation that allows us to fit nonlinear hypotheses or to estimate the complex functions. There are multiple activation functions, like “Sigmoid”, “Tanh”, ReLu and many others.
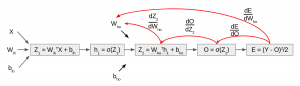
Till now, we have computed the output and this process is known as “Forward Propagation“. But what if the estimated output is far away from the actual output (high error). In the neural network what we do, we update the biases and weights based on the error. This weight and bias updating process is known as “Back Propagation“.
Back-propagation (BP) algorithms work by determining the loss (or error) at the output and then propagating it back into the network. The weights are updated to minimize the error resulting from each neuron. Subsequently, the first step in minimizing the error is to determine the gradient (Derivatives) of each node w.r.t. the final output. To get a mathematical perspective of the Backward propagation, refer to the below section.
This one round of forwarding and backpropagation iteration is known as one training iteration aka “Epoch“.
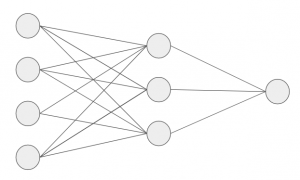
Now, let’s move on to the next part of Multi-Layer Perceptron. So far, we have seen just a single layer consisting of 3 input nodes i.e x1, x2, and x3, and an output layer consisting of a single neuron. But, for practical purposes, the single-layer network can do only so much. An MLP consists of multiple layers called Hidden Layers stacked in between the Input Layer and the Output Layer as shown below.
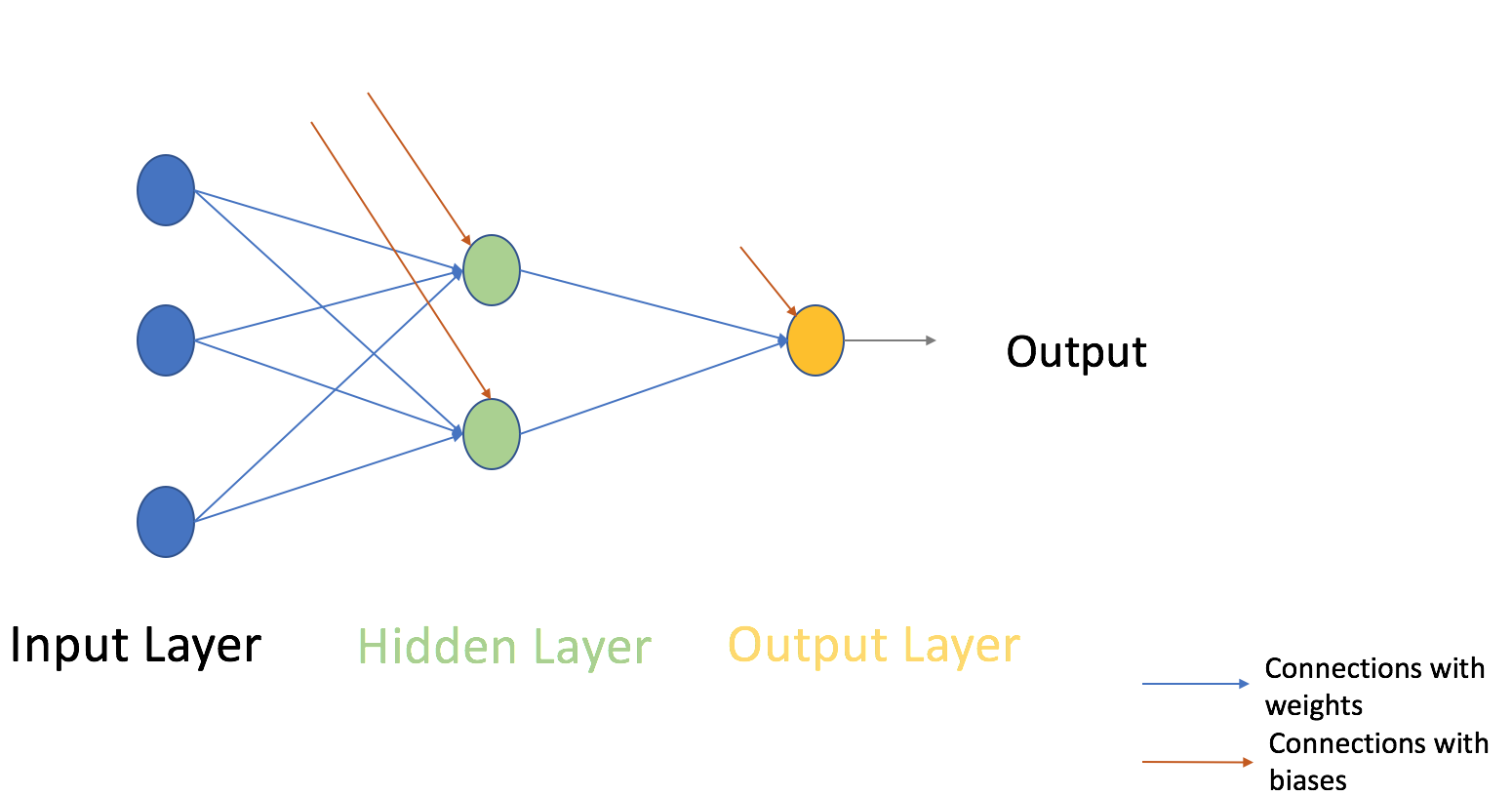
The image above shows just a single hidden layer in green but in practice can contain multiple hidden layers. In addition, another point to remember in case of an MLP is that all the layers are fully connected i.e every node in a layer(except the input and the output layer) is connected to every node in the previous layer and the following layer.
Let’s move on to the next topic which is a training algorithm for neural networks (to minimize the error). Here, we will look at the most common training algorithms known as Gradient descent.
Both variants of Gradient Descent perform the same work of updating the weights of the MLP by using the same updating algorithm but the difference lies in the number of training samples used to update the weights and biases.
Full Batch Gradient Descent Algorithm as the name implies uses all the training data points to update each of the weights once whereas Stochastic Gradient uses 1 or more(sample) but never the entire training data to update the weights once.
Let us understand this with a simple example of a dataset of 10 data points with two weights w1 and w2.
Full Batch: You use 10 data points (entire training data) and calculate the change in w1 (Δw1) and change in w2(Δw2) and update w1 and w2.
SGD: You use 1st data point and calculate the change in w1 (Δw1) and change in w2(Δw2) and update w1 and w2. Next, when you use 2nd data point, you will work on the updated weights
For a more in-depth explanation of both the methods, you can have a look at this article.
