This article was published as a part of the Data Science Blogathon.
Overview
- Every basic fundamental and building block which is required for Sentiment Analysis.
- I’ve used an easy approach to explain all the basic concepts so that even a beginner reader would be able to get a thorough understanding of all the concepts.
- Topics: Preprocessing text, Vocabulary Corpus, Feature Extraction (Sparse Representation and Frequency Dictionary), Logistic Regression model for sentiment analysis.
Introduction
Sentiment Analysis is a supervised Machine Learning technique that is used to analyze and predict the polarity of sentiments within a text (either positive or negative).
It is often used by businesses and companies to understand their user’s experience, emotions, responses, etc. so that they can improve the quality and flexibility of their products and services.
Now, let’s dive deep into understanding how this sentiment analysis technique is used by machine learning engineers to examine sentiments of various texts.
Gathering Data
Data is the heart of every machine learning problem. In terms of Machine Learning, no problem can be solved without data, even there’s an old saying:
” THE MORE DATA, THE BETTER ! “
There are so many open sources of data that can be used for training ML models so it’s a personal choice to gather data by yourself or use open datasets to train our algorithm.
Text-based datasets are generally distributed as JSON or CSV formats, so to use them, we can either fetch the data into a python list or a dictionary/data frame object.
Data should be split into the train, validation, and test sets in a common fashion of 60% 20% 20% or 70% 15% 15%.
The popular Twitter dataset can be downloaded from here.
Pipeline
Every Machine Learning task should have a Pipeline. Pipelines are used for splitting up your machine learning workflows into independent, reusable, modular parts that can then be pipelined together to continuously improve the accuracy of the model and achieve a successful algorithm.
We’ll follow a basic pipeline structure for our problem so that a reader can easily understand each part of the pipeline used in our workflow. Our pipeline will include the following steps:
- Preprocessing Text and Building Vocabulary: Removing unwanted texts (stop words), punctuations, URLs, handles, etc. which do not have any sentimental value. And then adding unique preprocessed words to a vocabulary.
- Feature Extraction: Iterating through each data example to extract features using a frequency dictionary and finally create a feature matrix.
- Training Model: We’ll then use our feature matrix to train a Logistic Regression model in order to use that model for predicting sentiments.
- Testing Model: Using our trained model to get the predictions from data it never saw.
Preprocessing Data
It is an important step in our pipeline. Preprocessing text can be used to remove the words and punctuations from the text data that do not have any sentimental value, as preprocessing text can significantly improve our training time as our data size will be reduced and limited to the words having some sentimental value. Preprocessing includes handling of-
-
Stop Words
Words that do not have any semantic or sentimental value/weight in a sentence. e.g.: and, is, the, you, etc.
How to process them? We’ll create a list including all possible stop words like
[‘ourselves’, ‘hers’, ‘between’, ‘yourself’, ‘but’, ‘again’, ‘there’, ‘about’, ‘once’, ‘during’, ‘out’, ‘very’, ‘having’, ‘with’, ‘they’, ‘own’, ‘an’, ‘be’, ‘some’, ‘for’, ‘do’, ‘its’, ‘yours’, ‘such’, ‘into’, ‘of’, ‘most’, ‘itself’, ‘other’, ‘off’, ‘is’, ‘s’, ‘am’, ‘or’, ‘who’, ‘as’, ‘from’, ‘him’, ‘each’, ‘the’, ‘themselves’, ‘until’, ‘below’, ‘are’, ‘we’, ‘these’, ‘your’, ‘his’, ‘through’, ‘don’, ‘nor’, ‘me’, ‘were’, ‘her’, ‘more’, ‘himself’, ‘this’, ‘down’, ‘should’, ‘our’, ‘their’, ‘while’, ‘above’, ‘both’, ‘up’, ‘to’, ‘ours’, ‘had’, ‘she’, ‘all’, ‘no’, ‘when’, ‘at’, ‘any’, ‘before’, ‘them’, ‘same’, ‘and’, ‘been’, ‘have’, ‘in’, ‘will’, ‘on’, ‘does’, ‘yourselves’, ‘then’, ‘that’, ‘because’, ‘what’, ‘over’, ‘why’, ‘so’, ‘can’, ‘did’, ‘not’, ‘now’, ‘under’, ‘he’, ‘you’, ‘herself’, ‘has’, ‘just’, ‘where’, ‘too’, ‘only’, ‘myself’, ‘which’, ‘those’, ‘i’, ‘after’, ‘few’, ‘whom’, ‘t’, ‘being’, ‘if’, ‘theirs’, ‘my’, ‘against’, ‘a’, ‘by’, ‘doing’, ‘it’, ‘how’, ‘further’, ‘was’, ‘here’, ‘than’]
Now we’ll iterate through each example in our data and remove every word from our data that is present in the stop word list.
