This article was published as a part of the Data Science Blogathon.
Introduction
Hi folks, I hope you are doing well in these difficult times! We all are going through the unprecedented time of the Corona Virus pandemic. Some people lost their lives, but many of us successfully defeated this new strain i.e. Covid-19. The virus was declared a pandemic by World Health Organization on 11th March 2020. This article will analyze various types of “Tweets” gathered during pandemic times. The study can be helpful for different stakeholders.
For example, Government can make use of this information in policymaking as they can able to know how people are reacting to this new strain, what all challenges they are facing such as food scarcity, panic attacks, etc. Various profit organizations can make a profit by analyzing various sentiments as one of the tweets telling us about the scarcity of masks and toilet papers. These organizations can able to start the production of essential items thereby can make profits. Various NGOs can decide their strategy of how to rehabilitate people by using pertinent facts and information.
In this project, we are going to predict the Sentiments of COVID-19 tweets. The data gathered from the Tweeter and I’m going to use Python environment to implement this project.
Problem Statement
The given challenge is to build a classification model to predict the sentiment of Covid-19 tweets. The tweets have been pulled from Twitter and manual tagging has been done. We are given information like Location, Tweet At, Original Tweet, and Sentiment.
Approach To Analyze Various Sentiments
Before we proceed further, One should know what is mean by Sentiment Analysis. Sentiment Analysis is the process of computationally identifying and categorizing opinions expressed in a piece of text, especially in order to determine whether the writer’s attitude towards a particular topic is Positive, Negative, or Neutral. (Oxford Dictionary)
Following is the Standard Operating Procedure to tackle the Sentiment Analysis kind of project. We will be going through this procedure to predict what we supposed to predict!
-
Exploratory Data Analysis.
-
Data Preprocessing.
-
Vectorization.
-
Classification Models.
-
Evaluation.
-
Conclusion.
Let’s Guess some tweets
I will read the tweet and can you tell me the sentiment of that tweet whether it is Positive, Negative, Or Neutral. So the first tweet is “Still shocked by the number of #Toronto supermarket employees working without some sort of mask. We all know by now, employees can be asymptomatic while spreading #coronavirus”. What’s your guess? Yeah, you are correct. This is a Negative tweet because it contains negative words like “shocked”.
If you can’t able to guess the above tweet, don’t worry I have another tweet for you. Let’s guess this tweet-“Due to the Covid-19 situation, we have increased demand for all food products. The wait time may be longer for all online orders, particularly beef share and freezer packs. We thank you for your patience during this time”. This time you are absolutely correct in predicting this tweet as “Positive”. The words like “thank you”, “increased demand” are optimistic in nature hence these words categorized the tweet into positive.
Data Summary
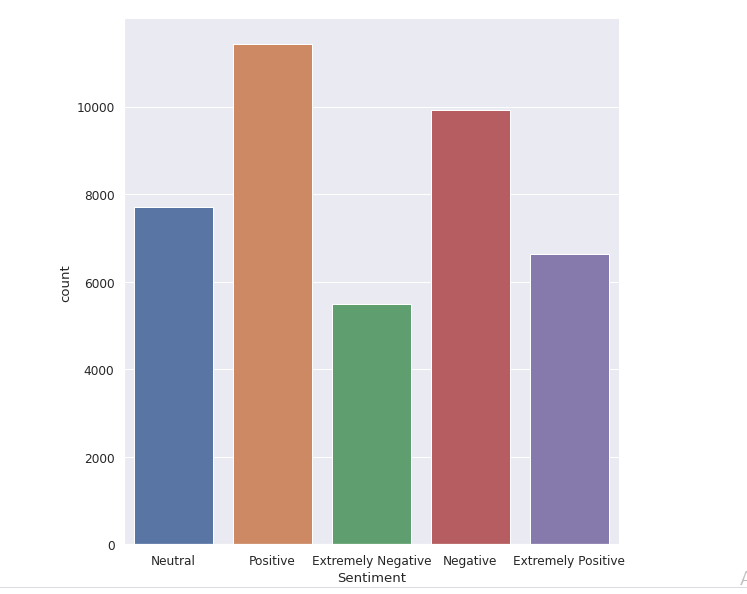
The original dataset has 6 columns and 41157 rows. In order to analyze various sentiments, We require just two columns named Original Tweet and Sentiment. There are five types of sentiments- Extremely Negative, Negative, Neutral, Positive, and Extremely Positive as you can see in the following picture.