Let’s look at the step by step building methodology of Neural Network (MLP with one hidden layer, similar to above-shown architecture). At the output layer, we have only one neuron as we are solving a binary classification problem (predict 0 or 1). We could also have two neurons for predicting each of both classes.
Firstly look at the broad steps:
0.) We take input and output
1.) Then we initialize weights and biases with random values (This is one-time initiation. In the next iteration, we will use updated weights, and biases). Let us define:
2.) Then we take matrix dot product of input and weights assigned to edges between the input and hidden layer then add biases of the hidden layer neurons to respective inputs, this is known as linear transformation:
hidden_layer_input= matrix_dot_product(X,wh) + bh
3) Perform non-linear transformation using an activation function (Sigmoid). Sigmoid will return the output as 1/(1 + exp(-x)).
hiddenlayer_activations = sigmoid(hidden_layer_input)
4.) Then perform a linear transformation on hidden layer activation (take matrix dot product with weights and add a bias of the output layer neuron) then apply an activation function (again used sigmoid, but you can use any other activation function depending upon your task) to predict the output
output_layer_input = matrix_dot_product (hiddenlayer_activations * wout ) + bout
output = sigmoid(output_layer_input)
All the above steps are known as “Forward Propagation“
5.) Compare prediction with actual output and calculate the gradient of error (Actual – Predicted). Error is the mean square loss = ((Y-t)^2)/2
E = y – output
6.) Compute the slope/ gradient of hidden and output layer neurons ( To compute the slope, we calculate the derivatives of non-linear activations x at each layer for each neuron). The gradient of sigmoid can be returned as x * (1 – x).
slope_output_layer = derivatives_sigmoid(output)
slope_hidden_layer = derivatives_sigmoid(hiddenlayer_activations)
7.) Then compute change factor(delta) at the output layer, dependent on the gradient of error multiplied by the slope of output layer activation
d_output = E * slope_output_layer
8.) At this step, the error will propagate back into the network which means error at the hidden layer. For this, we will take the dot product of the output layer delta with the weight parameters of edges between the hidden and output layer (wout.T).
Error_at_hidden_layer = matrix_dot_product(d_output, wout.Transpose)
9.) Compute change factor(delta) at hidden layer, multiply the error at hidden layer with slope of hidden layer activation
d_hiddenlayer = Error_at_hidden_layer * slope_hidden_layer
10.) Then update weights at the output and hidden layer: The weights in the network can be updated from the errors calculated for training example(s).