-
Punctuations
Punctuations are symbols that we use to emphasize our text. for e.g. : ! , @ , # , $ , etc.
How to process them? We’ll process them similarly as we have processed the Stop Words, we will create a list of them and process each example with that list.
-
URLs and Handles
URLs are the links that start with Http protocol declaration eg. ‘https://….’ and handles are used to mention people in social media eg. ‘@user’ both of them share null sentimental significance.
How to process them? Process them by creating some function ‘process_handles_urls()’ which will take our train data and eliminate words starting with ‘https://’ or ‘@’ from each example.
-
Stemming
Stemming is a process of reducing a word to its base stem word. e.g. ‘turn’ is a stem word of turning, turns, turned, etc. Since stem word delivers the same sentimental value for all its suffixed words thus, we can reduce each word to its base stem that can reduce our vocabulary size and training time as well.
How to process them? Process them by creating some function ‘do_stemming()’ which will take the data and stem the words of each example.
-
Lower Casing
We should use similar letter cases for each word in data so that to represent ‘Word’, ‘WORD’, ‘word’ there should only be a single case to follow i.e. lower case, this can also help to reduce vocabulary size and eliminate repetition of words.
How to process them? iterate through each example use .lower() method to make convert every piece of text into lower case.
Vocabulary Corpus
After preprocessing the data it’s time to create a vocabulary that will store each unique word and assign some numeric value to each distinct word (this is also called Tokenization).
We’ll use this vocabulary dictionary for feature extraction.
.png)
Feature Extraction
One of the problems, while working with language processing is that machine learning algorithms cannot work on the raw text directly. So, we need some feature extraction techniques to convert text into a matrix(or vector) of numerical features.
Let’s take some positive and negative tweet examples:

NOTE: The above example is not processed so we'll process it first before moving on to further steps.
Sparse Representation
It’s a naive approach to extract features of a text. According to sparse representation, we can create a feature matrix by iterating through whole data, and for each word, in the text example we’ll assign 1 at the position of that word in the vocabulary list and for non-occurring words, we’ll assign 0. So, our feature matrix will have rows=total sentences in our data and columns=total words in the vocabulary.
