Introduction
The performance of a machine learning model not only depends on the model and the hyperparameters but also on how we process and feed different types of variables to the model. Since most machine learning models only accept numerical variables, preprocessing the categorical variables becomes a necessary step. We need to convert these categorical variables to numbers such that the model is able to understand and extract valuable information.

A typical data scientist spends 70 – 80% of his time cleaning and preparing the data. And converting categorical data is an unavoidable activity. It not only elevates the model quality but also helps in better feature engineering. Now the question is, how do we proceed? Which categorical data encoding method should we use?
In this article, I will be explaining various types of categorical data categorical encoding methods with implementation in Python.
Learning Objectives:
- Understand what categorical data is and the need for encoding it for machine learning models.
- Learn about different techniques for encoding categorical data like one-hot, label, target, and hashing encoding.
- Grasp the strengths and limitations of various encoding methods.
- Know how to implement different encoding techniques using Python.
In case you want to learn concepts of data science in video format, check out our course- Introduction to Data Science
Table of contents
What is Categorical Data?
Categorical data, also known as nominal or ordinal data, is a type of data that consists of values that fall into distinct categories or groups. Unlike numerical data, which represents measurable quantities, categorical data represents qualitative or descriptive characteristics. It is crucial to understand categorical data when working with machine learning models, as most models require numerical inputs.
Examples of Categorical Data
Categorical variables can be represented as strings or labels and have a finite number of possible values. Here are a few common examples:
- The city where a person lives (e.g., Delhi, Mumbai, Ahmedabad, Bangalore)
- The department a person works in (e.g., Finance, Human Resources, IT, Production)
- The highest degree a person has (e.g., High School, Diploma, Bachelor’s, Master’s, PhD)
- The grades of a student (e.g., A+, A, B+, B, B-)
Types of Categorical Data
There are two main types of categorical data:
1. Ordinal Data
Ordinal data refers to categories that have an inherent order or ranking. When encoding ordinal data, it’s essential to retain the information about the order in which the categories are provided. For example, when considering the highest degree a person possesses, the degree level provides vital information about their qualification, which can be an important feature in determining their suitability for a job.
2. Nominal Data
Nominal data refers to categories that do not have an inherent order or ranking. When encoding nominal data, the presence or absence of a feature is considered, but the order is not relevant. For instance, when considering the city where a person lives, it’s important to retain the information about which city they live in, but there is no particular order or sequence among the cities (e.g., living in Delhi or Bangalore is equal).
By understanding the nature of categorical data and the distinction between ordinal and nominal data, data scientists and machine learning practitioners can make informed decisions about the appropriate encoding techniques to use, ensuring that the valuable information contained within categorical variables is effectively captured and utilized by their models.
For encoding categorical data, we have a python package category encoders. The following code helps you install easily.
pip install category_encodersTypes of Encoding in Machine Learning
Identify Categorical Features:
- First, look at your data and find the features that contain non-numerical values like text labels or categories (e.g., color, size, customer type). These are the features that need encoding.
2. Choose an Encoding Technique:
- There are different encoding methods, each with its pros and cons. Here’s a quick guide to some popular choices:
- One-Hot Encoding: Great for many categories, creates new binary features (1 for the category, 0 for others).
- Label Encoding: Simple, assigns a number to each category, but assumes order matters (which might not be true).
- Ordinal Encoding: Similar to label encoding, but only use it if categories have a natural order (like low, medium, high).
3. Apply the Encoding:
- Once you’ve chosen your technique, it’s time to apply it to your data. Many machine learning libraries have built-in functions for encoding.
- For example, with one-hot encoding, you might create a new binary feature for each category in your original feature.
4. Test and Refine (Optional):
- In some cases, you might want to try different encoding techniques and see how they affect your machine learning model’s performance. This can help you find the best approach for your specific data.
Label Encoding or Ordinal Encoding
We use this categorical data encoding technique when the categorical feature is ordinal. In this case, retaining the order is important. Hence encoding should reflect the sequence.
In Label encoding, each label is converted into an integer value. We will create a variable that contains the categories representing the education qualification of a person.