wout = wout + matrix_dot_product(hiddenlayer_activations.Transpose, d_output)*learning_rate
wh = wh + matrix_dot_product(X.Transpose,d_hiddenlayer)*learning_rate
learning_rate: The amount that weights are updated is controlled by a configuration parameter called the learning rate)
11.) Finally, update biases at the output and hidden layer: The biases in the network can be updated from the aggregated errors at that neuron.
bh = bh + sum(d_hiddenlayer, axis=0) * learning_rate
bout = bout + sum(d_output, axis=0)*learning_rate
Steps from 5 to 11 are known as “Backward Propagation“
One forward and backward propagation iteration is considered as one training cycle. As I mentioned earlier, When do we train second time then update weights and biases are used for forward propagation.
Above, we have updated the weight and biases for the hidden and output layer and we have used a full batch gradient descent algorithm.
We will repeat the above steps and visualize the input, weights, biases, output, error matrix to understand the working methodology of Neural Network (MLP).
Note:
Step 0: Read input and output

Step 1: Initialize weights and biases with random values (There are methods to initialize weights and biases but for now initialize with random values)

Step 2: Calculate hidden layer input:
hidden_layer_input= matrix_dot_product(X,wh) + bh
 Step 3: Perform non-linear transformation on hidden linear input
Step 3: Perform non-linear transformation on hidden linear input
hiddenlayer_activations = sigmoid(hidden_layer_input)
 Step 4: Perform linear and non-linear transformation of hidden layer activation at output layer
Step 4: Perform linear and non-linear transformation of hidden layer activation at output layer
output_layer_input = matrix_dot_product (hiddenlayer_activations * wout ) + bout
output = sigmoid(output_layer_input)
 Step 5: Calculate gradient of Error(E) at output layer
Step 5: Calculate gradient of Error(E) at output layer
E = y-output
 Step 6: Compute slope at output and hidden layer
Step 6: Compute slope at output and hidden layer
Slope_output_layer= derivatives_sigmoid(output)
Slope_hidden_layer = derivatives_sigmoid(hiddenlayer_activations)
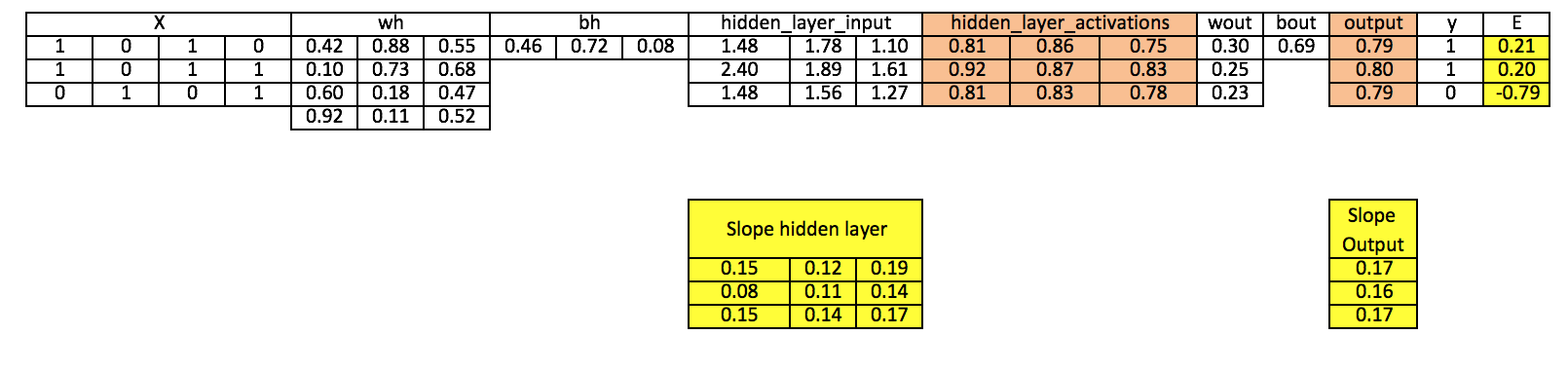 Step 7: Compute delta at output layer
Step 7: Compute delta at output layer
d_output = E * slope_output_layer*lr
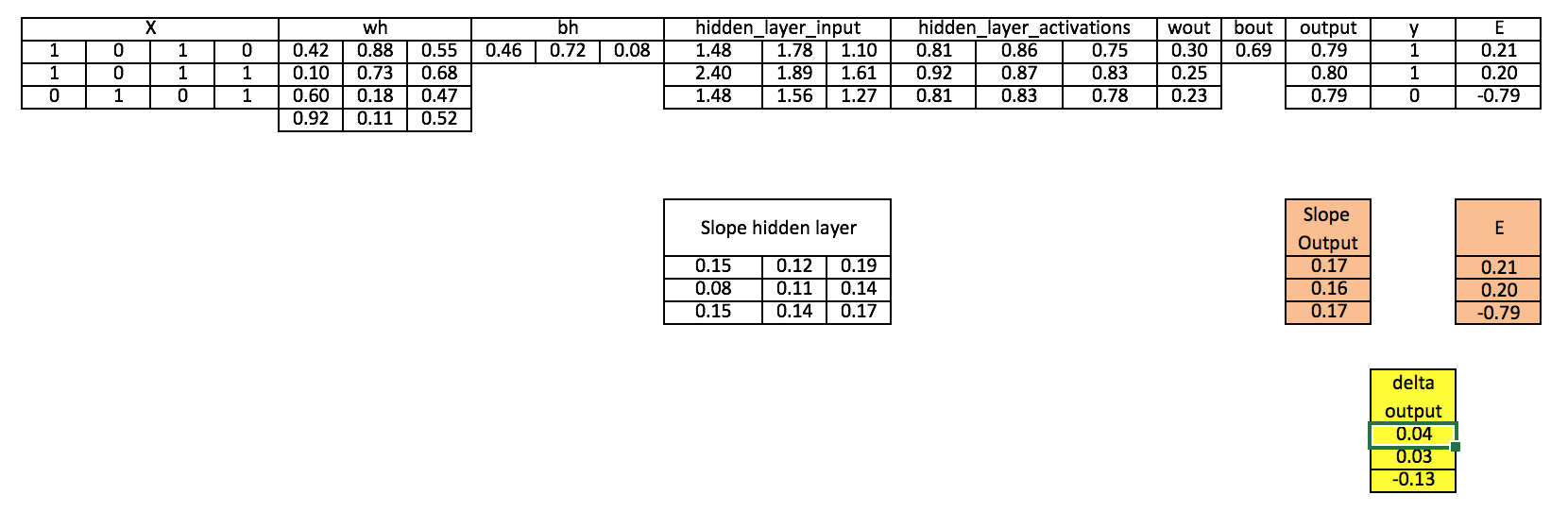
Step 8: Calculate Error at the hidden layer
Error_at_hidden_layer = matrix_dot_product(d_output, wout.Transpose)
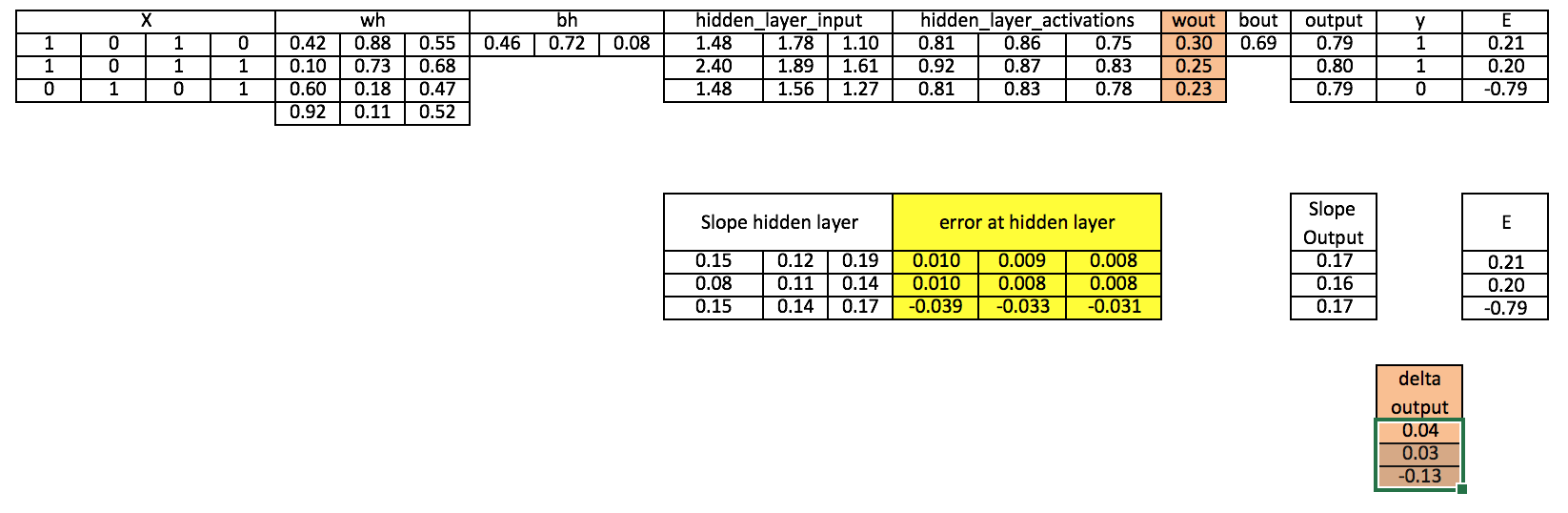 Step 9: Compute delta at hidden layer
Step 9: Compute delta at hidden layer
d_hiddenlayer = Error_at_hidden_layer * slope_hidden_layer
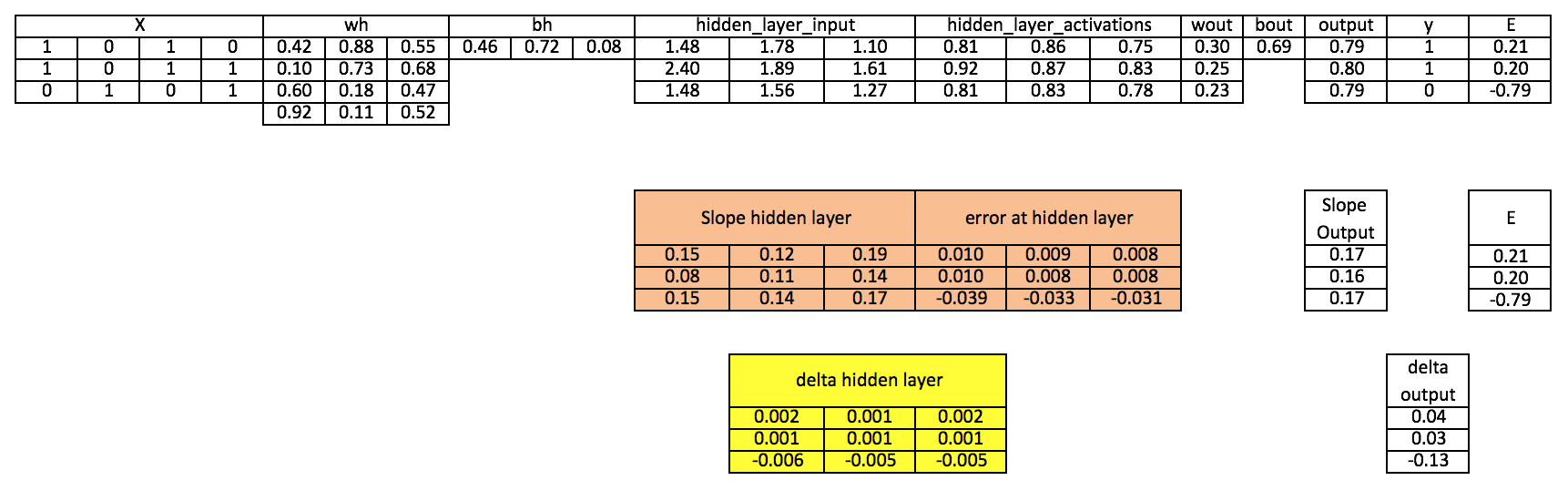
Step 10: Update weight at both output and hidden layer