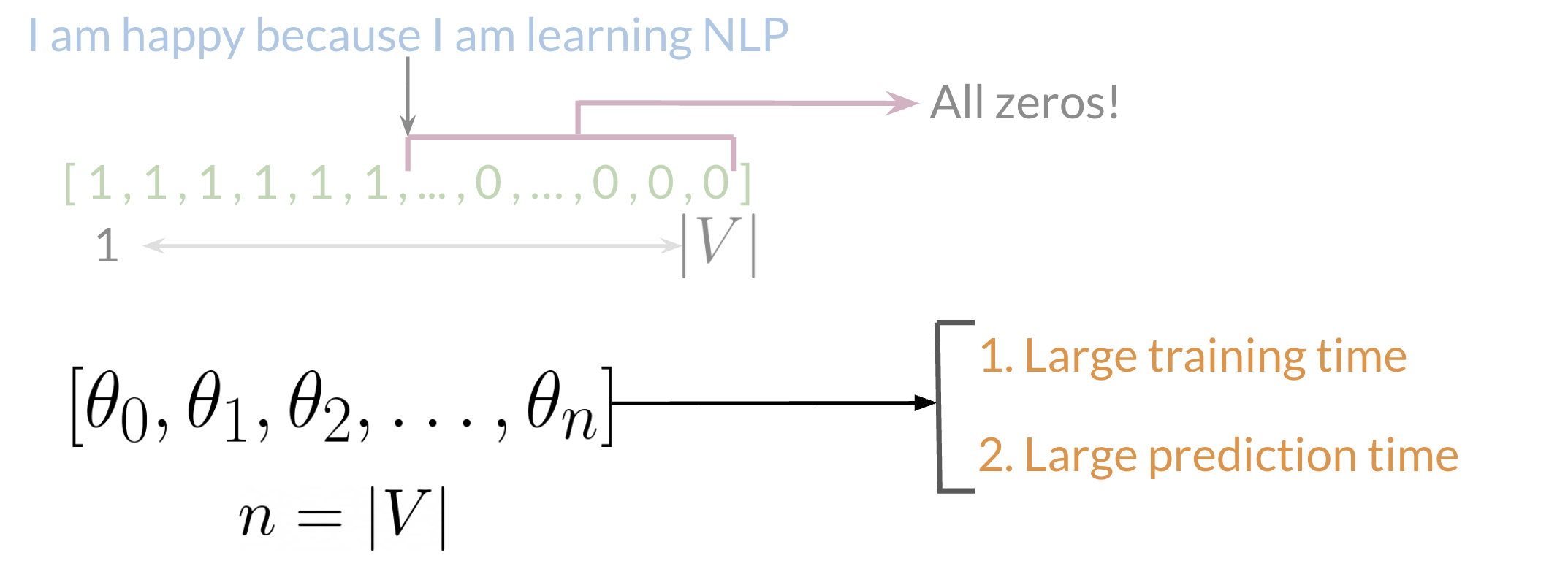
Disadvantages:
- Large Training time
- Large Prediction time
Frequency Dictionary
A frequency dictionary keeps track of the Positive and Negative frequencies of each word in our data.
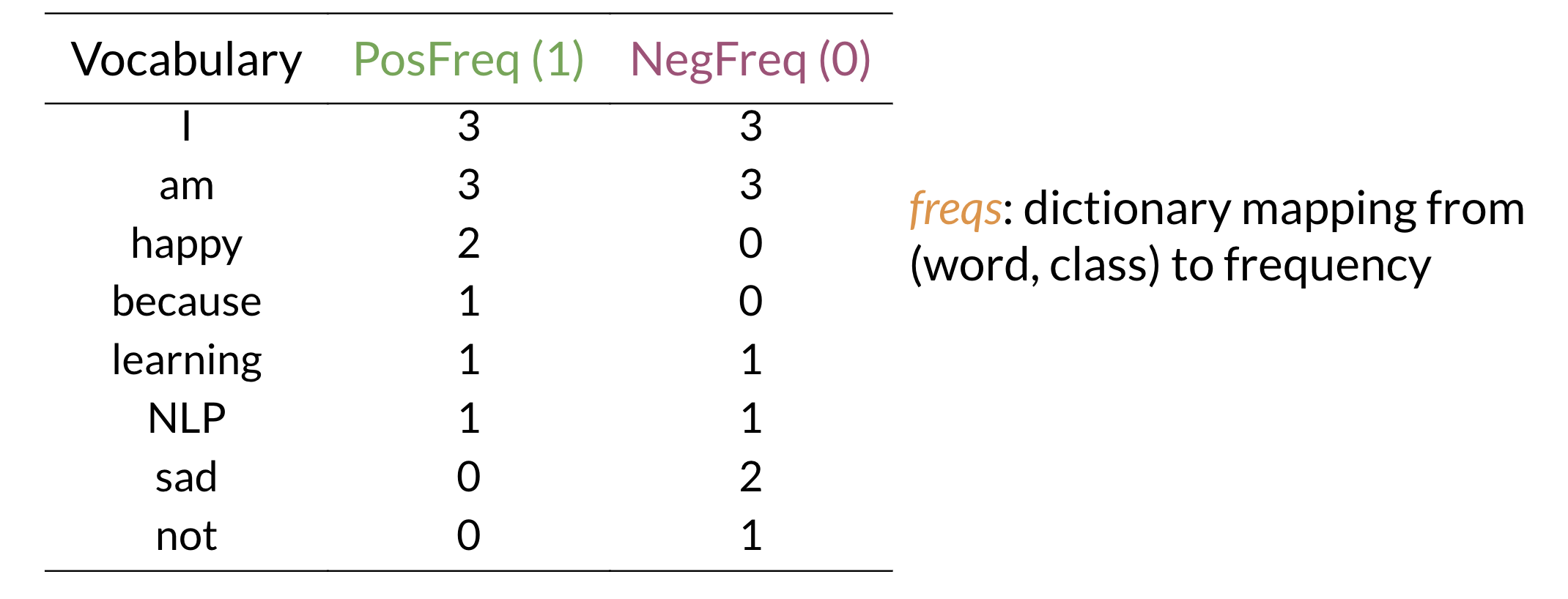
Positive Frequency: The Number of times a word occurred in sentences with positive sentiment.
Negative Frequency: The Number of times a word occurred in sentences with negative sentiment.
Feature extraction with Frequency Dictionary :
Using Frequency Dictionary for feature extraction, we can reduce the dimensions of each row representing each sentence of a feature matrix (i.e. equal to the number of words in vocabulary in case of sparse representation) to three dimensions.
Features of a text data are extracted with feature dictionary using the following formulae:
.png)