Python Code:
Fit and transform train data
df_train_transformed = encoder.fit_transform(train_df)
One Hot Encoding
We use this categorical data encoding technique when the features are nominal(do not have any order). In one hot categorical encoding, for each level of a categorical feature, we create a new variable. Each category is mapped with a binary variable containing either 0 or 1. Here, 0 represents the absence, and 1 represents the presence of that category.
These newly created binary features are known as Dummy variables. The number of dummy variables depends on the levels present in the categorical variable. This might sound complicated. Let us take an example to understand this better. Suppose we have a dataset with a category animal, having different animals like Dog, Cat, Sheep, Cow, Lion. Now we have to one-hot encode this data.
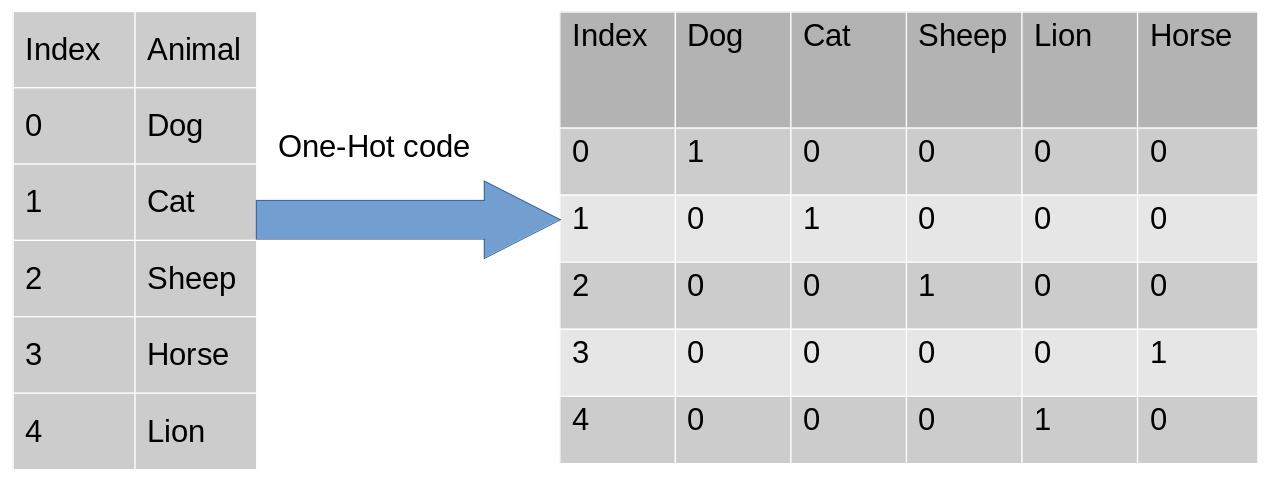
After encoding, in the second table, we have dummy variables each representing a category in the feature Animal. Now for each category that is present, we have 1 in the column of that category and 0 for the others. Let’s see how to implement a one-hot encoding in python.
import category_encoders as ce
import pandas as pd
data=pd.DataFrame({'City':[
'Delhi','Mumbai','Hydrabad','Chennai','Bangalore','Delhi','Hydrabad','Bangalore','Delhi'
]})
#Create object for one-hot encoding
encoder=ce.OneHotEncoder(cols='City',handle_unknown='return_nan',return_df=True,use_cat_names=True)
#Original Data
data

#Fit and transform Data
data_encoded = encoder.fit_transform(data)
data_encoded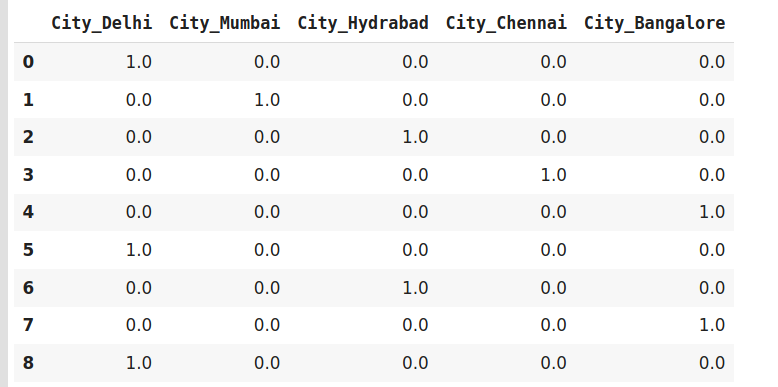
Now let’s move to another very interesting and widely used encoding technique i.e Dummy encoding.