wout = wout + matrix_dot_product(hiddenlayer_activations.Transpose, d_output)*learning_rate
wh = wh+ matrix_dot_product(X.Transpose,d_hiddenlayer)*learning_rate
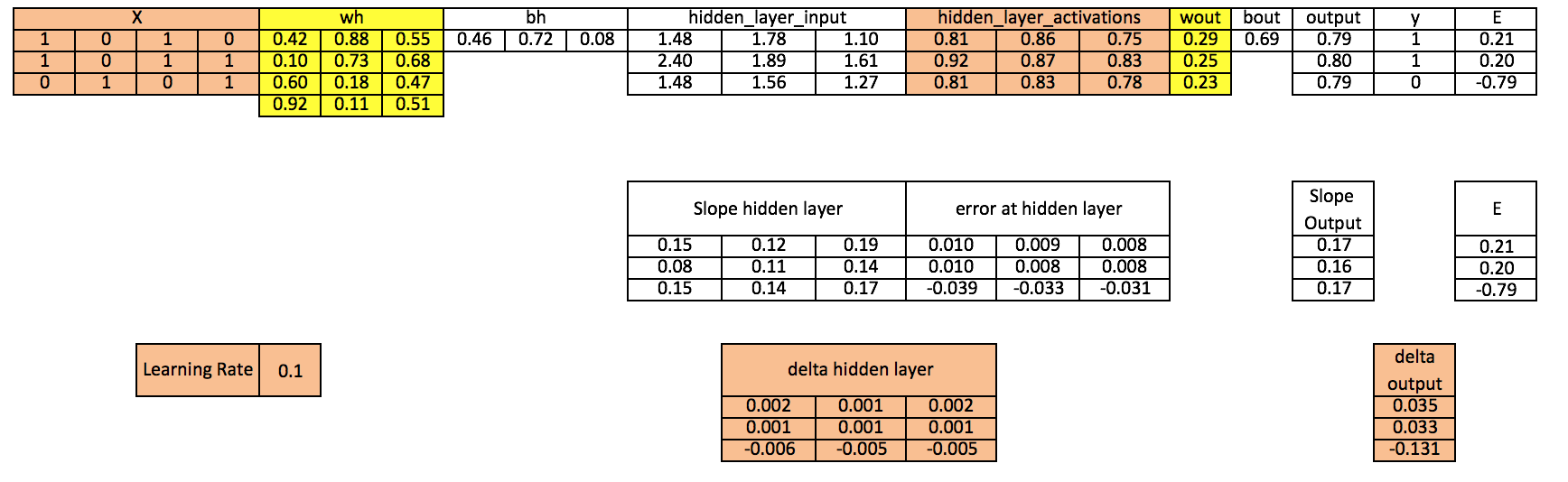
Step 11: Update biases at both output and hidden layer
bh = bh + sum(d_hiddenlayer, axis=0) * learning_rate
bout = bout + sum(d_output, axis=0)*learning_rate
Above, you can see that there is still a good error not close to the actual target value because we have completed only one training iteration. If we will train the model multiple times then it will be a very close actual outcome. I have completed thousands iteration and my result is close to actual target values ([[ 0.98032096] [ 0.96845624] [ 0.04532167]]).
# input matrix
X=matrix(c(1,0,1,0,1,0,1,1,0,1,0,1),nrow = 3, ncol=4,byrow = TRUE)
# output matrix
Y=matrix(c(1,1,0),byrow=FALSE)
#sigmoid function
sigmoid<-function(x){
1/(1+exp(-x))
}
# derivative of sigmoid function
derivatives_sigmoid<-function(x){
x*(1-x)
}
# variable initialization
epoch=5000
lr=0.1
inputlayer_neurons=ncol(X)
hiddenlayer_neurons=3
output_neurons=1
#weight and bias initialization
wh=matrix( rnorm(inputlayer_neurons*hiddenlayer_neurons,mean=0,sd=1), inputlayer_neurons, hiddenlayer_neurons)
bias_in=runif(hiddenlayer_neurons)
bias_in_temp=rep(bias_in, nrow(X))
bh=matrix(bias_in_temp, nrow = nrow(X), byrow = FALSE)
wout=matrix( rnorm(hiddenlayer_neurons*output_neurons,mean=0,sd=1), hiddenlayer_neurons, output_neurons)
bias_out=runif(output_neurons)
bias_out_temp=rep(bias_out,nrow(X))
bout=matrix(bias_out_temp,nrow = nrow(X),byrow = FALSE)
# forward propagation
for(i in 1:epoch){
hidden_layer_input1= X%*%wh
hidden_layer_input=hidden_layer_input1+bh
hidden_layer_activations=sigmoid(hidden_layer_input)
output_layer_input1=hidden_layer_activations%*%wout
output_layer_input=output_layer_input1+bout
output= sigmoid(output_layer_input)
# Back Propagation
E=Y-output
slope_output_layer=derivatives_sigmoid(output)
slope_hidden_layer=derivatives_sigmoid(hidden_layer_activations)
d_output=E*slope_output_layer
Error_at_hidden_layer=d_output%*%t(wout)
d_hiddenlayer=Error_at_hidden_layer*slope_hidden_layer
wout= wout + (t(hidden_layer_activations)%*%d_output)*lr
bout= bout+rowSums(d_output)*lr
wh = wh +(t(X)%*%d_hiddenlayer)*lr
bh = bh + rowSums(d_hiddenlayer)*lr
}
output
Now that you have gone through a basic implementation of numpy from scratch in both Python and R, we will dive deep into understanding each code block and try to apply the same code on a different dataset. We will also visualize how our model is working, by “debugging” it step by step using the interactive environment of a jupyter notebook and using basic data science tools such as numpy and matplotlib. So let’s get started!