The process almost looks like:


Now we have a 3-dimensional feature vector for our tweet that looks like :
Xm= [1,8,11]
Now we’ll iterate through every example to extract features of each example then we’ll use those features to create the feature matrix that we can use for training. In the end, we have some feature matrix like –
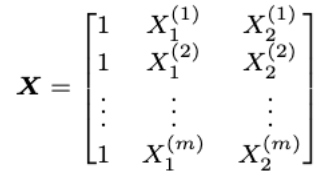
Logistic Regression for Sentiment Analysis
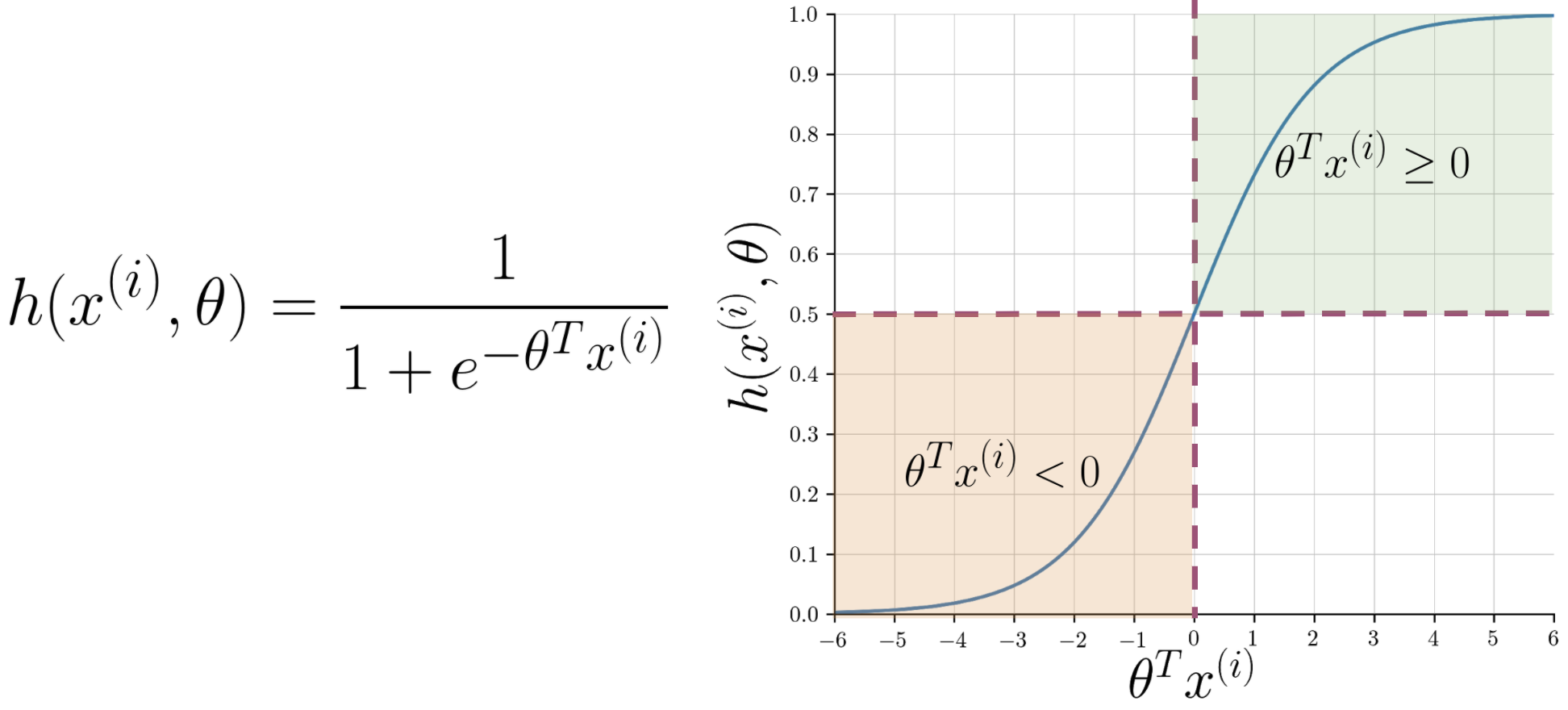
Logistic regression models the probabilities for classification problems with two possible outcomes. It’s an extension of the linear regression model for classification problems.
Logistic Regression uses a sigmoid function to map the output of our linear function (θTx) between 0 to 1 with some threshold (usually 0.5) to differentiate between two classes, such that if h>0.5 it’s a positive class, and if h<0.5 its a negative class. (explaining whole logistic regression is beyond the scope of this article)