Dummy Encoding
Dummy coding scheme is similar to one-hot encoding. This categorical data encoding method transforms the categorical variable into a set of binary variables (also known as dummy variables). In the case of one-hot encoding, for N categories in a variable, it uses N binary variables. The dummy encoding is a small improvement over one-hot-encoding. Dummy encoding uses N-1 features to represent N labels/categories.
To understand this better let’s see the image below. Here we are coding the same data using both one-hot encoding and dummy encoding techniques. While one-hot uses 3 variables to represent the data whereas dummy encoding uses 2 variables to code 3 categories.
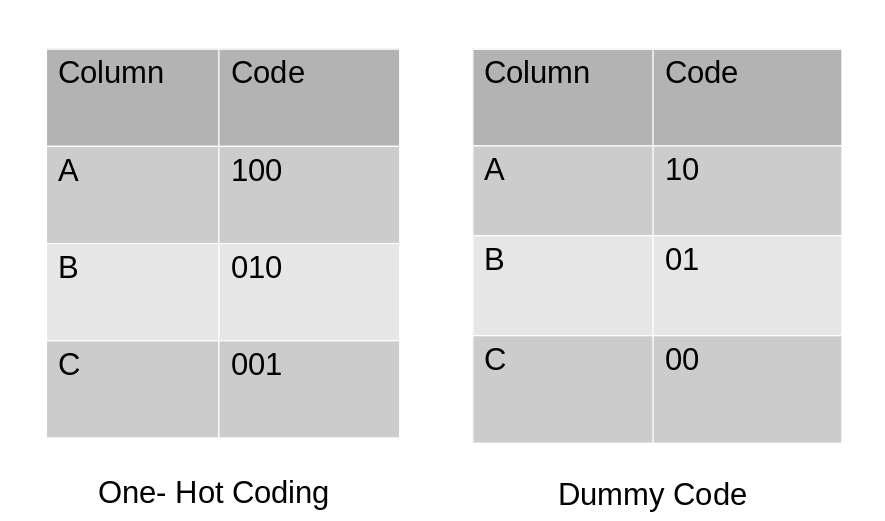
Let us implement it in python.
import category_encoders as ce
import pandas as pd
data=pd.DataFrame({'City':['Delhi','Mumbai','Hyderabad','Chennai','Bangalore','Delhi,'Hyderabad']})
#Original Data
data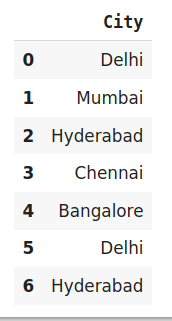
#encode the data
data_encoded=pd.get_dummies(data=data,drop_first=True)
data_encoded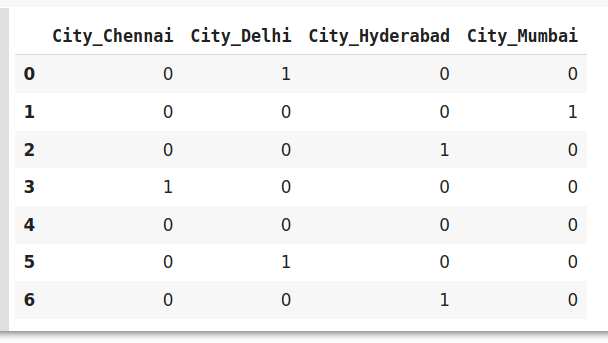
Here using drop_first argument, we are representing the first label Bangalore using 0.