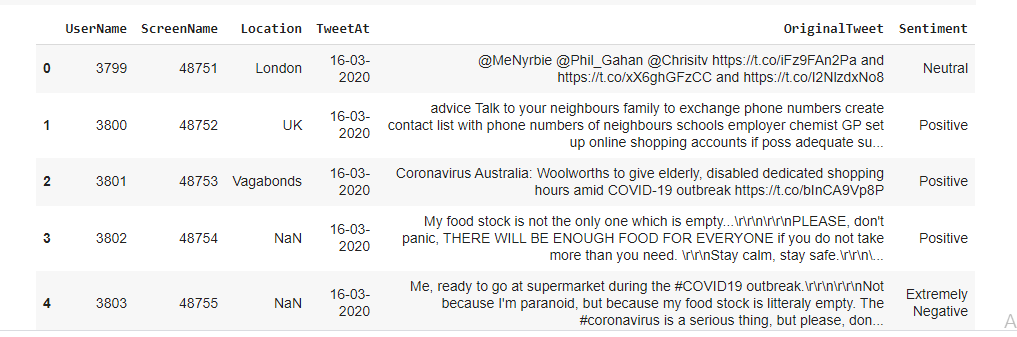
Summary Of Dataset
Basic Exploratory Data Analysis
The columns such as “UserName” and “ScreenName” do not give any meaningful insights for our analysis. Hence we are not using these features for model building. All the tweets data collected from the months of March and April 2020. The following Bar plot shows us the number of unique values in each column.
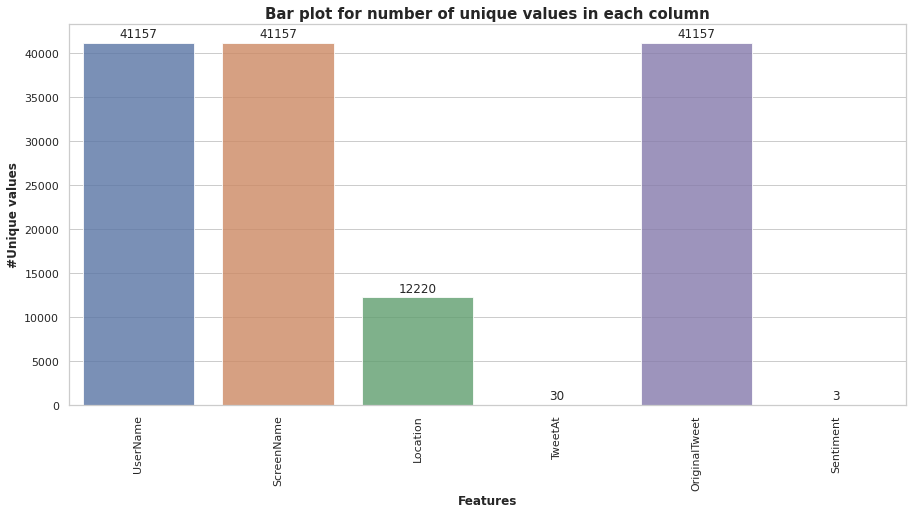
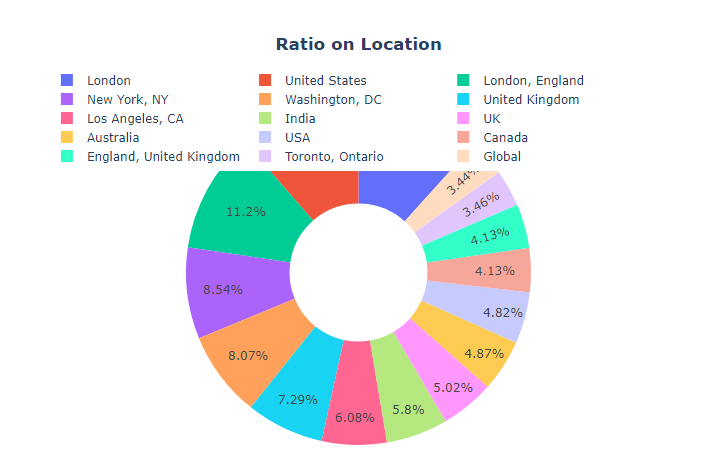
There are some null values in the location column but we don’t need to deal with them as we are just going to use two columns i.e. “Sentiment” and “Original Tweet”. Maximum tweets came from London(11.7%) location as evident from the following figure.