Training Sentiment Analysis model
Training of our model will follow the following steps:
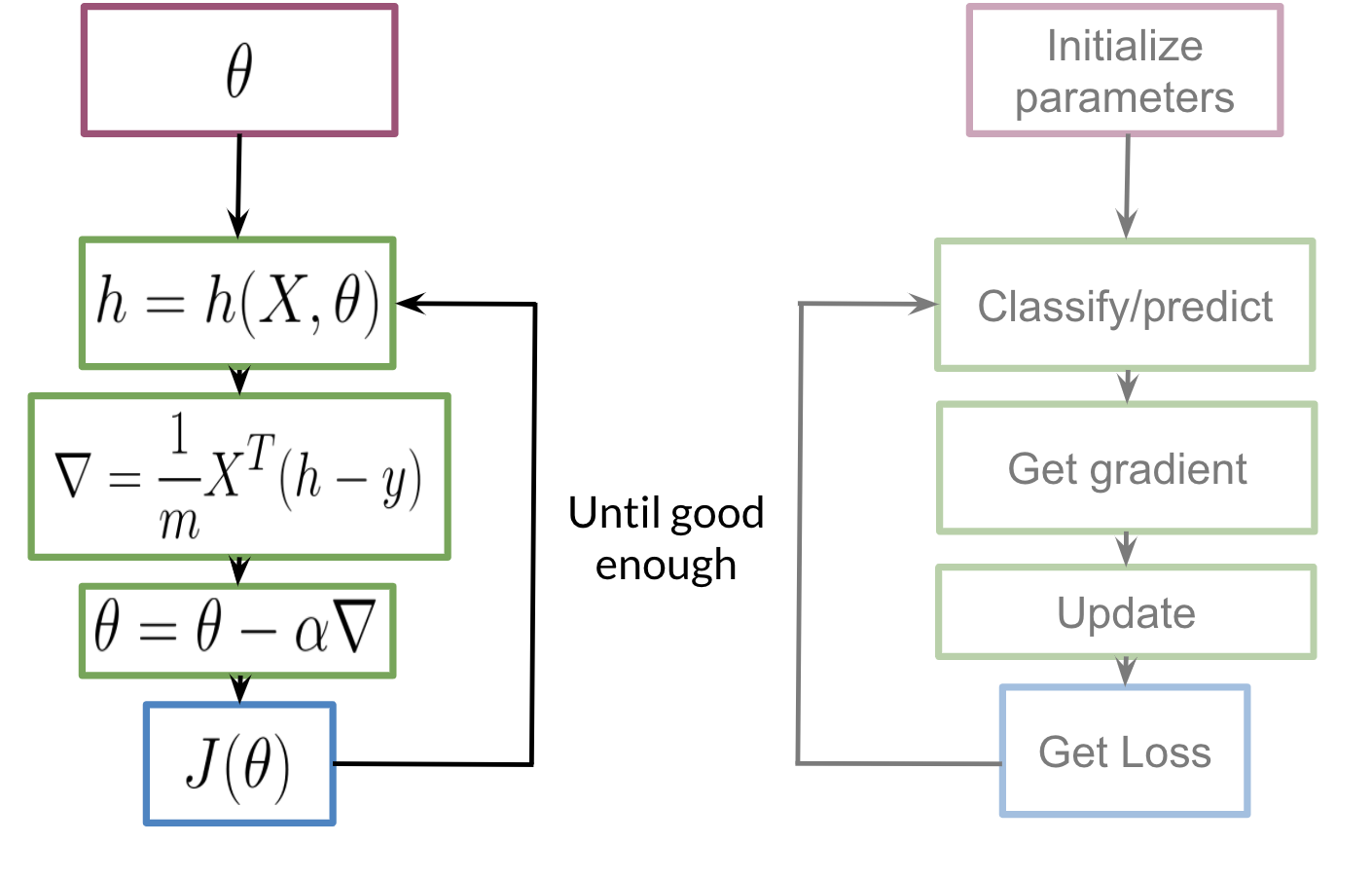
We initialize our parameter θ, that we can use in our sigmoid, we then compute the gradient that we will use to update θ and then calculate the cost. We’ll keep repeating the steps until the cost minimizes/converges.
Testing our Model
To test our model we’ll use our Validation set and follow the following steps:
- Split the data into X_validation (text) and Y_validation (sentiment).
- Use feature extraction for X_validation to transform texts into numerical features.
- Find the vector h (= sigmoid(θTx)) for each text in the validation set.
- Map some function to get the actual classes while comparing with a threshold.
- Find the accuracy of our predictions.

Summary
Glad you made it till here! if you’re a beginner to Natural Language Processing, I hope I was able to give you a glimpse of how things work underneath the hood and make you able to cover more complex and advanced topics further and if you’re a practitioner I hope I was able to brush up your basics.
Natural Language Processing is a vast domain of AI its applications are used in various paradigms such as Chatbots, Sentiment Analysis, Machine Translation, Autocorrect, etc. and I’ve just covered a grain of the topic so in case you want to learn more there are various e-learning platforms and freely distributed articles, papers, etc. which can be useful for you to go further in the journey.
References: Natural Language Processing Specialization