Drawbacks of One-Hot and Dummy Encoding
One hot encoder and dummy encoder are two powerful and effective categorical encoding schemes. They are also very popular among the data scientists, But may not be as effective when-
- A large number of levels are present in data. If there are multiple categories in a feature variable in such a case we need a similar number of dummy variables to encode the data. For example, a column with 30 different values will require 30 new variables for coding.
- If we have multiple categorical features in the dataset similar situation will occur and again we will end to have several binary features each representing the categorical feature and their multiple categories e.g a dataset having 10 or more categorical columns.
In both the above cases, these two encoding schemes introduce sparsity in the dataset i.e several columns having 0s and a few of them having 1s. In other words, it creates multiple dummy features in the dataset without adding much information.
Also, they might lead to a Dummy variable trap. It is a phenomenon where features are highly correlated. That means using the other variables, we can easily predict the value of a variable.
Due to the massive increase in the dataset, coding slows down the learning of the model along with deteriorating the overall performance that ultimately makes the model computationally expensive. Further, while using tree-based models these encodings are not an optimum choice.
Effect Encoding
This encoding technique is also known as Deviation Encoding or Sum Encoding. Effect encoding is almost similar to dummy encoding, with a little difference. In dummy coding, we use 0 and 1 to represent the data but in effect encoding, we use three values i.e. 1,0, and -1.
The row containing only 0s in dummy encoding is encoded as -1 in effect encoding. In the dummy encoding example, the city Bangalore at index 4 was encoded as 0000. Whereas in effect encoding it is represented by -1-1-1-1.
Let us see how we implement it in python-
import category_encoders as ce
import pandas as pd
data=pd.DataFrame({'City':['Delhi','Mumbai','Hyderabad','Chennai','Bangalore','Delhi,'Hyderabad']}) encoder=ce.sum_coding.SumEncoder(cols='City',verbose=False,)
#Original Data
dataencoder.fit_transform(data)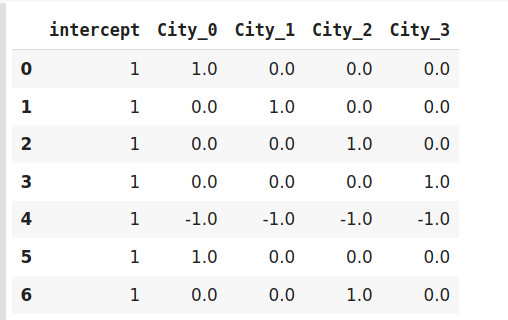
Effect encoding is an advanced technique. In case you are interested to know more about effect encoding categorical data, refer to this interesting paper.
Hash Encoder
To understand Hash encoding it is necessary to know about hashing. Hashing is the transformation of arbitrary size input in the form of a fixed-size value. We use hashing algorithms to perform hashing operations i.e to generate the hash value of an input. Further, hashing is a one-way process, in other words, one can not generate original input from the hash representation.
Hashing has several applications like data retrieval, checking data corruption, and in data encryption also. We have multiple hash functions available for example Message Digest (MD, MD2, MD5), Secure Hash Function (SHA0, SHA1, SHA2), and many more.
Just like one-hot encoding, the Hash encoder represents categorical features using the new dimensions. Here, the user can fix the number of dimensions after transformation using n_component argument. Here is what I mean – A feature with 5 categories can be represented using N new features similarly, a feature with 100 categories can also be transformed using N new features. Doesn’t this sound amazing?
By default, the Hashing encoder uses the md5 hashing algorithm but a user can pass any algorithm of his choice. If you want to explore the md5 algorithm, I suggest this paper.