The first thing we will do is to import the libraries mentioned before, namely numpy and matplotlib. Also, as we will be working with the jupyter notebook IDE, we will set inline plotting of graphs using the magic function %matplotlib inline
Let’s check the versions of the libraries we are using
Version of numpy: 1.18.1
and the same for matplotlib
Version of matplotlib: 3.1.3
Also, lets set the random seed parameter to a specific number (let’s say 42 (as we already know that is the answer to everything!)) so that the code we run gives us the same output every time we run (hopefully!)
Now the next step is to create our input. Firstly, let’s take a dummy dataset, where only the first column is a useful column, whereas the rest may or may not be useful and can be a potential noise.
This is the output we get from running the above code
Now as you might remember, we have to take the transpose of input so that we can train our network. Let’s do that quickly
Input in matrix form: [[1 1 0] [0 0 1] [0 1 0] [0 1 1]] Shape of Input Matrix: (4, 3)
Now let’s create our output array and transpose that too
Actual Output: [[1] [1] [0]] Output in matrix form: [[1 1 0]] Shape of Output: (1, 3)
Now that our input and output data is ready, let’s define our neural network. We will define a very simple architecture, having one hidden layer with just three neurons
Then, we will initialize the weights for each neuron in the network. The weights we create have values ranging from 0 to 1, which we initialize randomly at the start.
For simplicity, we will not include bias in the calculations, but you can check the simple implementation we did before to see how it works for the bias term
Let’s print the shapes of these numpy arrays for clarity
After this, we will define our activation function as sigmoid, which we will use in both the hidden layer and output layer of the network
And then, we will implement our forward pass, first to get the hidden layer activations and then for the output layer. Our forward pass would look something like this
Let’s see what our untrained model gives as an output.
We get an output for each sample of the input data. In this case, let’s calculate the error for each sample using the squared error loss
We get an output like this
array([[0.05013458, 0.03727248, 0.25388062]])
We have completed our forward propagation step and got the error. Now let’s do a backward propagation to calculate the error with respect to each weight of the neuron and then update these weights using simple gradient descent.
Firstly we will calculate the error with respect to weights between the hidden and output layers. Essentially, we will do an operation such as this
where to calculate this, the following would be our intermediate steps using the chain rule
Let’s perform the operations
Now, let’s check the shapes of the intermediate operations.
What we want is an output shape like this
Now as we saw before, we can define this operation formally using this equation
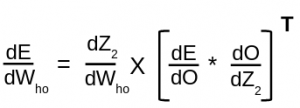
Let’s perform the steps
We get the output as expected.
Further, let’s perform the same steps for calculating the error with respect to weights between input and hidden – like this
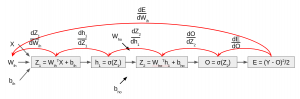
So by chain rule, we will calculate the following intermediate steps,
Let’s print the shapes of these intermediate arrays
(1, 3) (1, 3) (3, 1) (3, 3) (4, 3)
But what we want is an array of shape this
So we will combine them using the equation
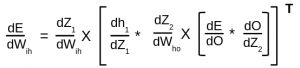
So that is the output we want. Lets quickly check the shape of the resultant array
Now the next step is to update the parameters. For this, we will use vanilla gradient descent update function, which is as follows
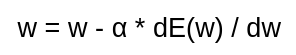
Firstly define our alpha parameter, i.e. the learning rate as 0.01
We also print the initial weights before the update
and update the weights
Then, we check the weights again to see if they have been updated
Now, this is just one iteration (or epoch) of the forward and backward pass. We have to do it multiple times to make our model perform better. Let’s perform the steps above again for 1000 epochs
We get an output like this, which is a debugging step we did to check error at every hundredth epoch
Our model seems to be performing better and better as the training continues. Let’s check the weights after the training is done
And also plot a graph to visualize how the training went
One final thing we will do is to check how close the predictions are to our actual output
Pretty close!
Further, the next thing we will do is to train our model on a different dataset, and visualize the performance by plotting a decision boundary after training.
Let’s get on to it!
We get an output like this
We will normalize the input so that our model trains faster
Now we will define our network. We will update the following three hyperparameters, namely
This is the error we get after each thousand of the epoch
Error at epoch 0 is 0.23478 Error at epoch 1000 is 0.25000 Error at epoch 2000 is 0.25000 Error at epoch 3000 is 0.25000 Error at epoch 4000 is 0.05129 Error at epoch 5000 is 0.02163 Error at epoch 6000 is 0.01157 Error at epoch 7000 is 0.00775 Error at epoch 8000 is 0.00689 Error at epoch 9000 is 0.07556
And plotting it gives an output like this
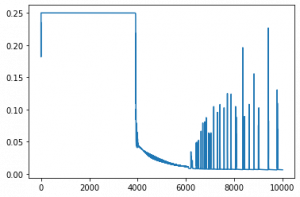
Now, if we check the predictions and output manually, they seem pretty close
Next, let’s visualize the performance by plotting the decision boundary. It’s ok if you don’t follow the code below, you can use it as-is for now. If you are curious, do post it in the comment section below
which gives us an output like this
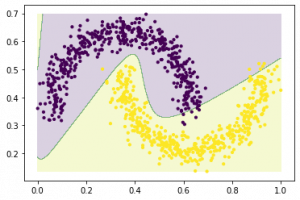
which lets us know how adept our neural network is at trying to find the pattern in the data and then classifying them accordingly.
Here’s an exercise for you – Try to take the same implementation we did, and implement in on a “blobs” dataset using scikit-learn The data would look similar to this
Do share your results with us!
Let Wi be the weights between the input layer and the hidden layer. Wh be the weights between the hidden layer and the output layer.
Now, h=σ (u)= σ (WiX), i.e h is a function of u and u is a function of Wi and X. here we represent our function as σ
Y= σ (u’)= σ (Whh), i.e Y is a function of u’ and u’ is a function of Wh and h.
We will be constantly referencing the above equations to calculate partial derivatives.