There are some words like ‘coronavirus’, ‘grocery store’, having the maximum frequency in our dataset. We can see it from the following word cloud. There are various #hashtags in the tweets column. But they are almost the same in all sentiments hence they are not giving us meaningful full information.
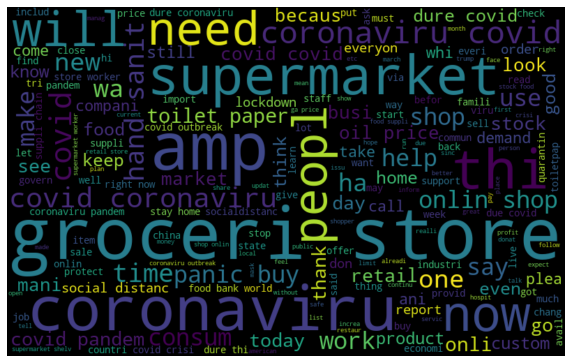
World Cloud showing the words having a maximum frequency in our Tweet column
When we try to explore the ‘Sentiment’ column, we came to know that most of the peoples are having positive sentiments about various issues shows us their optimism during pandemic times. Very few people are having extremely negatives thoughts about Covid-19.
Data Pre-processing
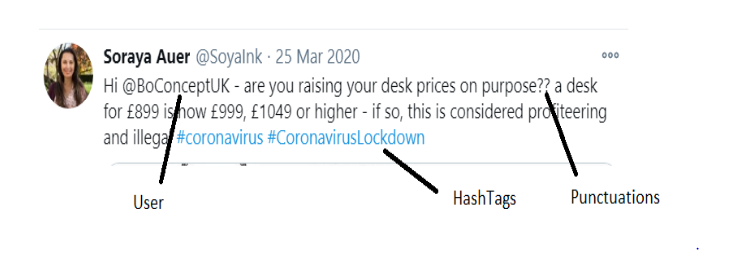
The preprocessing of the text data is an essential step as it makes the raw text ready for mining. The objective of this step is to clean noise those are less relevant to find the sentiment of tweets such as punctuation(.,?,” etc.), special characters(@,%,&,$, etc.), numbers(1,2,3, etc.), tweeter handle, links(HTTPS: / HTTP:)and terms which don’t carry much weightage in context to the text.
Also, we need to remove stop words from tweets. Stop words are those words in natural language that have very little meaning, such as “is”, “an”, “the”, etc. To remove stop words from a sentence, you can divide your text into words and then remove the word if it exists in the list of stop words provided by NLTK.
Then we need to normalize tweets by using Stemming or Lemmatization. “Stemming” is a rule-based process of stripping the suffixes (“ing”, “ly”, “es”, “ed”, “s” etc) from a word. For example — “play”, “player”, “played”, “plays” and “playing” are the different variations of the word — “play”.

Stemming will not convert original words into meaningful words. As you can see “considered” gets stemmed into “condit” which does not have meaning and a spelling mistake too. The better way is to use Lemmatization instead of stemming process.
Lemmatization is a more powerful operation, and it takes into consideration the morphological analysis of the words. It returns the lemma which is the base form of all its inflectional forms.

Here in the Lemmatization process, we are converting the word “raising” to its basic form “raise”. We also need to convert all tweets into the lower case before we do the normalization process.
We can include the process of tokenization. In tokenization, we convert a group of sentences into tokens. It is also called text segmentation or lexical analysis. It is basically splitting data into a small chunk of words. Tokenization in python can be done by the python NLTK library’s word_tokenize() function.
Vectorization
We can use a count vectorizer or a TF-IDF vectorizer. Count Vectorizer will create a sparse matrix of all words and the number of times they are present in a document.