import category_encoders as ce
import pandas as pd
#Create the dataframe
data=pd.DataFrame({'Month':['January','April','March','April','Februay','June','July','June','September']})
#Create object for hash encoder
encoder=ce.HashingEncoder(cols='Month',n_components=6)
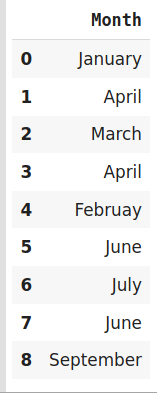
#Fit and Transform Data
encoder.fit_transform(data)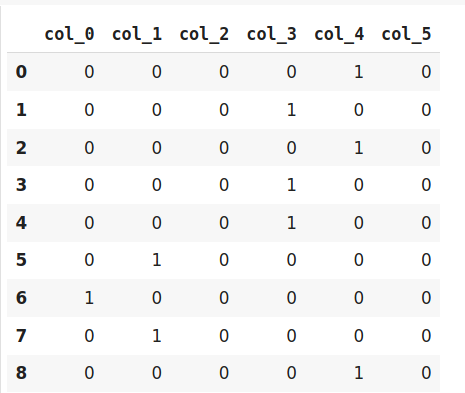
Since Hashing transforms the data in lesser dimensions, it may lead to loss of information. Another issue faced by hashing encoder is the collision. Since here, a large number of features are depicted into lesser dimensions, hence multiple values can be represented by the same hash value, this is known as a collision.
Moreover, hashing encoders have been very successful in some Kaggle competitions. It is great to try if the dataset has high cardinality features.
Binary Encoding
Binary encoding is a combination of Hash encoding and one-hot encoding. In this encoding scheme, the categorical feature is first converted into numerical using an ordinal encoder. Then the numbers are transformed in the binary number. After that binary value is split into different columns.
Binary encoding machine learning works really well when there are a high number of categories. For example the cities in a country where a company supplies its products.
#Import the libraries
import category_encoders as ce
import pandas as pd
#Create the Dataframe
data=pd.DataFrame({'City':['Delhi','Mumbai','Hyderabad','Chennai','Bangalore','Delhi','Hyderabad','Mumbai','Agra']})
#Create object for binary categorical encoding
encoder= ce.BinaryEncoder(cols=['city'],return_df=True)
#Original Data
data
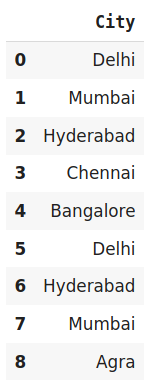
#Fit and Transform Data
data_encoded=encoder.fit_transform(data)
data_encoded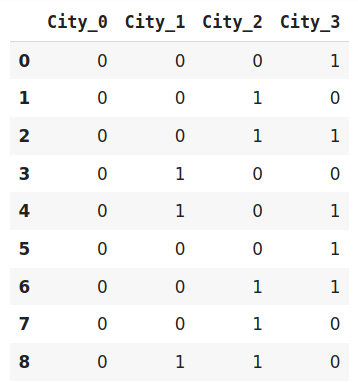
Binary encoding is a memory-efficient encoding scheme as it uses fewer features than one-hot encoding categorical data. Further, It reduces the curse of dimensionality for data with high cardinality.
Base N Encoding
Before diving into BaseN encoding let’s first try to understand what is Base here?
In the numeral system, the Base or the radix is the number of digits or a combination of digits and letters used to represent the numbers. The most common base we use in our life is 10 or decimal system as here we use 10 unique digits i.e 0 to 9 to represent all the numbers. Another widely used system is binary i.e. the base is 2. It uses 0 and 1 i.e 2 digits to express all the numbers.
For Binary encoding, the Base is 2 which means it converts the numerical values of a category into its respective Binary form. If you want to change the Base of encoding scheme you may use Base N encoder. In the case when categories are more and binary encoding is not able to handle the dimensionality then we can use a larger base such as 4 or 8.
#Import the libraries
import category_encoders as ce
import pandas as pd
#Create the dataframe
data=pd.DataFrame({'City':['Delhi','Mumbai','Hyderabad','Chennai','Bangalore','Delhi','Hyderabad','Mumbai','Agra']})
#Create an object for Base N Encoding
encoder= ce.BaseNEncoder(cols=['city'],return_df=True,base=5)
#Original Data
data#Fit and Transform Data
data_encoded=encoder.fit_transform(data)
data_encoded
In the above example, I have used base 5 also known as the Quinary system. It is similar to the example of Binary encoding. While Binary encoding categorical data represents the same data by 4 new features the BaseN encoding uses only 3 new variables.