We are primarily interested in finding two terms, ∂E/∂Wi and ∂E/∂Wh i.e change in Error on changing the weights between the input and the hidden layer and change in error on changing the weights between the hidden layer and the output layer.
But to calculate both these partial derivatives, we will need to use the chain rule of partial differentiation since E is a function of Y and Y is a function of u’ and u’ is a function of Wi.
Let’s put this property to good use and calculate the gradients.
∂E/∂Wh = (∂E/∂Y).( ∂Y/∂u’).( ∂u’/∂Wh), ……..(1)
We know E is of the form E=(Y-t)2/2.
So, (∂E/∂Y)= (Y-t)
Now, σ is a sigmoid function and has an interesting differentiation of the form σ(1- σ). I urge the readers to work this out on their side for verification.
So, (∂Y/∂u’)= ∂( σ(u’)/ ∂u’= σ(u’)(1- σ(u’)).
But, σ(u’)=Y, So,
(∂Y/∂u’)=Y(1-Y)
Now, ( ∂u’/∂Wh)= ∂( Whh)/ ∂Wh = h
Replacing the values in equation (1) we get,
∂E/∂Wh = (Y-t). Y(1-Y).h
So, now we have computed the gradient between the hidden layer and the output layer. It is time we calculate the gradient between the input layer and the hidden layer.
∂E/∂Wi =(∂ E/∂ h). (∂h/∂u).( ∂u/∂Wi)
But, (∂ E/∂ h) = (∂E/∂Y).( ∂Y/∂u’).( ∂u’/∂h). Replacing this value in the above equation we get,
∂E/∂Wi =[(∂E/∂Y).( ∂Y/∂u’).( ∂u’/∂h)]. (∂h/∂u).( ∂u/∂Wi)……………(2)
So, What was the benefit of first calculating the gradient between the hidden layer and the output layer?
As you can see in equation (2) we have already computed ∂E/∂Y and ∂Y/∂u’ saving us space and computation time. We will come to know in a while why is this algorithm called the backpropagation algorithm.
Let us compute the unknown derivatives in equation (2).
∂u’/∂h = ∂(Whh)/ ∂h = Wh
∂h/∂u = ∂( σ(u)/ ∂u= σ(u)(1- σ(u))
But, σ(u)=h, So,
(∂Y/∂u)=h(1-h)
Now, ∂u/∂Wi = ∂(WiX)/ ∂Wi = X
Replacing all these values in equation (2) we get,
∂E/∂Wi = [(Y-t). Y(1-Y).Wh].h(1-h).X
So, now since we have calculated both the gradients, the weights can be updated as
Wh = Wh + η . ∂E/∂Wh
Wi = Wi + η . ∂E/∂Wi
Where η is the learning rate.
So coming back to the question: Why is this algorithm called Back Propagation Algorithm?
The reason is: If you notice the final form of ∂E/∂Wh and ∂E/∂Wi , you will see the term (Y-t) i.e the output error, which is what we started with and then propagated this back to the input layer for weight updation.
So, where does this mathematics fit into the code?
hiddenlayer_activations=h
E= Y-t
Slope_output_layer = Y(1-Y)
lr = η
slope_hidden_layer = h(1-h)
wout = Wh
Now, you can easily relate the code to the mathematics.
To summarize, this article is focused on building Neural Networks from scratch and understanding its basic concepts. I hope now you understand the working of neural networks. Such as how does forward and backward propagation work, optimization algorithms (Full Batch and Stochastic gradient descent), how to update weights and biases, visualization of each step in Excel, and on top of that code in python and R.
Therefore, in my upcoming article, I’ll explain the applications of using Neural Networks in Python and solving real-life challenges related to:
I enjoyed writing this article and would love to learn from your feedback. Did you find this article useful? I would appreciate your suggestions/feedback. Please feel free to ask your questions through the comments below.
Sunil Ray is Chief Content Officer at Analytics Vidhya, India's largest Analytics community. I am deeply passionate about understanding and explaining concepts from first principles. In my current role, I am responsible for creating top notch content for Analytics Vidhya including its courses, conferences, blogs and Competitions. I thrive in fast paced environment and love building and scaling products which unleash huge value for customers using data and technology. Over the last 6 years, I have built the content team and created multiple data products at Analytics Vidhya. Prior to Analytics Vidhya, I have 7+ years of experience working with several insurance companies like Max Life, Max Bupa, Birla Sun Life & Aviva Life Insurance in different data roles. Industry exposure: Insurance, and EdTech Major capabilities: Content Development, Product Management, Analytics, Growth Strategy.
Lorem ipsum dolor sit amet, consectetur adipiscing elit,








Thank you very much.
Amazing article.. Very well written and easy to understand the basic concepts.. Thank you for the hard work.
Thanks, for sharing this. Very nice article.
Nice article Sunil! Appreciate your continued research on the same. One correction though... Now... hiddenlayer_neurons = 3 #number of hidden layers Should be... hiddenlayer_neurons = 3 #number of neurons at hidden layers
Thanks Srinivas! Have updated the comment.
Very interesting!
Very well written... I completely agree with you about learning by working on a problem
Thanks for great article! Probably, it should be "Update bias at both output and hidden layer" in the Step 11 of the Visualization of steps for Neural Network methodology
Thanks Andrei, I'm updating only biases at step 11. Regards, Sunil
Wonderful explanation. This is an excellent article. I did not come across such a lucid explanation of NN so far.
Thanks Sasikanth! Regards, Sunil
Great article! There is a small typo: In the section where you describe the three ways of creating input output relationships you define "x2" twice - one of them should be "x3" instead :) Keep up the great work!
Thanks Robert for highlighting the typo!
Explained in very lucid manner. Thanks for this wonderful article.
Very Interesting! Nice Explanation
Awesome Sunil. Its a great job. Thanks a lot for making such a neat and clear page for NN, very much useful for beginners.
Well written article. With step by step explaination , it was easier to understand forward and backward propogations.. is there any functions in scikit learn for neural networks?
Thanks Praveen! You can look at this (http://scikit-learn.org/stable/modules/classes.html#module-sklearn.neural_network). Regards, Sunil
Hello Sunil, Please refer below, "To get a mathematical perspective of the Backward propagation, refer below section. This one round of forward and back propagation iteration is known as one training iteration aka “Epoch“. " I'm kind of lost there, did you already explain something?( about back prop) , Is there any missing information? Thanks
Great article Sunil! I have one doubt. Why you applied linear to nonlinear transformation in the middle of the process? Is it necessary!!