TFIDF, short for term frequency-inverse document frequency, is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus. The TF–IDF value increases proportionally to the number of times a word appears in the document and is offset by the number of documents in the corpus that contain the word, which helps to adjust for the fact that some words appear more frequently in general. (wiki)
Building Classification Models
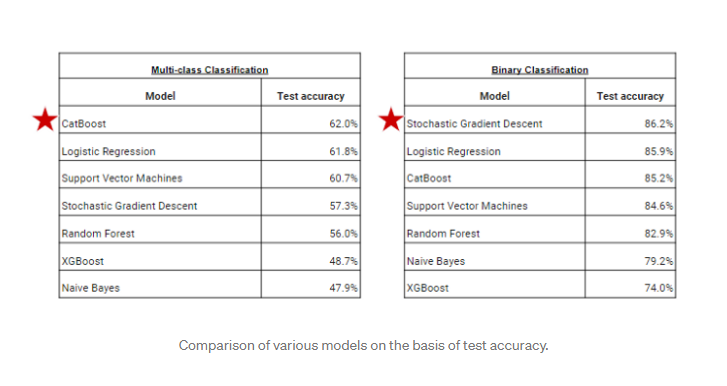
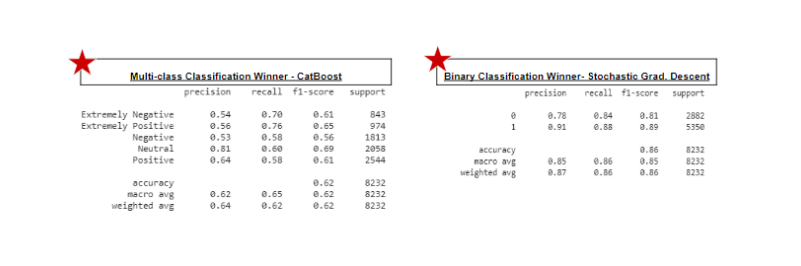
The given problem is Ordinal Multiclass classification. There are five types of sentiments so we have to train our models so that they can give us the correct label for the test dataset. I am going to built different models like Naive Bayes, Logistic Regression, Random Forest, XGBoost, Support Vector Machines, CatBoost, and Stochastic Gradient Descent.
I have used the given problem of Multiclass Classification that is dependent variable has the values -Positive, Extremely Positive, Neutral, Negative, Extremely Negative. I also convert this problem into binary classification i.e. I clubbed all tweets into just two types Positive and Negative. You can also go for three-class classification i.e. Positive, Negative and Neutral in order to achieve greater accuracy. In the evaluation phase, we will be comparing the results of these algorithms.
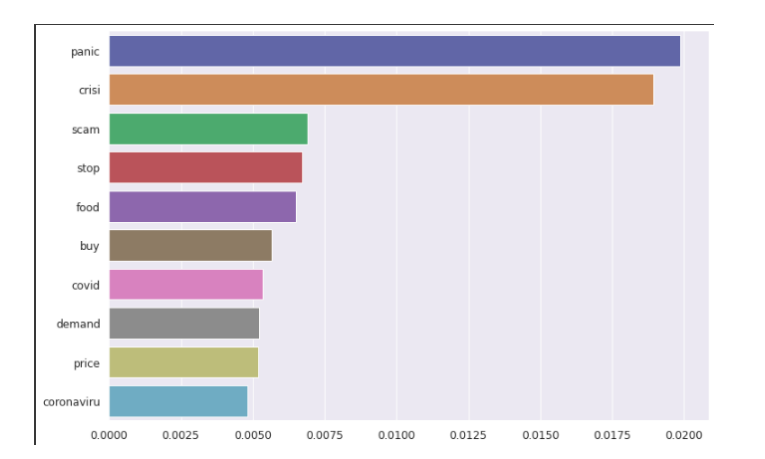
Feature Importance
The feature importance (variable importance) describes which features are relevant. It can help with a better understanding of the solved problem and sometimes lead to model improvements by employing feature selection. The top three important feature words are panic, crisis, and scam as we can see from the following graph.
Conclusion
In this way, we can explore more from various textual data and tweets. Our models will try to predict the various sentiments correctly. I have used various models for training our dataset but some models show greater accuracy while some do not. For multiclass classification, the best model for this dataset would be CatBoost. For binary classification, the best model for this dataset would be Stochastic Gradient Descent.
( You can access the python code of this project from this link-https://github.com/rajeshmore1/Capstone-Project-2 )
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.






Very elaborate analysis of COVID tweets. Kudos for pulling off such an interesting project!
Great work. Very much helpful keep it up...
Nice Article. Sentiment Analysis is a powerful tool.