Machine Learning in Microservices
This article was published as a part of the Data Science Blogathon.
HIGHLIGHTS
- The increasing speed of data means the use of machine learning with edge devices and microservices will increase.
- Organizations will increasingly deploy machine learning with microservices, as it allows them to target a specific functionality.
Introduction
It is now unreasonable to wait for data to land in a final data store, such as HDFS or S3. Before it becomes available for retraining machine learning and deep learning models, it needs to be used for classification or model execution.
The data must be available immediately, streaming at incredible velocities from devices, gateways, logs, web applications, mobile applications, blockchain nodes, smart meters, and containers in every cloud. This ever-changing, fast data requires more agile means of tapping into it.
It demands more than just simple SQL analytics.
As fast data becomes relevant for so many use-cases — from IoT, cybersecurity, and log analytics to SQL change data capture and more — we will find the need to push machine learning execution out to every edge.
Every day, a Fortune 500 customer approaches me with questions in a meeting. No longer do they just ask how to obtain their data at scale, but how they can ingest at scale with simultaneous storage to multiple cloud endpoints and Hadoop — while providing data for retraining their machine learning models and also running those models against incoming data. Everyone needs sub-second responses and real-time streaming analytics.
For some of this, SQL will be adequate, such as Apache Calcite queries inside Apache NiFi on Dataflows. Oftentimes, however, we require additional analytics, such as YOLO analysis on images or sentiment analysis on unstructured chunks of ingested text from calls and chats. Fortunately, there are options that can be handled in a properly built environment to allow developers to build microservices that add machine learning to this process.
Unfortunately, like most things in enterprise IT, definitions can be nebulous or defined by many competing organizations, corporations, or media entities. I do not wish to join one of these factions. Having come from a microservices-enabling entity, Pivotal, I will just try to find a baseline that makes sense.
You can add or subtract pieces from my definition as need be. We can also go further and make our services serverless. These are even lighter weight and may be more appropriate, depending on the use case.
If you are evaluating such a paradigm, please check out the Open Source Apache NiFi Stateless container to see if fits your needs. I recommend that you also look at Apache OpenWhisk or the FNProject. There are many options of where to run these services, from native cloud to YARN to projects on Kubernetes.
Universal scheduler, YUNIKORN.
For now, let’s stick to basic microservices, which I will define as maintainable, testable, loosely coupled services that can be independently deployed with one real use case/function. (See: https://martinfowler.com/articles/microservices.html ) This definition makes it a little simpler and keeps us from haggling over whether or not something is a microservice if it does not have all the factors of a 12-factor app.
So, for the purpose of running machine learning at scale as part of real-time data streams and flows, I suggest some of the following options: Apache Kafka Streams, Spring Boot, Apache Flink, Apache NiFi Flows, and CSDW Models. To allow you to run all of these models in the same environment — which I have done — I recommend having Apache Kafka as the decoupling agent.
Having this securely managed, enterprise streaming platform as our distribution channel provides much of the infrastructure, security, scalability, decoupling, and monitoring that is needed in such a system. Using specialized tools, you can obtain full insight into what’s happening with these complex machine learning pipelines.
Let’s look at a few ways of using microservices for machine learning and deep learning.
Our first case is the easiest. I want to run YOLO SSD processing on an image as it comes off an IoT camera. In this use case, as the image is loaded by MiNiFi, it is sent to Apache NiFi.
Apache NiFi can run PMML, ONNX, TensorFlow Lite, or other models via custom processors, such as the ones I have written in Java for Apache MXNet and TensorFlow.
This method is very quick but requires that at least one part of your machine learning pipeline live directly inside of Apache NiFi.
We can also push the model all the way to the edge and have the MiNiFi agent run the model right at the edge device or gateway.
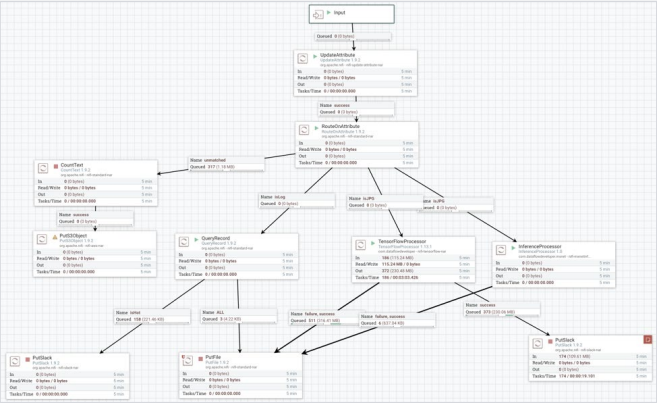
A second option is to have a very slim process, such as a minimal MiNiFi flow, which captures the source data — whether it’s an image from a camera, text from a log, or time series data from a sensor — and sends it directly to a Kafka topic for consuming and processing by a Kafka Stream or Flink microservice that can execute your machine learning model. You can run your model via Flink ML or have Flink call an existing PMML model. You can also execute an ONNX model from Flink or KafkaStreams.
There are many options for models, including TensorFlow Lite, ONNX, PMML, DeepLearning4Java, H2O, and Pickle. Most of these model runners can be distributed and used by most of the microservices options. Again, you need to decide which language and stream processing engine makes the most sense for your use cases.
Building machine learning in microservices
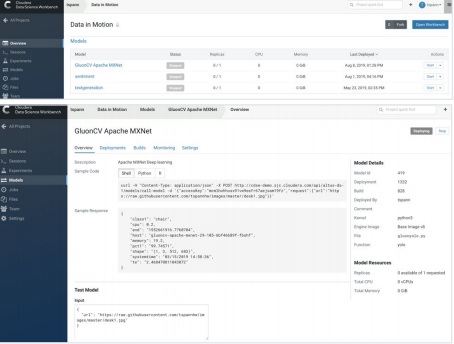
A third option is to build machine learning microservices in Python, R, or Scala. You can host your microservices in an enterprise environment with full security running on Kubernetes. As shown in the screenshots below, it is very easy to host your model and provide a REST API for integration. This option is great for easy integration of your machine learning and deep learning models with all your other microservices.
It also lets data scientists work in an agile collaborative environment, allowing them to easily deploy evolving models. If you need to use asynchronous Kafka to decouple this from other processes, we can use Apache NiFi to convert Kafka messages into calls to the REST microservice, and then package the results in a second Kafka message.
Apache NiFi will act as your universal router and gateway for microservices and messages at scale.
Another use case is the processing of streaming textual data, such as social media, as it arrives. We can use this text data to expand our machine learning corpus for our model. Using Apache Kafka as a universal messaging gateway, for this last use case, we will have Apache NiFi ingest a social media feed — say, real-time tweets — and push these tweets as AVRO options with schemas with a standard schema we have built.
Cloudera Schema Registry
We use the Cloudera Schema Registry as a universal service that anyone can interface with using a simple REST API. More decoupling of our microservices makes it easy to send these messages in AVRO to many subscribers via our Kafka distribution channel.
One such consumer of the Kafka messages could be a custom Java microservice written in Apache Flink to apply custom NLP machine learning to analyze any given tweet for content and sentiment.
The results of this would be sent to another topic in Kafka, for either processing by Apache NiFi in production (Big Data stores such as Kudu, HBase, Hive, or Impala) or possibly straight to an object store such as Amazon S3.
Stay Tuned!
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.