Thanks a lot, Sunil, for such a well-written article. Particularly, I liked the visualization section, in which each step is well explained by an example. I just have a suggestion: if you add the architecture of MLP in the beginning of the visualization section it would help a lot. Because in the beginning I thought you are addressing the same architecture plotted earlier, in which there were 2 hidden units, not 3 hidden units. Thanks a lot once more!
Nice Article :-)
Very well written article. Thanks for your efforts.
Great article. For a beginner like me, it was fully understandable. Keep up the good work.
Great Explanation....on Forward and Backward Propagation
Thanks Preeti Regards, Sunil
I really like how you explain this. Very well written. Thank you
Thanks Gino
I am 63 years old and retired professor of management. Thanks for your lucid explanations. I am able to learn. My blessings are to you.
Thanks Professor Regards, Sunil
Dear Author this is a great article. Infact I got more clarity. I just wanted to say, using full batch Gradient Descent (or SGD) we need to tune the learning rate as well, but if we use Nesterovs Gradient Descent, it would converge faster and produce quick results.
good information thanks sunil
can you Explain how to train and test the above network. When i am loading the text through file its giving shape error.
Hey sunil, Can you also follow up with an article on rnn and lstm, with your same visual like tabular break down? It was fun and would complement a good nn understanding. Thanks
A pleasant reading. Thanks for sharing.
Thanks for the detailed explanation!
. I know the math but not the programming..part. Thanks Sunil for a great and easy to understand article. I am a Phd in OR with over 25 years of experience in business analytics modeling. I would like to have your collaboration on implementing (coding/testing) a couple of new algorithms (NN , clustering/classification), that we can publish together.. Please let me know if you are interested.. [email protected]
Hello, This article was really helpful. While I understood the "Mathematical Perspective of Back Propagation Algorithm" part I am having difficulty in implementing it in matrix form. I am confused as to when to use the matrix dot product, when to use the element wise product and when to take the transpose after a derivative. Is there a particular mathematical field that deals with functions with matrix variables and its derivatives?
I want to hug you. I still have to read this again but machine learning algorithms have been shrouded in mystery before seeing this article. Thank you for unveiling it good friend.
Your article is truly amazing and helped clarify alot. So thank you very much! However I am still very confused with step 6. You write that: slope_output_layer = derivatives_sigmoid(output) However shouldn't this be the following: slope_output_layer = derivatives_sigmoid(output_layer_input) Even then you say the derivative of the sigmoid function (let's call it f) is x(1-x) but in fact it's actually f'(x) = f(x)(1-f(x)). These two things are really confusing me. What am I missing? Hopefully it's nothing too fundamental, if it is please guide me in the right direction! Thanks in advance. Max Smith
I am PHD student . I am working on image processing. it is great article for a beginner like me. Please help me more to guide in CNN for feature extraction, Thank you
Hello, I'm confused by 'bh'. The excel example shows only three values for 'bh', but the R script gives 9 values for 'bh'. Where do all the extra values come from? Is bias for only one neuron or is it for a particular input-neuron combination? Thanks.
Nice one.. Thanks lot for the work. i understood the neural network in a day
Yes, I found the information helpful in I understanding Neural Networks, I have and old book on the subject, the book I found was very hard to understand, I enjoyed reading most of your article, I found how you presented the information good, I understood the language you used in writing the material, Good Job!
Great Article. Thanks for sharing. I am stuck at Step 8 which calculates the error at hidden layer. what's the calculation behind it which generates a 3x3 matrix by multiplying delta output layer (3x1) and wout.T (1x3). I request you to please elaborate on it.
Nice article I get a lot through your written .As a fresh man in this field without any matematical background .can u suggest any material or online lecture about math in studying NN?
Hey SUNIL if I take "hiddenlayer_neurons = 100 " instead of "hiddenlayer_neurons = 3 " at the end out put is diffrent than the target for atleast one value ,like ouput is [1,1,1], so error is [0,0,-1] instead of [0,0,0] Would you Please explain why ?
Thanks for great article, it is useful to understand the basic learning about neural networks. Thnaks again for making great effort...
benefit a lot
recently i have been grasping knowledge on neural network and fortunately i understood i mostly everything on it but i was having trouble implementing it just because of less knowledge of numpy, i have searched many websites, read them thoroughly just to visualize flow of numpy maths, but just because of your explanation i manged to visualize numpy math and implemented nn successfully. Keep making more tutorial blogs, Thanks a lot
Thank you for this excellent plain-English explanation for amateurs.
Thank you, sir, very easy to understand and easy to practice.
Wonderful inspiration and great explanation. Thank you very much
I started Andrew NG's DL course on coursera. It is a great course but I wish he had included the intuitive description of forward prop, backward prop etc before he dives into derivative. I love his intuitive explanation of derivative though. Your post is simply awesome to get a first hand understanding of neural nets. Andrew's course and this post supplement each other very well. Thank you!
That is the simplest explain which i saw. Thx!
Hi! Very informative article ! I have a doubt though. Could you please elaborate a little on how should we choose the number of hidden layer neurons?
I'm too new to ML and Python , I'm trying to understand it by changing your dataset import pandas as pd df = pd.read_excel('D:\ML data\cereals.xlsx') print(df.head()) #Input array X = np.array(df.drop('rating',axis=1)) y = np.array(df['rating']) cereals.xlsx is consists of 75 rows and 6 columns I can retrieve X & y correctly but when I run inputlayer_neurons = X.shape[1] #number of features in data set hiddenlayer_neurons = 3 #number of hidden layers neurons output_neurons = 1 #number of neurons at output layer It returned error : File "C:/Users/paweedac/Python File/NNreadfromfile.py", line 49, in Error_at_hidden_layer = d_output.dot(wout.T) ValueError: shapes (75,75) and (1,3) not aligned: 75 (dim 1) != 1 (dim 0) I don't know which value it should be for hiddenlayer_neurons?
Hi Sunil, This was very insightful and one of the best articles on Neural Networks explanation. Many blogs are available on NN but they just confuse the reader as they progress. I found this to be exactly how I needed. Its midnight here and I don't feel like sleeping and want to keep on reading this :). Thanks for this article.
Thanks for the explanations, very clear
well done :D
Hi! Thanks for the article. I need some clarification though: for R implementation shouldn't it be colSums instead of rowSums when calculating bout and bh on backprop? In current implementation we are getting 3 different values for bout which should be just one (or all 3 should be the same) as we have only 1 output unit.
i want to make simple python ann code can u....
A unique approach to visualize MLP ! Thank you ...
I'm a beginner of this way. This article makes me understand about neural better. Thank you very much.
This is awesome explanation Sunil. The code and excel illustrations help a lot with really understanding the implementation. This helps unveil the mystery element from neural networks.