Hence BaseN encoding technique further reduces the number of features required to efficiently represent the data and improving memory usage. The default Base for Base N is 2 which is equivalent to Binary Encoding machine learning.
Target Encoding
Target encoding is a technique used in machine learning and data preprocessing to transform categorical variables into numerical values. Unlike one-hot encoding, which creates binary columns for each category, target encoding calculates and assigns a numerical value to each category based on the relationship between the category and the target variable. Typically used for classification tasks, it replaces the categorical values with their corresponding mean (or other statistical measures) of the target variable within each category.
Target encoding can be effective in capturing valuable information from categorical data while reducing the dimensionality of the feature space, making it suitable for models like decision trees and gradient boosting.
Target encoding is a Baysian encoding technique.
Bayesian encoders use information from dependent/target variables to encode the categorical data.
In target encoding, we calculate the mean of the target variable for each category and replace the category variable with the mean value. In the case of the categorical target variables, the posterior probability of the target replaces each category.
#import the libraries
import pandas as pd
import category_encoders as ce
#Create the Dataframe
data=pd.DataFrame({'class':['A,','B','C','B','C','A','A','A'],'Marks':[50,30,70,80,45,97,80,68]})
#Create target encoding object
encoder=ce.TargetEncoder(cols='class')
#Original Data
Data
#Fit and Transform Train Data
encoder.fit_transform(data['class'],data['Marks'])
We perform Target encoding for train data only and code the test data using results obtained from the training dataset. Although, a very efficient coding system, it has the following issues responsible for deteriorating the model performance-
- It can lead to target leakage or overfitting. To address overfitting we can use different techniques.
- In the leave one out encoding categorical data, the current target value is reduced from the overall mean of the target to avoid leakage.
- In another method, we may introduce some Gaussian noise in the target statistics. The value of this noise is hyperparameter to the model.
- The second issue, we may face is the improper distribution of categories in train and test data. In such a case, the categories may assume extreme values. Therefore the target means for the category are mixed with the marginal mean of the target.
Conclusion
To summarize, encoding categorical data is an unavoidable part of the feature engineering. It is more important to know what coding scheme should we use. Having into consideration the dataset we are working with and the model we are going to use. In this article, we have seen various encoding techniques along with their issues and suitable use cases. Also, we have seen types of encoding in machine learning.
Key Takeaways:
- Encoding categorical variables is an essential data preprocessing step for machine learning as most algorithms require numerical input.
- Techniques like one-hot and label encoding are popular for nominal and ordinal categorical data respectively.
- Advanced methods like target and hashing encoding can handle high cardinality categorical features efficiently.
- The choice of encoding depends on the number of categories, presence of order, and the model being used.
If you want to know more about dealing with categorical variables, please refer to this article-
In case you have any comments please free to reach out to me in the comments below.
Frequently Asked Questions
Q1. What is meant by binary encoding?
A. Binary encoding converts categorical data into binary digits (0s and 1s) based on unique integer mappings, efficiently representing categories in a format suitable for machine learning algorithms.
Q2. What is binary file encoding?
A. Binary file encoding translates data into a binary format, allowing efficient storage and retrieval of files, including text, images, and executables, while preserving the original content and structure.
Q3. Why do I need binary encoding?
A. You need Binary encoding machine learning to represent categorical variables in a way that machine learning models can process, reducing dimensionality and computational complexity compared to other encoding methods.
Q4. What is the difference between binary and one-hot encoding?
A. Binary encoding assigns binary values to categories using fewer bits, while one-hot encoding creates binary vectors with a single high (1) value and all others low (0), increasing dimensionality.








Thanks a lot for this Shipra. Its amazing, how most of my time never moved beyond dummy encoding or one hot encoding. Infact some of these i have never heard before. Thanks alot again
Article was well explained. Thank you.. Question: In Target Encoding for A, the mean = (50+97+80+68)/4 = 73.75. How come A gets 65 OR 79.67 ? The encoded values of B and C are also deviating. Can you explain ?
Artical was well explained. Thank you. Question: What I should to do if my dataset have 6 categorical variable from which 2 categorical variable contains large number of levels. Please answer this question.