Thank you so much. This is what i wanted to know about NN.
Visualization is really very helpful. Thanks
Nice work. A suggestion, you could have saved a lot of computational time if the loop is removed and replaced by vectorized code.
Great article. I took time to udnerstand that you treat all examples at once, and somehow you sum the deltas for all examples (in line 57 "X.T.dot(d_hiddenlayer)"). So "lr" should maybe be divided by the number of examples otherwise it would grow as number of examples grows...
Great article. The way of explanation is unbelievable. Thank you for writing.
Appreciate.... Stay Blessed.
Thanks this was a very good read.
Hi, Thank you very much for that great article ! Two comments : First on the step 7 of the Visualization (with the cells), you put the formulat as: d_output = E * slope_output_layer*lr What is the *lr part ? Shouldn't just be: d_output = E * slope_output_layer Second: Still on the Visualization, you have a 4*3 Matrix. From what I understood, the number of columns corresponds to the number of neurons in your hidden layer. In your example you use 2 neurons in the hidden layer, so shouldn't be 2 columns in the visualization part? Maybe it was just taken as an illustration? Once again, thank you sooooo much for that, it is a great article! Regards
Hi Sunil, Tremendous article you wrote. It is very understandably written and gives all the parts in a clear context. Thank you for writing it. In trying to run the R-code I got two errors (which is few compared with most downloadable R-codes). These errors were: In E = Y-output I got: Error at_hiddenlayer=d_output%*%t(wout) d_hiddenlayer=Error at_hidden_layer*slope_hidden_layer Will you please tell me how to correct these 2 errors. The R-version I used was R i386 3.4.2. Thanks in advance. Thanks again for this fantastic article. It is a good start for further study and insight in Neural Networks.
Simply brilliant. Very nice piecemeal explanation. Thank you
Nice explaination of back propagation algorithm. Thanks for initiative and efforts. A small doubt: In step 8 of Visualization , are the calculated values of Error_at_hidden_layer adjusted? Some presented values differ from calculated values. Hence the query.
very clear! thank you!
Hello! Is it possible to get input and output like this?: X=np.array([[9,2,2],[6,1,11],[0,2,19],[8,1,12],[8,2,12],[7,1,16],[9,2,15],[6,1,18],[23,2,4],[7,1,18],[13,2,16],[28,1,5],[42,1,1],[21,2,11],[28,1,6]]) y=np.array([[1,0,0],[0,0,1],[1,0,0],[1,0,0],[1,0,0],[1,0,0],[0,0,1],[1,0,0],[0,1,0],[1,0,0],[0,1,0],[1,0,0],[0,0,1],[0,1,0],[0,0,1]]) i am using [1,0,0] when home won, [0,1,0] when was draw, and [0,0,1] when away won. I tried, but results aren't so good. And how to simulate this network? Cheers!
Thank you for your article. I have learned lots of DL from it.
Wow this was a awesome article, but you have only implemented with one hidden layer and i want to know how to implement with multiple with hidden layer.
I have been reading about NNs for about two years on my own now and this article is by far the simplest and clearest explanation I have ever read. Thank you so much for writing this and please keep doing what you’re doing! You are making the world a much better place.
using this process, how can i predict new data. thank you
Thank you very much. Very simple to understand ans easy to visualize. Please come up with more articles. Keep up the good work!
amazing article thank you very much !!!!
This is amazing Mr. Sunil. Although am not a professional but a student, this article was very helpful in understanding the concept and an amazing guide to implement neural networks in python.
Mr. Sunil, This was a great write-up and greatly improved my understanding of a simple neural network. In trying to replicate your Excel implementation, however, I believe I found an error in Step 6, which calculates the output delta. What you have highlighted is the derivative of the Sigmoid function acting on the first column of the output_layer_input (not shown in image), and not on the actual output, which is what should actually happen and does happen in your R and Python implementations. Thanks again!
Hi Sunil, I want to implement NN on hardware. Please suggest me how to start.
Hi, Thanks for posting this article. Please make some simple model training using tensorflow for particular purpose like seq2seq. I am novice about machine learning skill and hence can't understand this in detail. Thank you Ramprasad
This is very helpful, still there is a li'l issue with the code. You have used matrix multiplication for the mlp implementation. All the input instances are subjected to the same weight at a time. However Mlp doesnt work that way. We offer one input at a time, compare the ideal and obtained outputs, then we modify the weights accordingly. Next input is subjected to this modified weight. everything else is perfectly well.
Very well explanation. Everywhere NN is implemented using different libraries without defining fundamentals. Thanks a lot......
Very Simple Way But Best Explanation.
Thank You very much for explaining the concepts in a simple way.
Now only I understood the Neural Networks implementation. Thank you so much. Great efforts. Can you explain how CNN+LSTM implementation.
WOW WOW WOW!!!!!! Outstanding article. The visuals to explain the actual data and flow was very well thought out. It gives me the confidence to get my hands dirty at work with the Neural network.
Hi, First of all, thank you for the article, it's a very good resources to learn from. Second of all, I'm a newbie in NN world, and I'm learning from scratch. So, I have question that may sound dumb, but I'm really lost at it. The Question: At the "Visualization of steps for Neural Network methodology" section, at Step 0: - I see on the excel sheet, for the X table which is the input, there are 4 values for each data points: X or the Input y or the output 1 0 1 0 -> 1 1 0 1 1 -> 1 0 1 0 1 -> 0 However, I'm lost at this visualization, because on the NN structure picture, there are only 3 input neurons, and 2 perceptrons on the hidden layer, and 1 perceptron on the output layer. Question #1: So, based on the picture, I would assume that each X data points should only have 3 values not 4, why does it have 4 values? Question #2: Also, because based on the picture, we only have 2 perceptrons in the hidden layer, why on the table of "bh" there are 3 values? Based on the picture, shouldn't it be like this: linear transformation: (x1,1 * w1,1) + (x1,2 * w1,2) + (x1,3 *w1,3) + 1*bh1 (x2,1 * w2,1) + (x2,2 * w2,2) + (x2,3 *w2,3) + 1*bh2 So, shouldn't there be three X values, and two bh values?
This is superbly explained and made Neural Networks so easy. Would like to know more around different activation functions and what are the parameters which drive the decision to use one over another
Excellent, this helps me to understand a lot. Would you please explain why: hiddenLayer_linearTransform_wrt_weights_input_hidden = X instead of: hiddenLayer_linearTransform_wrt_weights_input_hidden = weights_input_hidden Thank you very much.
How could such a complex topic be unraveled in a simplistic way. This is really very clear. Thanks so much.